- The paper introduces a scalable flow-matching decision pre-trained transformer that leverages Bayesian posterior sampling for handling multi-modal, high-dimensional action distributions.
- It employs a 928M-parameter TinyLLaMA backbone and a flow-based policy head to achieve robust multi-domain generalization over 209 tasks spanning 10 diverse environments.
- Experimental results highlight significant zero-shot adaptation and improved normalized returns on unseen tasks, setting a new benchmark for in-context RL performance.
Vintix II: A Scalable Flow-Matching Decision Pre-Trained Transformer for In-Context Reinforcement Learning
Introduction
The Vintix II architecture addresses the ongoing challenge of scaling in-context reinforcement learning (ICRL) to obtain generalist agents capable of rapidly adapting to novel tasks and environments at inference. Classic ICRL approaches, such as Algorithm Distillation (AD) and Decision Pre-Trained Transformer (DPT), have demonstrated in-context learning (ICL) in constrained or discrete domains but suffer from limited generalization in large, continuous, and diverse task sets. Vintix II advances the state-of-the-art in parametric ICRL by (1) extending the DPT framework to multi-domain, continuous-action environments, and (2) integrating a flow-based policy head optimized via rectified flow matching for fully Bayesian in-context posterior sampling over actions.
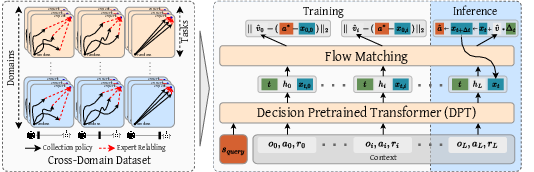
Figure 1: Overview of the approach—multi-domain dataset collection by noise-distillation, flow-matching policy learning, and flow-based inference via ODE integration.
Methodology
Dataset and Multi-Domain Generalization
The training corpus exceeds 700M state-action-reward tuples spanning 209 tasks over 10 domains, encompassing classic continuous control (MuJoCo), high-DOF bimanual manipulation (Bi-DexHands), robotic meta-learning (Meta-World), 2D procedural physics (Kinetix), energy grid optimization (CityLearn, SinerGym), PDE control (ControlGym), and complex autonomous driving (MetaDrive). Context-based task inference is enforced by grouped encoder/decoder modularization; each action-observation structure shares a tied MLP, and embedding spaces are standardized via group assignment. Importantly, a strict disjointness between train and hold-out sets (46 tasks) enables a non-trivial evaluation of zero-shot transfer and demonstration-augmented adaptation.
Architecture
The backbone is a 928M-parameter causal transformer (TinyLLaMA variant: 16 layers, 24 attention heads, 1536d embedding, 4096-token context, no positional encoding). The key architectural innovation is the replacement of weakly expressive Gaussian heads with a flow-based action head parametrizing a context-conditional vector field (rectified flow matching). This model allows native generation of multi-modal, heteroscedastic, and high-dimensional action distributions, suitable for domains where naive unimodal approximators fail. Temporal conditioning is injected through learnable sinusoidal embeddings.
Training and Flow Matching
Given a demonstration-augmented context of (obs,action,reward) tokens and a query observation, the transformer encodes the sequence jointly. The flow-based head is trained via the rectified flow objective, transporting simple base Gaussians to the optimal action distribution via ODE integration. This process preserves theoretical alignment with Bayesian posterior sampling, in contrast to likelihood-mismatched MSE- or Gaussian-based DPT heads. Training is conducted with full-batch Adam, gradient clipping, and bf16 precision.
Inference
At deployment, actions are decoded by sampling base noise and integrating through the vector field head, using Heun's method for ODE approximation. Two operational regimes are supported:
- Online: context is incrementally built from agent interaction with the environment.
- Offline: context consists of a fixed set of expert demonstrations.
Context lengths are capped by transformer size, with typical experimental settings of 2500–4096 transitions.
Experimental Results
Train and Generalization Regimes
On 209 training tasks, Vintix II reaches near-demonstrator performance with zero context and demonstrates self-corrective online adaptation when context is accumulated, as reflected by monotonic improvement in normalized returns across all domains.
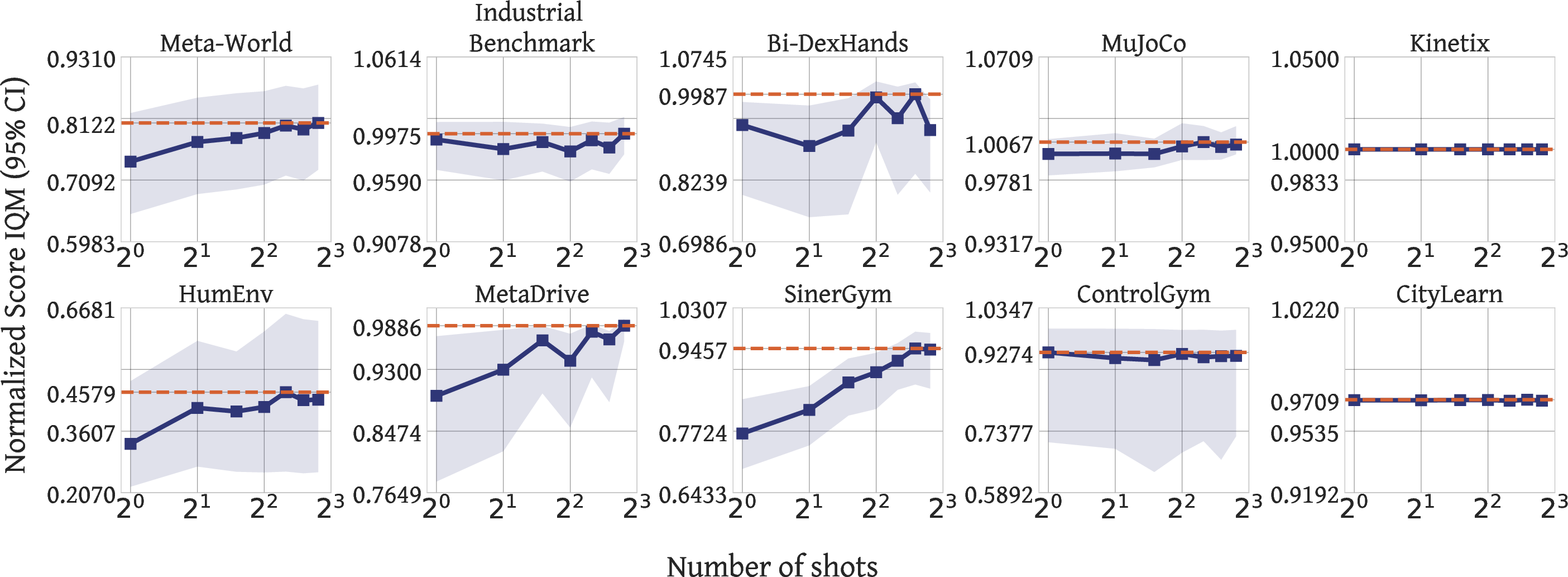
Figure 2: Episode-wise normalized returns during online inference—contextless start with rapid performance improvement.
By conditioning on 2500 expert transitions, Vintix II improves average normalized domain returns by +4.1%, with robust performance across all 10 domains, even when training baseline scores are already saturated.
Held-Out Generalization
On 46 unseen tasks, Vintix II achieves domain-level normalized returns above 75% of demonstrator performance in MetaDrive (102%), ControlGym (100%), SinerGym (92%), and CityLearn (78%). Gains relative to previous Large Action Models (Vintix, REGENT) are substantial, including +17% on Bi-DexHands (prompted), +4% on parametric MuJoCo, and +63% on Meta-World ML45 split.
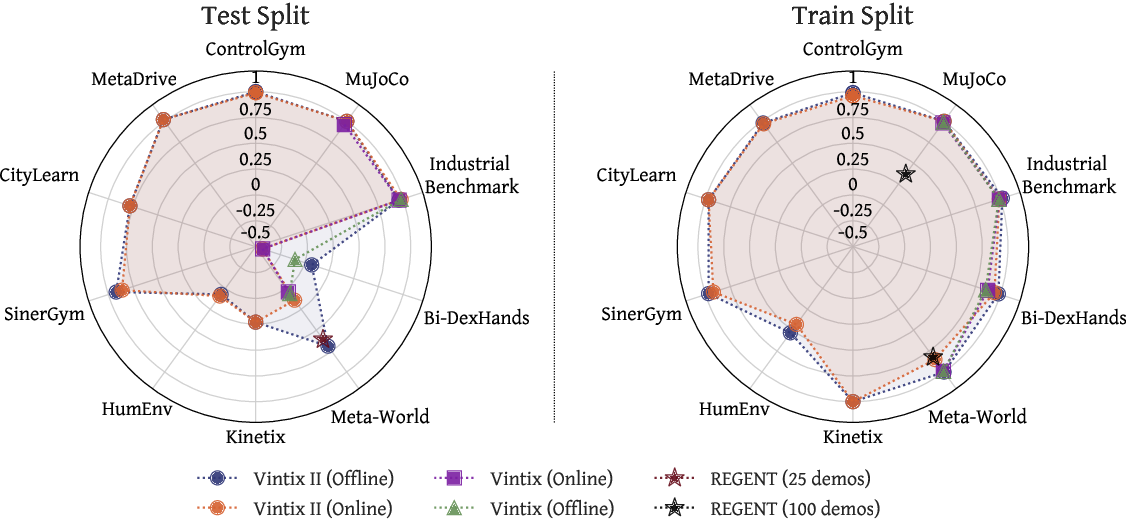
Figure 3: Domain-level normalized evaluation—left: unseen test tasks, right: train tasks. Vintix II outperforms prior action models, especially in generalization.
Remarkably, prompted Vintix II exhibits robust zero-shot behavior: with no demonstrations, cold-start performance for 8/10 domains matches the offline regime.
Posterior Sampling and Context Scaling
Ablations confirm that increasing context size tightens the induced action distribution (entropy decline), empirically aligning with in-context posterior sampling.
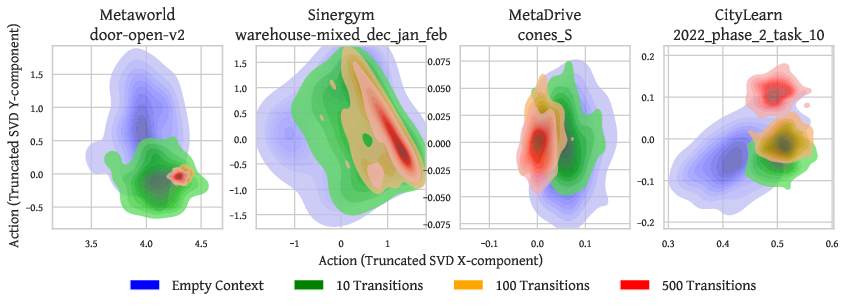
Figure 4: Action distribution contraction with increasing context size demonstrates effective posterior sampling.
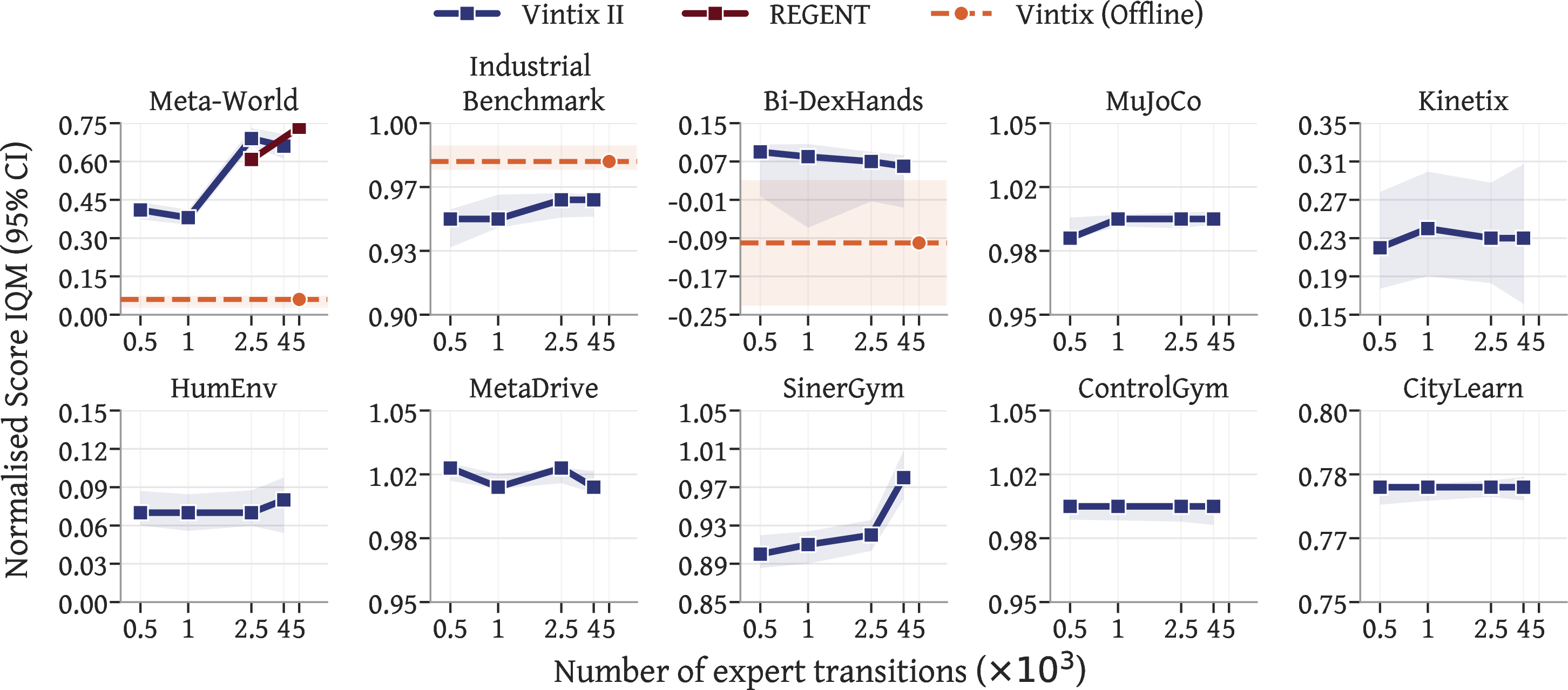
Figure 5: Normalized returns as a function of demonstration budget—performance scales monotonically with context size.
Additional visualizations across varied domains (Figures 6–9) solidify the generality of this phenomenon.
Design Choices and Ablations
Comparative ablations demonstrate:
- The flow matching head outperforms Gaussian heads on generalization, particularly in multi-modal or discontinuous reward domains.
- Multi-domain models consistently outperform or match single-domain ablations, validating inductive transfer and context-based modularization.
- When compared under equivalent demonstration budgets and architectures, Vintix II robustly outperforms Vintix on all domains (see appendix tables).
Implications and Future Work
Vintix II provides an unambiguous demonstration that scaling the DPT paradigm—by leveraging flow-matching action heads and expanding dataset/task diversity—yields strong ICRL agents functional in both zero-shot and demonstration-augmented regimes. The results underscore ICRL as a viable alternative to retrieval-based or vision-language-action modular generalists, simplifying inference deployment by removing non-parametric retrieval modules.
From a theoretical perspective, flow-based DPT realizes in-context Bayesian posterior sampling, resulting in robust adaptation and improved exploration-exploitation trade-offs. Practically, parametric generalist agents of this sort open the path toward cross-domain transfer and universal large action models suitable for robotics, control, and complex real-world systems—provided that dataset and backbone scale continues to increase.
The major bottleneck remains: the token-to-parameter data regime is sub-optimal (currently <1), suggesting significant gains remain in the overparameterized/data-rich regime (cf. “Chinchilla scaling laws”). Furthermore, dimension-agnostic action/observation handling for truly arbitrary task generalization is still unresolved, as is the demonstration-less exploration ability of current ICRL models.
Conclusion
Vintix II demonstrates that the combination of flow-matching policy heads and large-scale, multi-domain DPT backbones enables previously unattained levels of generalization for in-context RL agents, establishing a new benchmark for parametric Large Action Models. It supports both exploitative demonstration matching and online adaptive policy improvement, delivering strong empirical results across robotic control, simulation, planning, and real-world control domains. Future progress will critically depend on further expansion of datasets and continued investigation into model scaling and invariance—essential steps toward universal action models supporting robust zero-shot and in-context adaptation.

