- The paper introduces a dynamic parameter adaptation pipeline that leverages SNG and DPP to enhance 3D scene semantic segmentation.
- It achieves a state-of-the-art mIoU of 78.4% on ScanNet validation with only a negligible increase in parameters (≤2%).
- The method demonstrates robust performance across diverse scenes, significantly improving efficiency and handling geometric complexity.
PointTPA: Dynamic Network Parameter Adaptation for 3D Scene Understanding
Motivation and Problem Analysis
Point cloud-based scene understanding underlies many advanced AI applications such as embodied intelligence and autonomous driving but faces unique challenges at the scene-level, including high geometric complexity, severely imbalanced point distributions, and substantial spatial heterogeneity. While recent advances in transformer-based point cloud models and large-scale self-supervised pretraining have boosted object-level performance, transfer to large-scale 3D scenes remains suboptimal. Existing PEFT (parameter-efficient fine-tuning) methods in the point cloud domain primarily focus on object-level adaptation, offering static parameter modulation during inference. These static approaches lack sufficient representation plasticity to handle the diversity of real-world scenes, leading to a persistent performance gap between object-level and scene-level point cloud understanding.
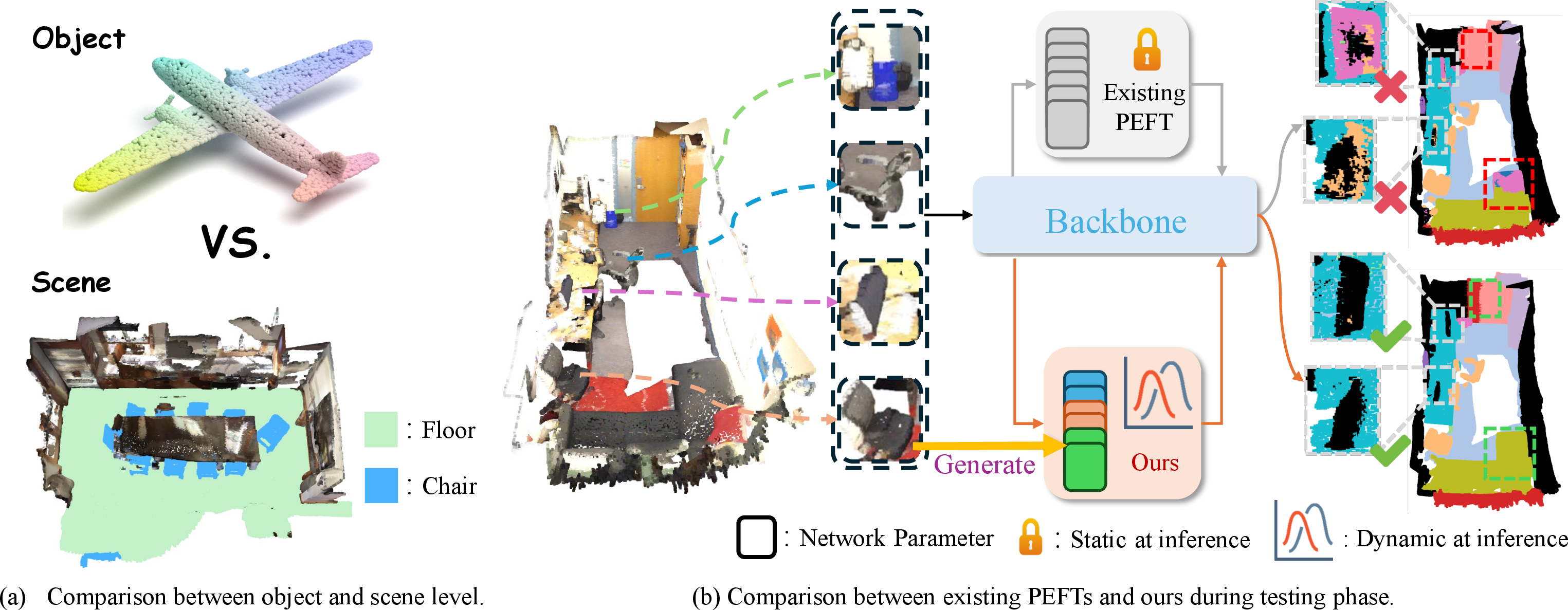
Figure 1: Scene-level point clouds feature increased complexity and category imbalance; unlike static PEFT, PointTPA deploys dynamic projection weights for improved 3D semantic segmentation.
Methodology
Architecture Overview
PointTPA introduces a dynamic parameter adaptation pipeline for scene-level point clouds, realized through two key architectural modules:
- Serialization-based Neighborhood Grouping (SNG): SNG serializes unordered 3D points using spatially coherent space-filling curves (e.g., Hilbert and Z-order), organizing the point set into local groups or patches that preserve underlying geometric locality.
- Dynamic Parameter Projector (DPP): DPP maps each input patch, via a group-level feature extractor, to a set of “routing coefficients” used to linearly combine trainable base weights (“parameter base set”), generating input-dependent dynamic projection weights per patch at inference.
During training, the backbone is frozen and only the lightweight DPP and static adapters are updated, following the standard PEFT paradigm but introducing dynamicity at inference.
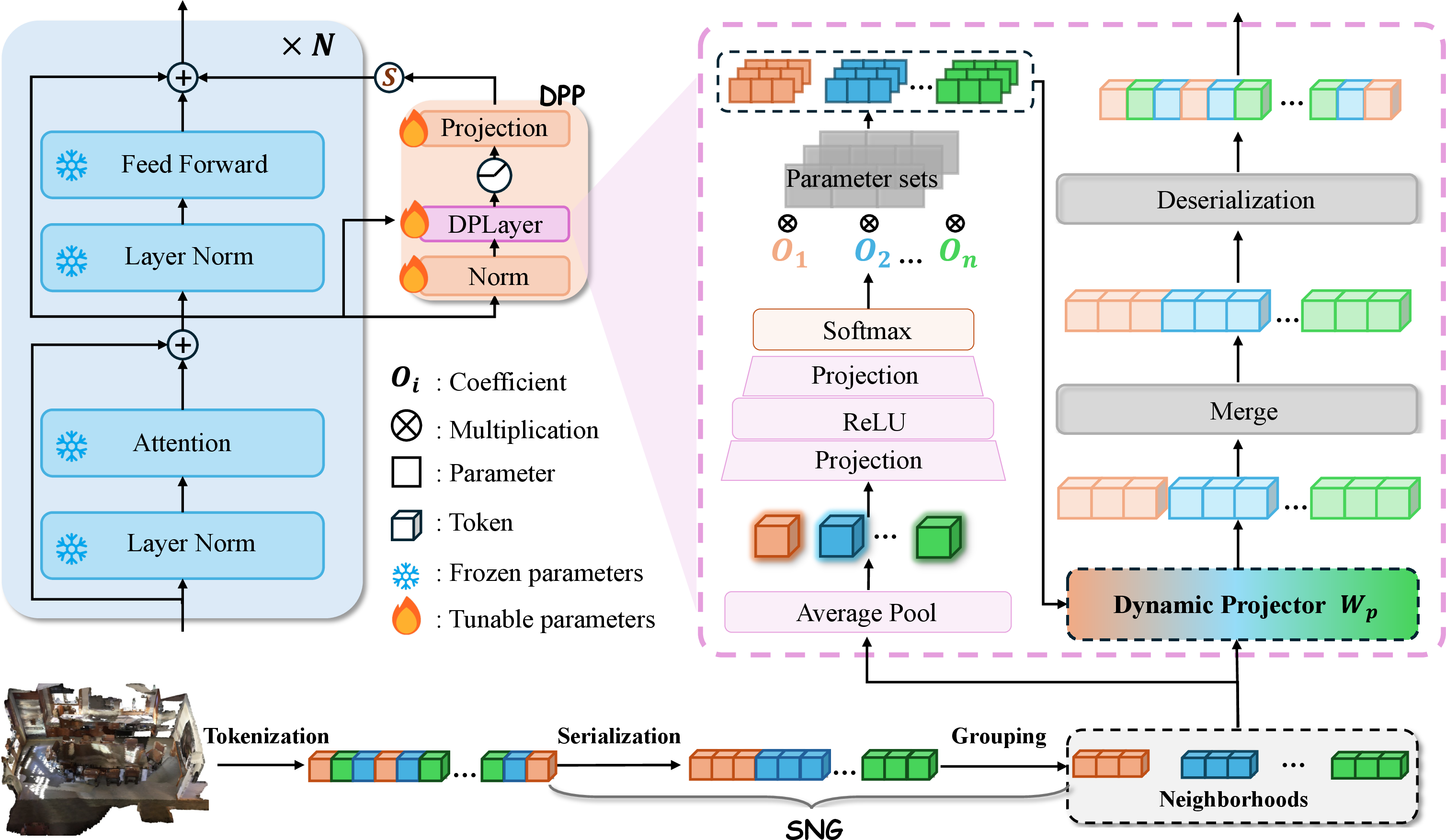
Figure 2: Overview of PointTPA, highlighting (left) SNG-based patching and (right) DPP’s input-adaptive dynamic weight generation.
Mixed-Insertion Strategy
To avoid over-parameterization and maintain computational efficiency, PointTPA adopts a mixed-insertion scheme, instantiating DPP only in the last block of each encoder stage, while preceding blocks utilize static adapters. This ensures that the bulk of computation benefits from dynamic context, while early-stage features maintain stability.
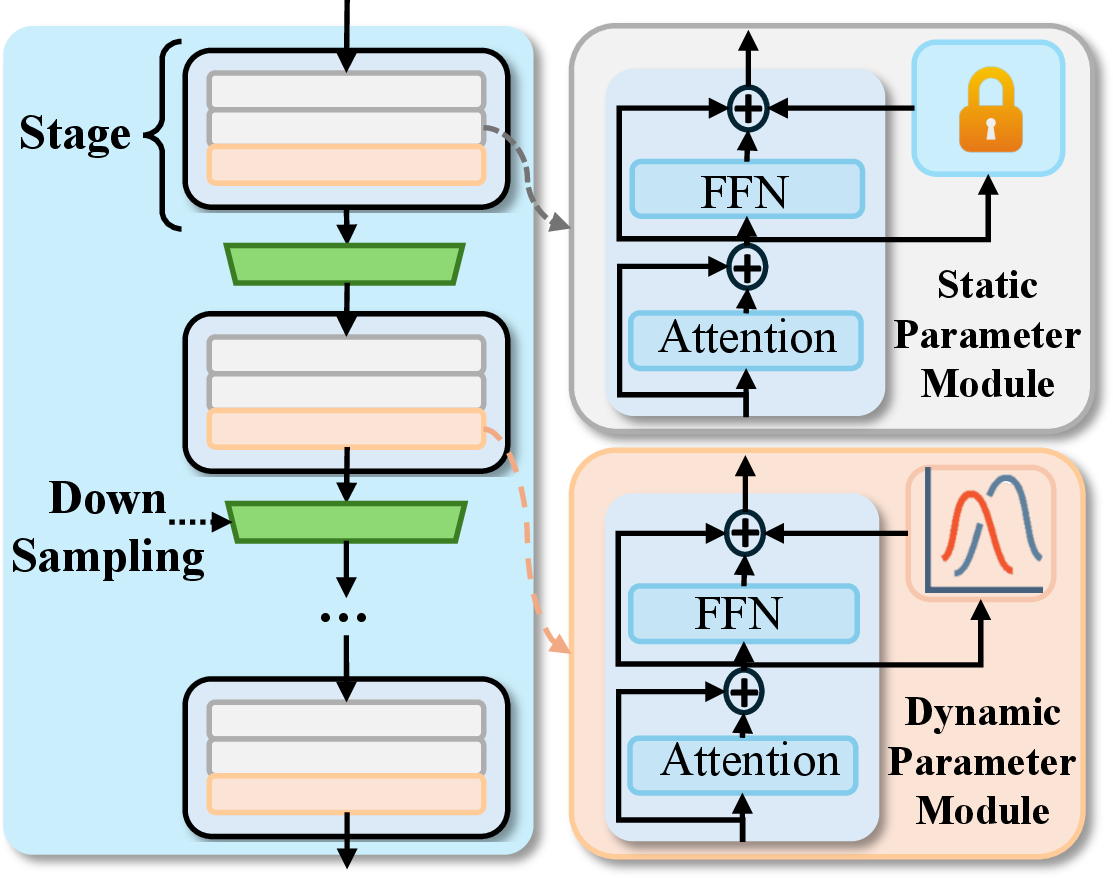
Figure 3: The mixed-insertion strategy: DPP is only applied to the last block in each stage, others use static adapters.
Empirical Results
Scene-Level Semantic Segmentation
Integrated with Point Transformer V3, PointTPA introduces a negligible parameter increase (≤2% of backbone parameters) but yields state-of-the-art mIoU of 78.4% on ScanNet validation, surpassing all prior PEFT methods and even approaching or slightly exceeding full fine-tuning (FFT) on several metrics. Noteworthy performance gains are observed in computational efficiency: compared to prior SOTA PointGST, PointTPA is approximately 4× faster during training and inference for similar accuracy, emphasizing a superior trade-off between efficiency and representational power.
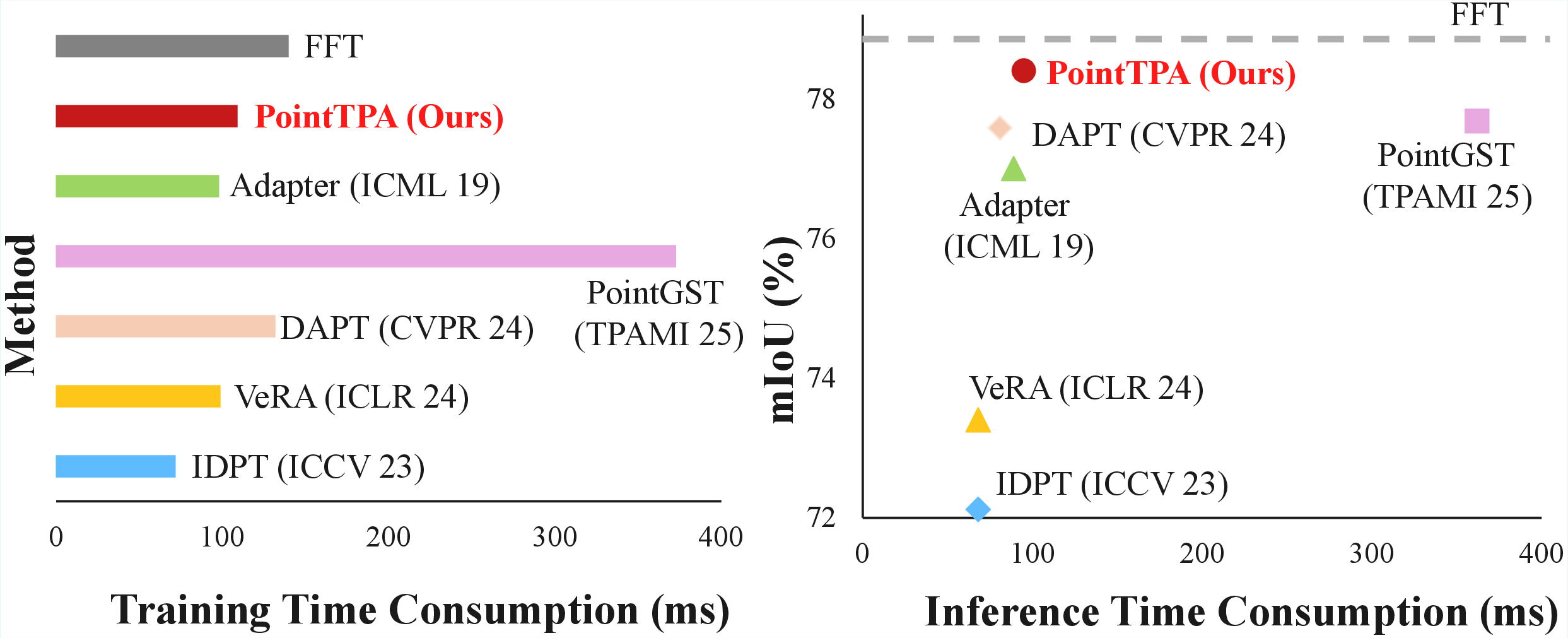
Figure 4: Training/inference time comparison for PEFT and FFT on ScanNet: PointTPA achieves optimal efficiency-accuracy balance.
Ablation studies confirm that both SNG and DPP are independently effective, but their combination yields maximal performance. Further, performance saturates with 4–8 parameter bases per stage; excessive bases degrade convergence. The optimal number of SNG groups is empirically determined (e.g., 200 at stage one), balancing locality with context richness.
Robustness and Qualitative Analysis
On challenging long-tail categories and fine-grained geometries, PointTPA demonstrates heightened robustness versus static PEFT methods such as IDPT, evidenced by visualizations showing more accurate segmentation of small objects and complex regions.
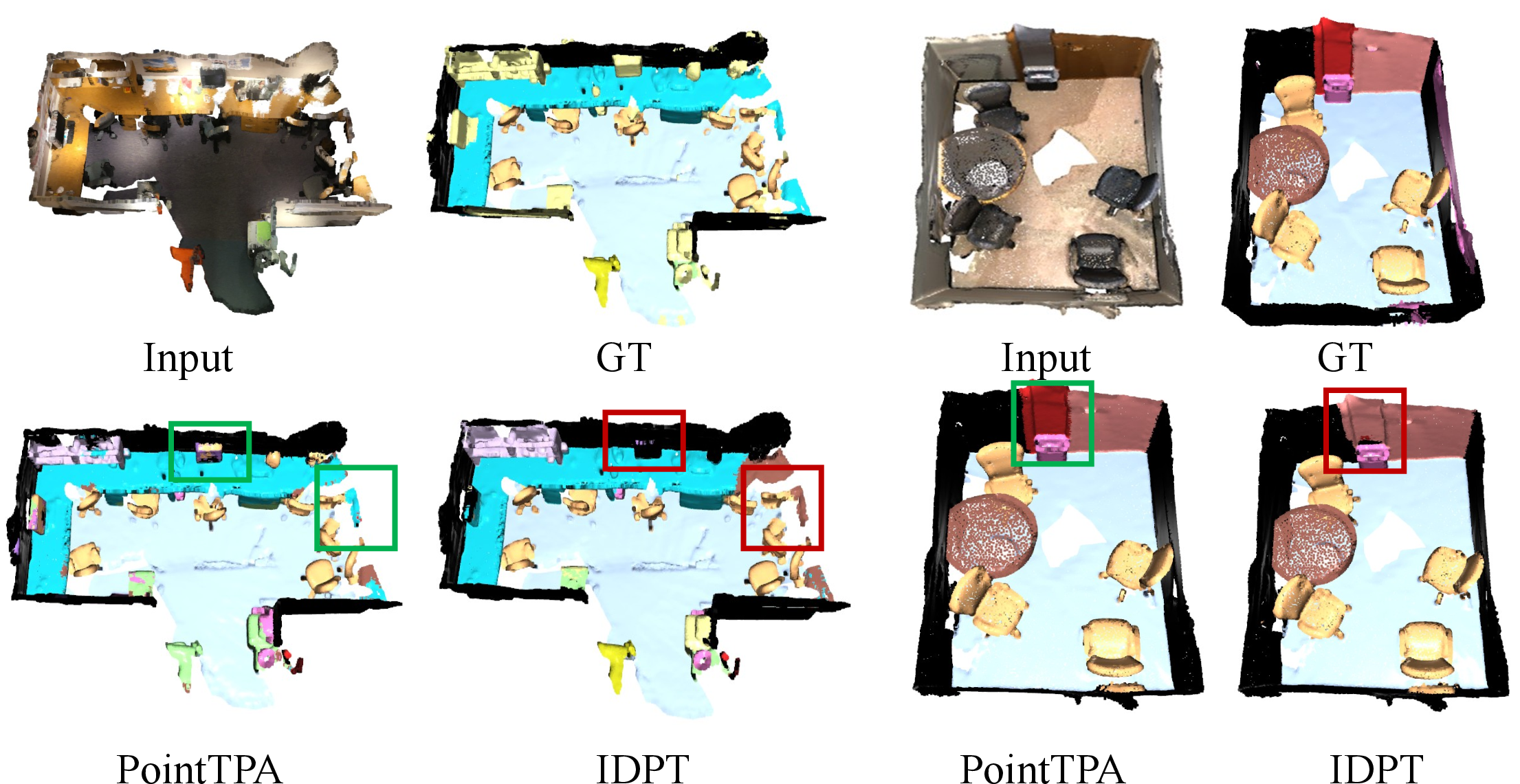
Figure 5: Qualitative segmentation—PointTPA recovers wall-adjacent and occluded objects (green: correct, red: incorrect).
Dynamic weight visualization further corroborates the context specificity of generated parameters—similarity heatmaps reveal that distinct patches receive highly diverse weights, indicative of true input awareness.

Figure 6: Within-scene similarity of dynamic weights illustrating high variance across token groups and network stages.
On expanded benchmarks such as ScanNet++, S3DIS, and ScanNet200, PointTPA holds or exceeds SOTA for mIoU and allAcc, confirming generalization to varied environments and finer-grained semantic categories.
Compared to generic vision PEFT techniques (BitFit, LoRA, Prefix, Adapters) and prior 3D-specific methods (IDPT, DAPT, PointGST), PointTPA delivers both higher numerical performance with minimal extra parameters, and stronger local adaptation especially under geometric and categorical imbalance. Unlike IDPT, which lacks context granularity for scene-level adaptation, PointTPA’s grouped parameterization allocates flexible model capacity according to spatial layout.
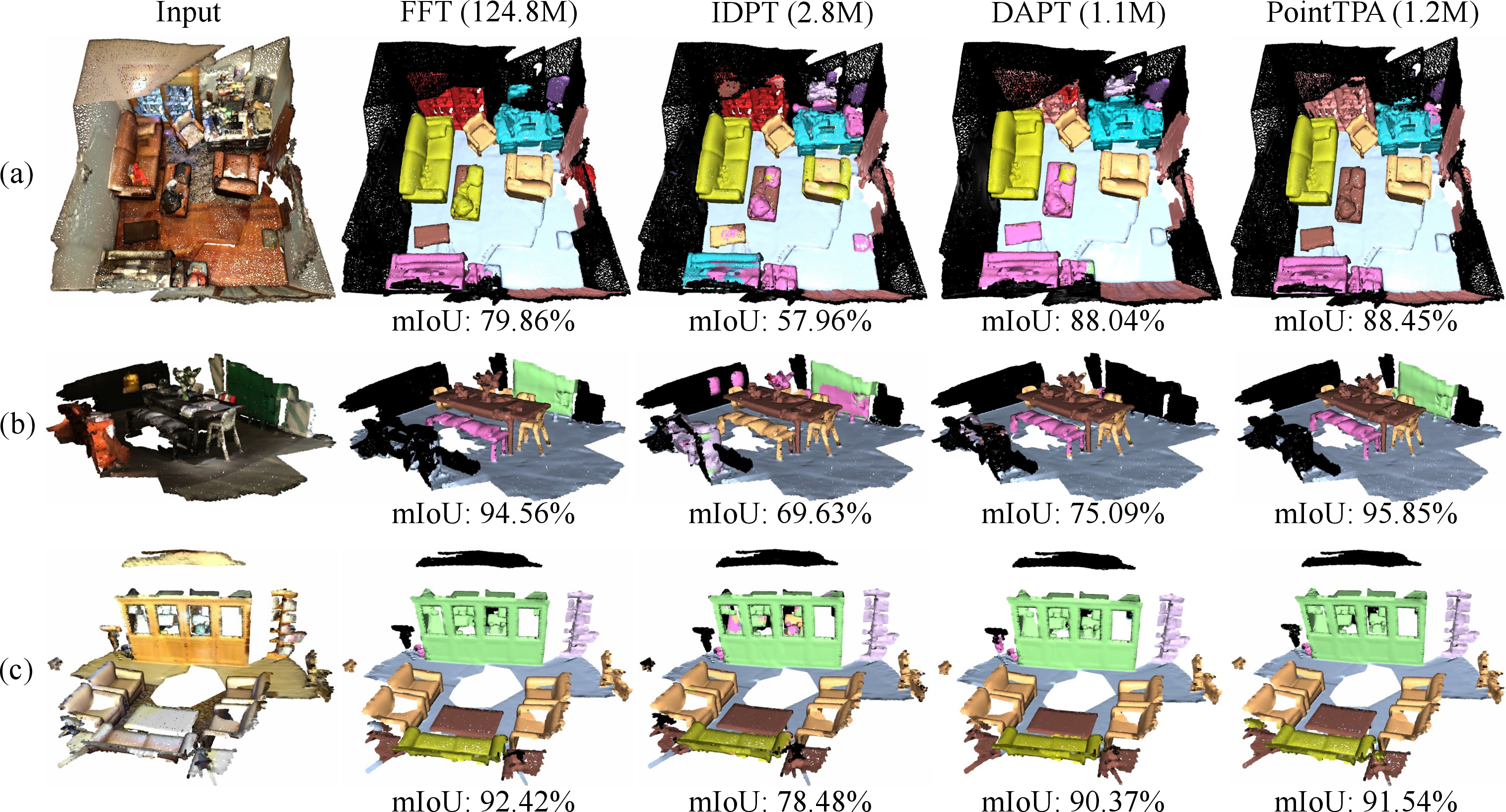
Figure 7: Segmentation output comparison with FFT, IDPT, DAPT, and PointTPA—PointTPA consistently aligns with FFT.
Implications and Future Directions
PointTPA demonstrates that dynamic parameter tuning at inference can substantially enhance PEFT pipelines for large-scale, heterogeneous 3D scene understanding. This approach raises new possibilities for hybrid models—e.g., integrating DPP with recent diffusion-based or generative point cloud architectures—or extending dynamic adaptation to multi-modal and open-vocabulary 3D perception. There is substantial potential in exploring dynamic parameterization for structural feature extraction, instance segmentation, or compositional scene decomposition, especially as real-world deployments continue to increase data complexity and diversity.

Figure 8: Multi-dataset segmentation outputs by PointTPA (ScanNet, ScanNet200, ScanNet++, S3DIS): consistent high-fidelity adaptation across scene types and viewpoints.
Conclusion
PointTPA establishes a new reference model for parameter-efficient 3D scene understanding by unifying input-aware dynamic weight generation with efficient adaptation. Its robust empirical performance, especially under challenging category-imbalanced and fine-grained segmentation regimes, highlights the importance of dynamic inference for next-generation 3D perception architectures. The framework’s design offers a template for future research on efficient, context-adaptive models across geometric and multi-modal AI domains.
Reference: "PointTPA: Dynamic Network Parameter Adaptation for 3D Scene Understanding" (2604.04933)