- The paper demonstrates that simple rule-based procedural data can match or exceed the quality of manually curated datasets for MVS training.
- It employs NURBS-based geometry, programmable textures, and randomized camera and lighting setups to generate diverse and effective training data.
- Empirical results show robust generalization and efficiency across multiple benchmarks, highlighting scalable 3D vision dataset generation.
SimpleProc: Minimalist Procedural Data for Multi-View Stereo
Introduction
The development of methods for generating synthetic data is crucial for advancing multi-view stereo (MVS) and related 3D vision tasks. SimpleProc introduces a fully procedural synthetic data pipeline, leveraging a compact set of geometric and appearance rules to efficiently generate effective large-scale MVS training datasets. Diverging from traditional approaches reliant on manually curated assets created by artists, video game resources, or 3D scans, SimpleProc formulates scenes by composing NURBS-based geometry, programmatically defined textures, and randomized camera and lighting configurations. This strategy greatly reduces the overhead associated with large-scale data curation, enabling rapid dataset synthesis and facilitating ablation on specific generative parameters.
A central contribution is the empirical demonstration that simple rule-based procedural data can yield MVS training quality on par with or exceeding existing manually curated collections, even at a modest scale. These findings have significant implications for scalable training in 3D perception, dataset diversity, and the theoretical necessity of realistic detail in supervision signals.

Figure 1: Fully procedural synthetic data from simple rules (top) is as effective as curated data from artists or 3D scans (bottom) for training multi-view stereo models.
Procedural Data Generation Pipeline
SimpleProc’s data generation pipeline consists of three main stages: NURBS-based geometric shape construction, fine-grained displacement and surface texturing, and randomized scene assembly with camera and lighting variation. The process is instantiated in Blender and is fully automatable, supporting high-throughput generation on standard compute infrastructure.

Figure 2: Procedural Data Generation Pipeline. Stage 1 generates NURBS surfaces from the lofting operation. Stage 2 applies displacements, textures, and material properties. Stage 3 arranges cameras, objects, lighting, and optional room boxes.
Shape Generation
Base shape synthesis is performed by lofting closed profile curves along open NURBS stem curves. Profiles are generated by perturbing control points sampled according to “starfish” (radial Gaussian noise) or “reptile” (2D random walk plus offset) strategies, ensuring diversity in surface topology and enabling both smooth and sharply featured structures. The resultant shapes are highly amenable to procedural displacement and texturing and cover a wide geometric spectrum without category priors.

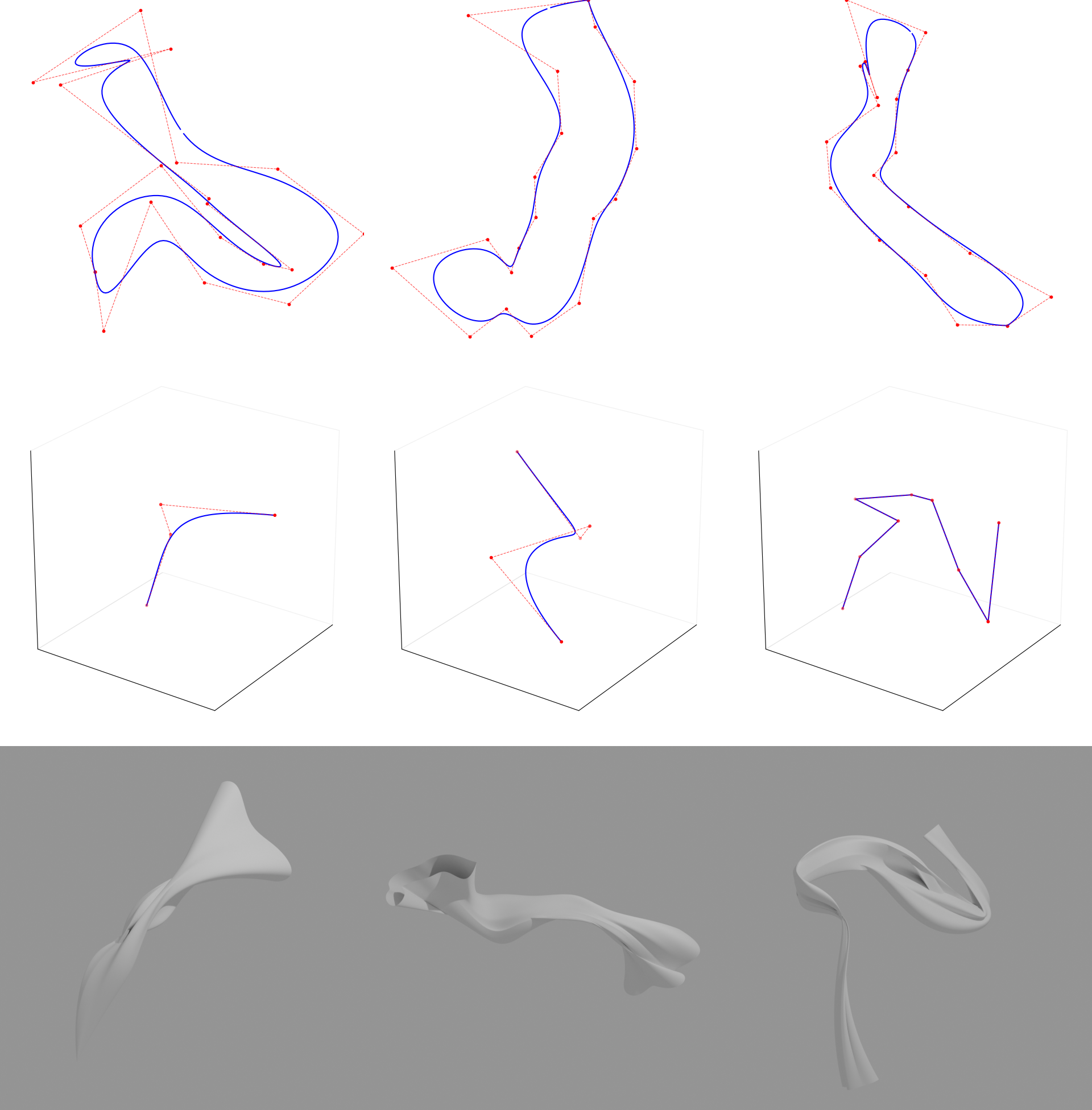
Figure 3: Shape generation pipeline. Top: Profile curves (Starfish and Reptile styles) with control points in red (only one of the profiles is shown for each shape). Middle: Stem curves from 3D random walks. Bottom: Resulting lofted NURBS surfaces showing diverse smooth and sharp features.
Surface Displacement and Texturing
To inject local high-frequency detail, SimpleProc employs both geometry node-based displacement using brick, wave, or noise patterns and microgeometry adjustments at shader-level displacement sockets. These displacements, applied with randomly sampled intensity and spatial scale, provide domain shifts in shape appearance akin to those found in real-world data, which are essential for supervisory signal diversity. Textures are likewise applied using parameterized procedural functions (Perlin noise, brick, wave), further combined using boolean operations to increase complexity. Object material properties are sampled from constrained ranges for parameters such as roughness and metallicity, supporting plausible photometric variation.






Figure 4: Shapes with Displacement and Textures. The top row shows displacements applied to base shapes. The middle row shows textures from brick, wave, or Perlin noise. The bottom row shows complex textures created by boolean operations.
Scene Composition, Camera, and Lighting
Scenes are composed of multiple large and small objects, with primary objects centered and secondary elements distributed either uniformly or following a “cluttered” (on-surface) scheme. Optional “room boxes” simulate indoor environments with planar boundaries; ground planes and scattered micro-objects create unstructured, “outdoor”-like regions. Cameras are sampled with randomized azimuth, elevation, and distance, always looking at the scene center, ensuring coverage diversity and robust covisibility. Lighting is introduced via plane-sampled area lights, with counts and placements randomized to further increase data variance. All rendering is performed with Blender’s EEVEE engine for performance.

Figure 5: Gallery of 10 random examples of our generated scenes.
Experimental Evaluation
Controlled Fixed-Budget Comparisons
Models were trained under strict data budget parity (8,000 images) on MVSAnywhere and evaluated on the challenging RMVD suite (KITTI, ScanNet, ETH3D, DTU, Tanks & Temples). SimpleProc’s fully procedural data achieves superior or equivalent accuracy (“rel,” “τ”) to both the 8-dataset curated mixture and MegaSynth, with the exception of ScanNet—a benchmark with less covisibility and noisier depth estimates, favoring models trained on highly realistic scene priors.
Scaling to Large Datasets
When scaling up to 352,000 images, SimpleProc-trained MVSAnywhere achieves parity with—or slightly exceeds—the performance of models trained on over 692,000 manually curated images across nearly all non-ScanNet benchmarks. This result substantiates the claim that a carefully crafted yet minimal procedural rule set can substitute for broad manual asset coverage. Notably, the approach is highly data-efficient and yields robust generalization on diverse, real-world test domains.

Figure 6: Unlimited-Budget qualitative comparison across five benchmarks. Our procedural training data yields competitive depth estimation results compared to the 8-dataset baseline.
Ablation Studies
Detailed ablations are conducted over procedural rule choices, including shape families (primitives vs. NURBS), displacement and texturing algorithms, scene composition (number and arrangement of objects), presence of room boxes, count and configuration of lights, and camera placement strategies. The study reveals that incremental improvements in each domain (e.g., complex NURBS over primitives, boolean-combined noise textures, hybrid object placement, expanded light counts) contribute cumulatively to robust MVS performance. These findings expose the sensitivity of generalization capacity to specific procedural recipe elements and illustrate the value of minimal but carefully optimized rule sets.
Implications and Future Directions
SimpleProc’s results demonstrate that highly effective MVS supervision signals are attainable from entirely procedural sources, indicating that expensive manual asset curation and photorealistic realism are not strictly necessary for robust geometry learning. The approach optimizes for variation, diversity, and photogeometric challenge rather than mimetic realism, suggesting an avenue for broader generalization and transfer learning in 3D vision.
Practically, this facilitates rapid, large-scale data generation, enables fine-grained study of data bias and model robustness, and decouples dataset expansion from real-world data collection constraints. Theoretically, it challenges the assumption that task-optimal MVS models require exposure to “natural” objects or scenes; instead, supervision on sufficiently varied, abstract, and structurally rich synthetic data provides a strong inductive basis.
Limitations are primarily in modeling specific category-level priors or subtle photometric effects present in real data; as the ScanNet results suggest, full substitution may be less effective for domains with significant non-geometric signal dependencies. Future research could explore integration with small amounts of real data for domain adaptation, optimization of procedural rule discovery (e.g., via neural architecture search-inspired methods), and extension to other vision tasks requiring dense geometric or semantic labels.
Conclusion
SimpleProc establishes that a minimalist, well-designed procedural pipeline can generate multi-view stereo datasets that match or surpass the effectiveness of extensive manually curated collections. The findings underscore the sufficiency of abstract geometric and textural diversity for learning robust MVS models and set a precedent for scalable, controllable, and efficient synthetic data generation in 3D vision.