- The paper presents DynLMC, which decomposes multivariate processes into dynamically mixed latent Gaussian processes to capture smooth drift, regime shifts, and lagged dependencies.
- It leverages autoregressive drift and HMM-based regime switches to simulate realistic, evolving inter-channel relationships, enhancing synthetic data realism.
- Experimental evaluations show that DynLMC-enhanced pretraining boosts zero-shot forecasting performance on diverse real-world time series benchmarks.
Dynamic Linear Coregionalization for Realistic Synthetic Multivariate Time Series
Introduction and Motivation
Synthetic data generation is a key enabler for the development and pretraining of foundation models for time series (FMTS). While existing synthetic generators for multivariate time series, e.g., KernelSynth (Chronos) and LMCSynth (TimePFN), provide useful priors for forecasting, they are limited by their static treatment of inter-channel dependencies. Specifically, these approaches generate either independent or instantaneously correlated channels, failing to capture the temporal evolution, regime shifts, and lagged interactions intrinsic to real-world multivariate systems observed in domains such as finance, climate, and energy. Empirical analysis in the paper highlights that both cross-channel correlation drift and lagged dependencies are significantly more pronounced and dynamic in real datasets than those generated by the static Linear Model of Coregionalization (LMC).
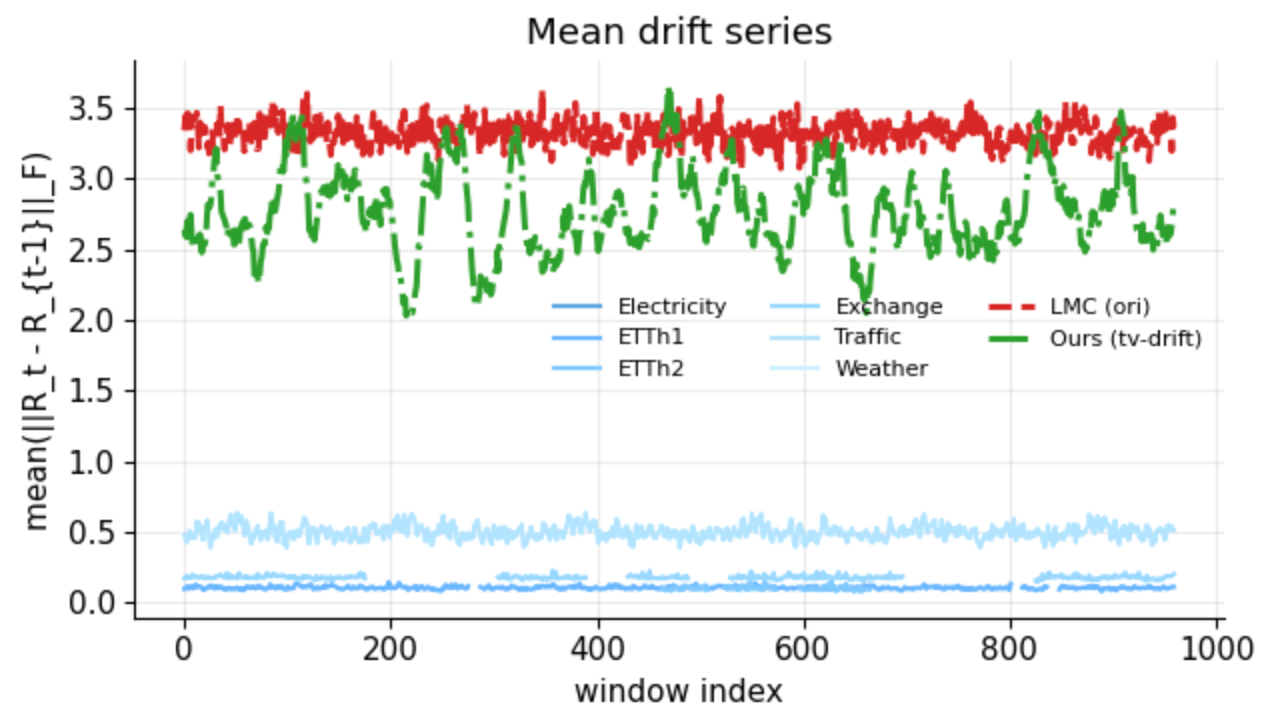
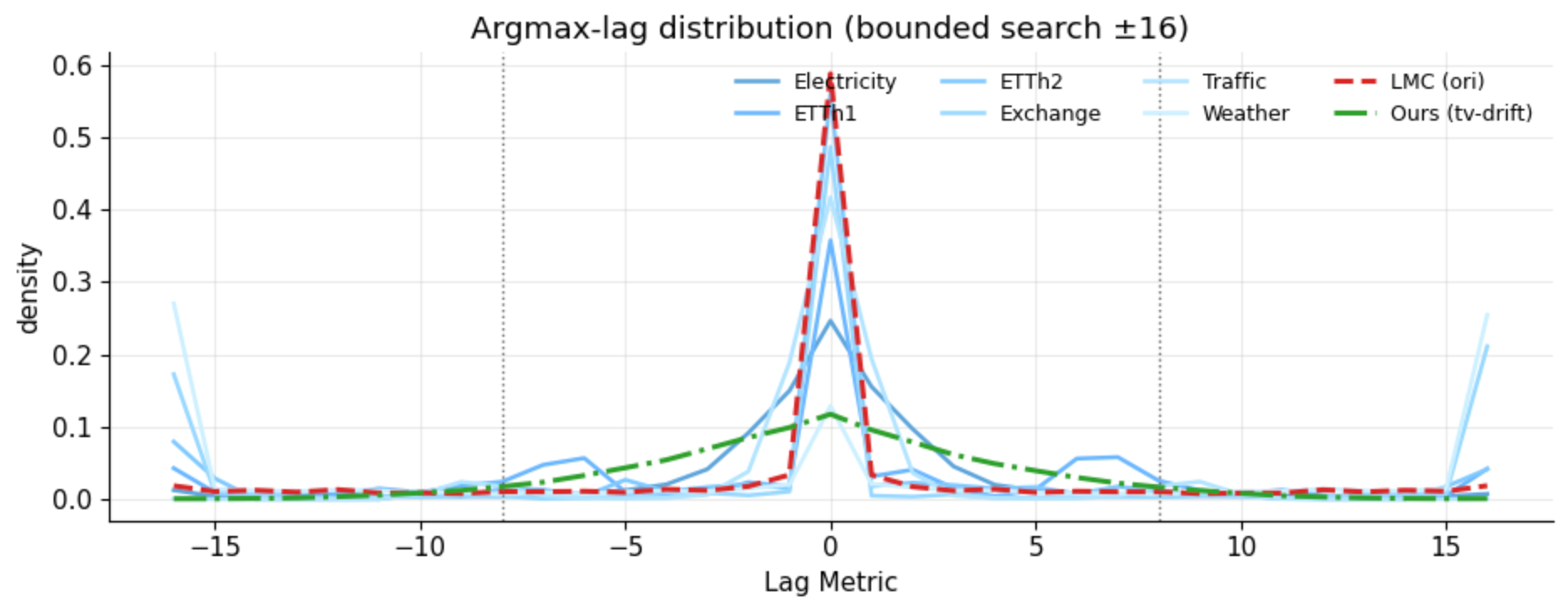
Figure 1: Left: Real-world data shows stronger time-varying correlation drift than static synthetic generators; right: Argmax-lag distributions emphasize the underrepresentation of cross-channel delays in traditional generators.
The DynLMC Model
DynLMC extends the LMC paradigm by decomposing the observed multivariate process into dynamically mixed latent Gaussian processes (GPs) with time-varying coefficients and explicit lag structure. For each channel i, the observed value at time t is computed as:
Ci(t)=j=1∑Lαi,j(t)lj(t−τi,j)
where:
- lj are latent GPs of diverse kernel compositions.
- αi,j(t) are dynamic mixing weights, evolving either via autoregressive (AR) drift or discrete regime switching.
- τi,j are integer lags drawn from a pre-specified range, inducing structured lead-lag dependencies.
This parameterization enables three classes of nonstationarity in synthetic time series:
- Smooth Correlation Drift: Autoregressive evolution of weights imposes slow or fast-changing correlation regimes.
- Discrete Regime Switching: Hidden Markov Model-driven switching yields abrupt, interpretable shifts in cross-channel dependency structure.
- Lagged Dependencies: Structured temporal offsets between latent and observed channels generate realistic causal patterns.
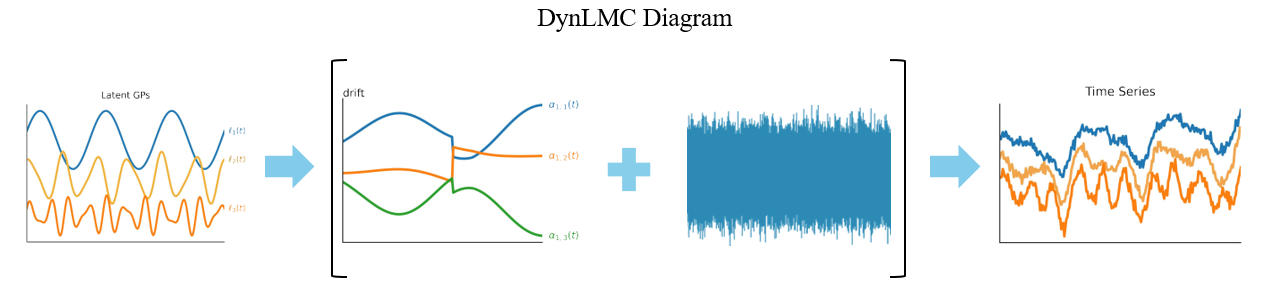
Figure 2: Schematic of DynLMC generation, where inter-channel relationships evolve over time, capturing both smooth drift and sudden regime shifts.
Experimental Evaluation
Synthetic Data Generation
The DynLMC framework enables generation of rich, large-scale synthetic datasets reflecting realistic multivariate temporal structures at scale (e.g., 1,500 sequences, 160 variables, 1,024 timesteps/sample). Variants include isolated drift, lag, and regime shift, as well as combined mixtures with naive and Bayesian-optimized weights. The generator’s code is made available and readily integrates into standard foundation model pipelines.
Downstream Forecasting: Zero-Shot and Fine-Tuning
The empirical study benchmarks three FMTS backbones—TimePFN, iTransformer, and Chronos-2—each fine-tuned on DynLMC-generated data. The evaluation spans nine diverse real-world benchmarks: ECL, ETTh1/2, ETTm1/2, Exchange, Solar, Traffic, and Weather.
Results
- For TimePFN and iTransformer, DynLMC fine-tuning consistently improves zero-shot MAE on real datasets. Notably, Combined and Regime Shift variants yield the greatest number of test set wins, with improvements particularly strong in highly multivariate settings (ECL, Traffic, Weather).
- Chronos-2 exhibits smaller—but still positive—marginal gains. The limited improvement is attributed to its pretraining already including synthetic multivariate data with evolving dependencies, underscoring the diminishing returns when such structure is already present.
- Bayesian-optimized synthetic data mixtures confer additional improvements in several settings over naive mixing, highlighting the utility of data-centric generative optimization for maximizing downstream performance.
Implications
DynLMC concretely demonstrates that modelling dynamic, nonstationary inter-variable dependencies in synthetic multivariate time series is critical for realistic pretraining of FMTS. Enhanced synthetic realism directly translates to more robust, transferable, and annotation-efficient foundation models, improving adaptation in low-resource and distributionally-shifted scenarios. The Bayesian optimization strategy for mixture generation further indicates that the utility of synthetic data can be actively maximized by tailoring the data distribution to specific downstream tasks.
Practically, these findings advocate for the use of dynamic synthetic data engines—such as DynLMC—in time series model pretraining pipelines, especially as FMTS methods are scaled to increasingly complex or privacy-sensitive domains. Theoretically, DynLMC provides a formal link between the statistical properties of synthetic data and the out-of-distribution generalization of neural forecast architectures. Future research could extend DynLMC with additional nonstationarities, hierarchical or graph-based dependencies, and automated generator adaptation via feedback from downstream validation.
Conclusion
DynLMC advances the state of the art in synthetic multivariate time series generation, bridging the realism gap between static synthetic data and real-world signals by modeling smooth drift, regime shifts, and lagged dependencies. Empirical analyses show robust, consistent improvements in FMTS performance after fine-tuning on DynLMC data, emphasizing the importance of realistic inter-channel dynamics for transferable foundation models. The framework lays the groundwork for more sophisticated, task-adaptive, and data-centric synthetic pretraining approaches for time series AI.

