- The paper presents a novel PEFT method by statically selecting top-k weights per neuron with sparse additive bypasses, yielding significant memory savings.
- It employs offline top-k selection and sparse delta tensors to update only crucial parameters, reducing memory usage by up to 60% and computational overhead.
- Experiments on 23+ tasks demonstrate that NeuroAda outperforms prior approaches, achieving higher accuracy in commonsense and reasoning benchmarks.
NeuroAda: Activating Each Neuron's Potential for Parameter-Efficient Fine-Tuning
Introduction
NeuroAda introduces a novel paradigm for parameter-efficient fine-tuning (PEFT) in LLMs and transformer-based architectures. The method is motivated by the limitations of existing PEFT approaches, which either suffer from restricted representational capacity (addition-based methods) or incur substantial memory overhead (mask-based selective adaptation). NeuroAda reconciles these trade-offs by statically selecting top-k input connections per neuron and introducing sparse, additive bypass parameters, enabling fine-grained adaptation with minimal memory and computational cost.
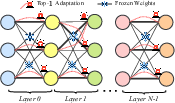
Figure 1: Overview of NeuroAda. For each neuron, top-1 weights are adapted, while the rest remain frozen. Bold dark indicates selected pretrained weights; red dashed edges represent newly introduced trainable parameters.
Methodology
Sparse Additive Adaptation
NeuroAda operates by freezing all pretrained model weights and introducing a sparse delta tensor Δ for adaptation. For each neuron (row in a weight matrix), the top-k highest-magnitude input connections are identified offline. Only these positions receive trainable bypass parameters, initialized to zero. The rest of the model remains untouched, preserving the original representational structure and enabling efficient merging post-training.
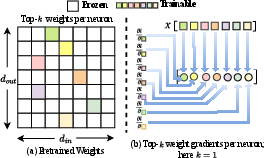
Figure 2: Neuron-wise Top-k Weight Selection and Gradient Computation. (a) Pretrained weight matrix of size dout×din, with top-k weights per neuron selected for adaptation. (b) Gradients are computed only for trainable entries, enabling fine-grained, neuron-level adaptation.
This approach eliminates the need for runtime masking and full-gradient computation, which are major sources of inefficiency in mask-based sparse tuning. The static selection pattern allows for compact storage: only k indices and k BF16 values per neuron, yielding over 100x memory savings per layer compared to mask-based methods.
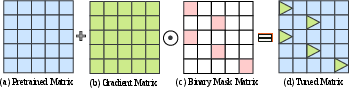
Figure 3: Mask-based sparse tuning incurs significant memory overhead, as gradients for the entire parameter matrix must be computed and retained by the optimizer.
Training and Inference Efficiency
During training, only the selected delta parameters are updated. The optimizer state (e.g., AdamW) is maintained for these sparse entries, reducing memory usage by a factor of din per layer. The forward pass is implemented via fused scatter-add operations, ensuring that only the k selected positions per neuron are involved in computation. After training, the learned deltas are merged into the base weights, incurring zero inference-time overhead.
Comparative Analysis
Empirical evaluation on 23+ tasks, including commonsense reasoning, arithmetic reasoning, and natural language understanding, demonstrates that NeuroAda achieves state-of-the-art performance with as little as 0.02% trainable parameters. Notably, it outperforms mask-based sparse tuning by up to 14% in accuracy on commonsense reasoning tasks at higher parameter budgets, while reducing CUDA memory usage by up to 60%.

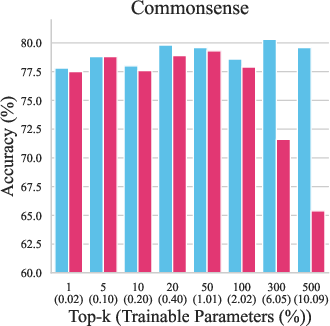
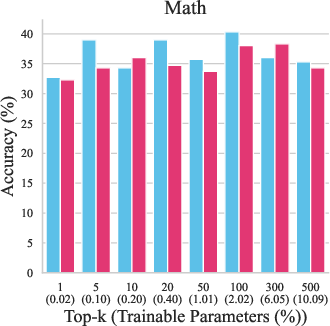
Figure 4: Performance comparison between NeuroAda and mask-based methods on LLaMA-7B. NeuroAda achieves superior accuracy across most parameter budgets.

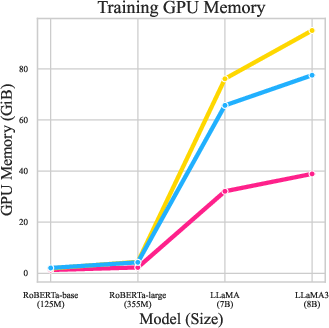
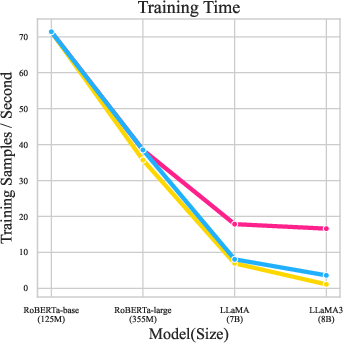
Figure 5: Training GPU memory and efficiency on RoBERTa-base, RoBERTa-large, LLaMA-7B, and LLaMA3-8B. NeuroAda consistently consumes less memory and enables faster training, especially for larger models.
Neuron-Level Adaptation
A key design principle of NeuroAda is ensuring that every neuron in the network has the potential to update its activation state during fine-tuning. Experiments varying the proportion of neurons involved in adaptation show consistent performance improvements as more neurons are activated, confirming the necessity of neuron-level coverage for effective downstream adaptation.
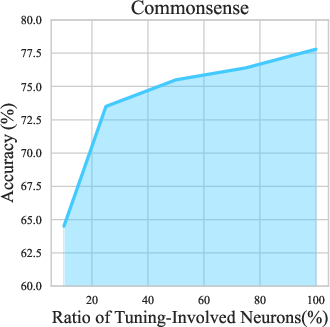

Figure 6: Comparison across different proportions of neurons involved in the fine-tuning process. Performance improves as more neurons are activated.
Parameter Selection Strategies
NeuroAda's default selection criterion is weight magnitude, chosen for its task-agnostic stability and offline computability. Ablation studies comparing magnitude, gradient, reverse-magnitude, and random selection show that all strategies yield comparable performance, but magnitude selection achieves the highest win rate across parameter budgets.

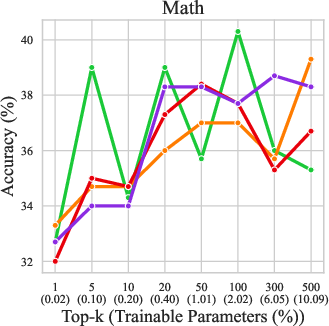
Figure 7: Comparison of different parameter selection strategies for involving neurons in fine-tuning. Magnitude-based selection consistently achieves the best results.
Experimental Results
NeuroAda is benchmarked against strong PEFT baselines (BitFit, LoRA, DoRA, SMT, RED, DiReFT, LoReFT) on LLaMA-7B/13B, LLaMA2-7B, LLaMA3-8B, and RoBERTa-base. Under both moderate and extreme parameter budgets, NeuroAda achieves the highest average accuracy across commonsense reasoning, arithmetic reasoning, and GLUE tasks. For instance, on LLaMA-13B with 0.016% trainable parameters, NeuroAda surpasses all baselines in both accuracy and generalization.
Implementation Considerations
- Static Selection: Top-k selection is performed offline, requiring only a single pass over the pretrained weights. This avoids the need for gradient-based warm-up or dynamic masking.
- Sparse Storage: Only k indices and k BF16 values per neuron are stored, enabling deployment on commodity GPUs and facilitating scaling to larger models.
- Optimizer State: AdamW or similar optimizers maintain state only for the sparse delta parameters, reducing memory by orders of magnitude.
- Inference: Post-training, the sparse deltas are merged into the base weights, preserving model structure and runtime efficiency.
Limitations and Future Directions
Current evaluation is limited to models up to 13B parameters. While the method is expected to scale favorably, empirical validation on larger models and multimodal architectures (e.g., VLMs) remains an open direction. Further research may explore dynamic selection strategies, integration with quantization, and application to vision-language tasks.
Conclusion
NeuroAda presents a scalable, memory-efficient, and fine-grained adaptation framework for large neural networks. By statically selecting top-k input connections per neuron and introducing sparse additive bypasses, it achieves robust generalization and state-of-the-art performance under extreme parameter and memory constraints. The method is broadly applicable, task-agnostic, and compatible with standard inference pipelines, making it a practical solution for efficient model adaptation in resource-constrained environments.