- The paper presents AnytimeReasoner, which enhances reasoning efficiency by sampling token budgets and using dense rewards for improved credit assignment.
- It introduces a decoupled optimization strategy for thinking and summary policies, leading to better performance even with incomplete reasoning processes.
- Experimental evaluations show that BRPO reduces variance and outperforms traditional RL methods, demonstrating robust performance under diverse computational constraints.
Optimizing Anytime Reasoning via Budget Relative Policy Optimization
The paper "Optimizing Anytime Reasoning via Budget Relative Policy Optimization" explores a novel framework aimed at enhancing the efficiency and flexibility of reasoning in LLMs under varying token budget constraints. Through the introduction of field of RL and dense rewards, the authors pave the way for a highly efficient anytime reasoning framework.
Introduction
Traditional approaches leveraging RL focus on optimizing final performance under large token budgets, which can be computationally expensive and inefficient for online services. This paper proposes the AnytimeReasoner framework, which samples reasoning processes from prior distributions of token budgets. By truncating these processes, the model is forced to summarize actionable insights even with limited computational resources, thereby introducing verifiable dense rewards to facilitate effective credit assignment during RL optimization.
Sampling thinking budgets from a prior distribution allows AnytimeReasoner to improve token efficiency and accommodate interruptions during computation—a necessity for the robust handling of varying workloads in real-world scenarios.
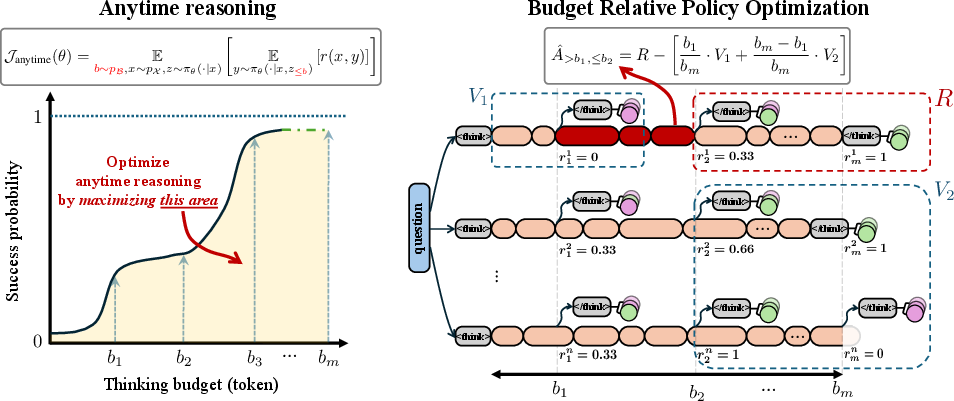
Figure 1: We optimize anytime reasoning by sampling thinking budgets from a prior distribution pB.
Methodological Framework
Decoupled Optimization
The authors introduce a decoupled optimization strategy for the thinking and summary policies to enhance training efficiency. By using different budget distributions for thinking and summary, the summary policy can independently be improved to deliver better performance for incomplete reasoning processes.
This presents the model with dense rewards at various sampling points, which aids in better criterion evaluation and allows for localizing and capitalizing on tokens that culminate in successful reasoning.

Figure 2: By introducing dense rewards, better credit assignment during RL training is achieved.
Budget Relative Policy Optimization (BRPO)
The proposed BRPO technique plays a pivotal role in reducing variance and improving robustness. By computing the advantage function using prior scores, BRPO enhances training stability and efficiency over previous methods like GRPO. The combination of prior scores with discounted future returns offers a promising avenue to reduce variance more effectively.
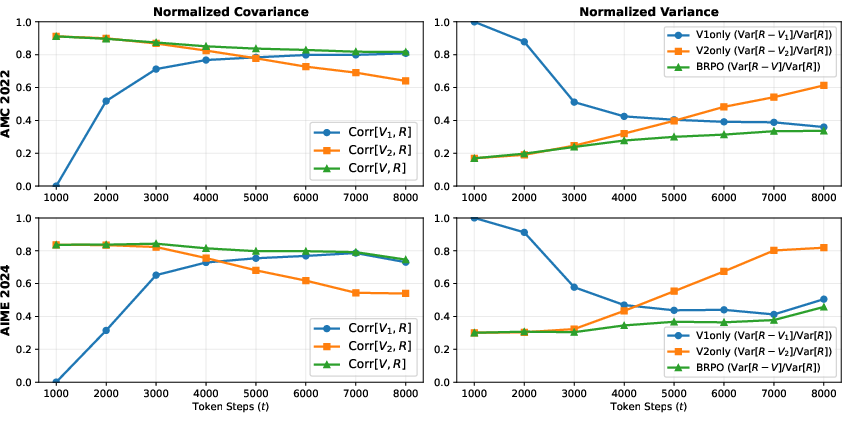
Figure 3: The correlation coefficient of V1 and V2 with R(x,z,jt).
Experimental Evaluation
Empirical evidence substantiates the claims that AnytimeReasoner consistently outperforms state-of-the-art methods like GRPO across all evaluated scenarios. Extensive ablation studies corroborate the significance of dense rewards, variance reduction, and decoupled optimization in driving the observed performance improvements.
Notably, AnytimeReasoner demonstrates remarkable resilience even under conditions that strictly focus on optimizing maximum token budgets, showcasing its potential for real-world deployment where operating constraints can vary significantly.
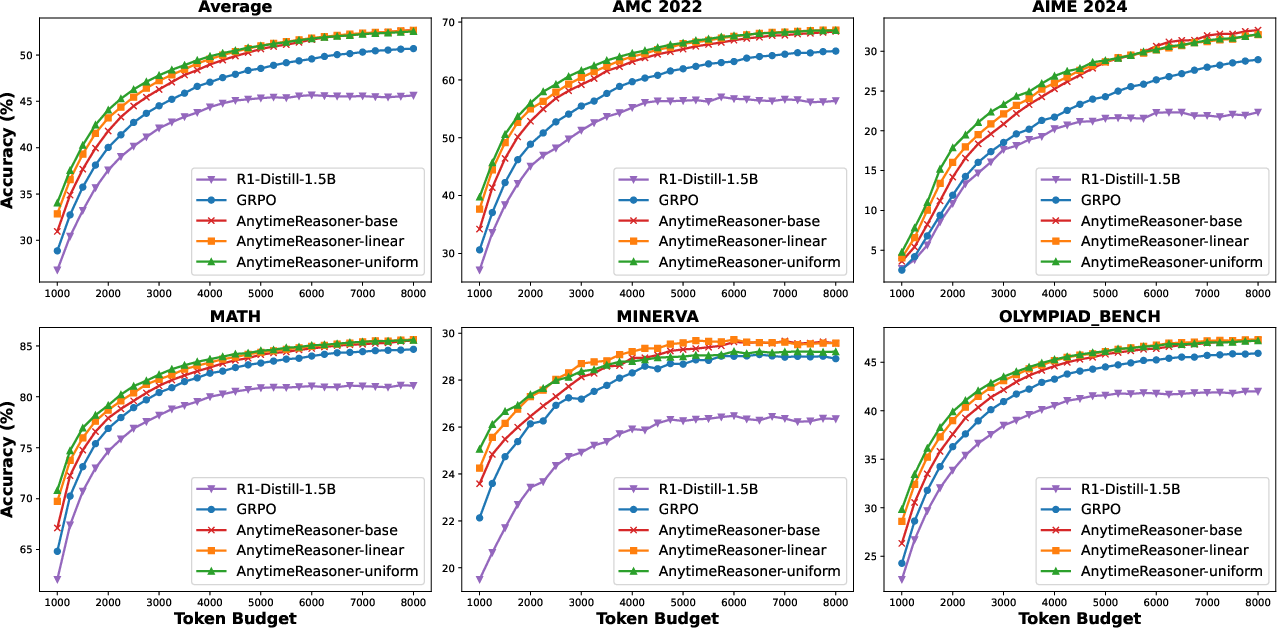
Figure 4: The comparison of anytime reasoning performance between GRPO and AnytimeReasoner.
Conclusion
By sampling prior token budgets and employing dense rewards, the AnytimeReasoner framework significantly contributes to advancing token efficiency in reasoning systems. The methodological advances, especially in variance reduction and credit assignment, present a robust alternative to traditional RL models.
Future developments might expand this framework to integrate adaptive learning mechanisms tailored for dynamic thinking budgets, promising enhanced LLM capabilities across varying computational constraints.
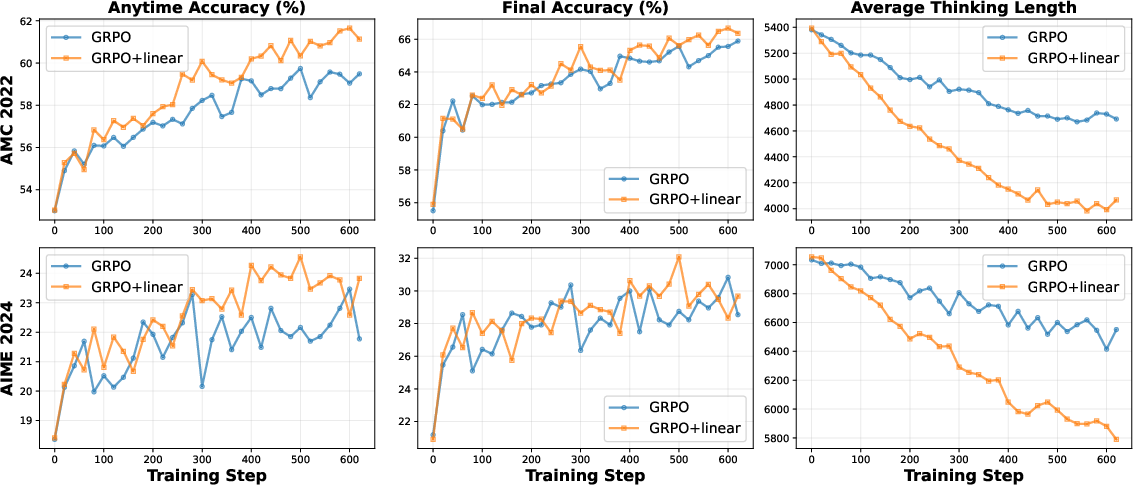
Figure 5: Ablation on verifiable dense rewards.
The insights gathered from this paper lay down essential groundwork for scalable and efficient LLM deployments, particularly where computations might be interrupted or limited by practical resource constraints.