- The paper presents a comprehensive comparison between direct and indirect PINN formulations, identifying indirect PINNs as superior in minimizing control and state errors.
- It explores the loss balancing challenges in direct PINNs, with numerical experiments on the Allen-Cahn equation illustrating performance trade-offs.
- The study shows that integrating direct PINN initializers with adjoint methods accelerates convergence and enhances solution fidelity.
PINNs in PDE-Constrained Optimal Control Problems: Comparative Analysis of Direct and Indirect Methods
Introduction
PINNs have become foundational in scientific machine learning, providing mesh-free approaches for forward/inverse problems governed by PDEs. Their extension to PDE-constrained optimal control presents new opportunities and challenges, especially regarding the correct representation of the variational structure inherent to optimal control. This paper systematically investigates the distinction between direct and indirect PINN-based formulations for optimal control of semilinear PDEs, with a focus on parabolic equations. A thorough empirical comparison is made between these approaches and discretize-then-optimize adjoint methods, using the Allen-Cahn optimal control problem as a testbed (2604.04920).
Problem Setting and Theoretical Foundations
The class of optimal control problems considered is governed by semilinear parabolic PDEs of the form
∂ty−νΔy+f(y)=Buin Q,
with u a distributed control, f a nonlinear reaction, and quadratic objectives including terminal and regularization terms. Classical direct methods optimize the reduced functional after state discretization; indirect methods form and solve the optimality (KKT) system via adjoint state and stationarity conditions. Both perspectives yield differing structural and numerical properties.
PINNs provide neural surrogates for state, control, and adjoint variables, trained by minimizing residuals from the governing equations and constraints. The loss landscape and the efficacy of the resulting control are deeply influenced by whether the direct (objective-based) or indirect (optimality-system-based) approach is employed.
In direct PINNs, the state and control networks are jointly optimized by penalizing the residual of the state PDE and the control objective, along with initial and boundary conditions. The loss function is a weighted sum of these terms, relying on soft constraint enforcement for the PDE and on Monte Carlo integration for the cost functional over collocation points.
This approach avoids explicit adjoint computation, offering greater accessibility and lower overhead in implementation. However, the presence of competing penalization terms introduces a critical sensitivity to loss balancing: excessive weight on the objective can degrade PDE satisfaction, and vice versa. Consequently, convergence to a solution that accurately meets both the control target and the state constraint is nontrivial.
Indirect PINNs encode the full first-order optimality system, involving networks for the state, adjoint, and control. For the Allen-Cahn case with B=I, the optimality condition reduces to a direct relation, λ=βQu, enabling the adjoint network to be constructed by design from the control network. The loss function then penalizes the simultaneous residuals of the state and adjoint PDEs along with all constraints.
This direct enforcement of the KKT conditions leads to more informative gradients during optimization and ensures that minimization of the loss implies proximity to a true optimality system solution. Empirically, this approach yields more accurate approximations of the control and state when compared to both the direct PINN and adjoint methods started from random initialization.
Numerical Experiments and Comparative Results
Experiments on the Allen-Cahn equation demonstrate the behaviors and relative performance of all three methods. The adjoint baseline employs full discretization with piecewise-constant-in-time controls and second-order temporal integration, achieving robust but oscillatory solutions highly dependent on initialization.
Direct and indirect PINNs utilize compact MLPs with tanh activations for state/control representation. Training requires substantial collocation sampling (e.g., 20,000 interior points) and benefits critically from quasi-Newton optimizers (e.g., SSBroyden) in float64 precision, as Adam alone fails to reach the low residual regime necessary for accurate control recovery.
Loss histories reveal divergent convergence properties:
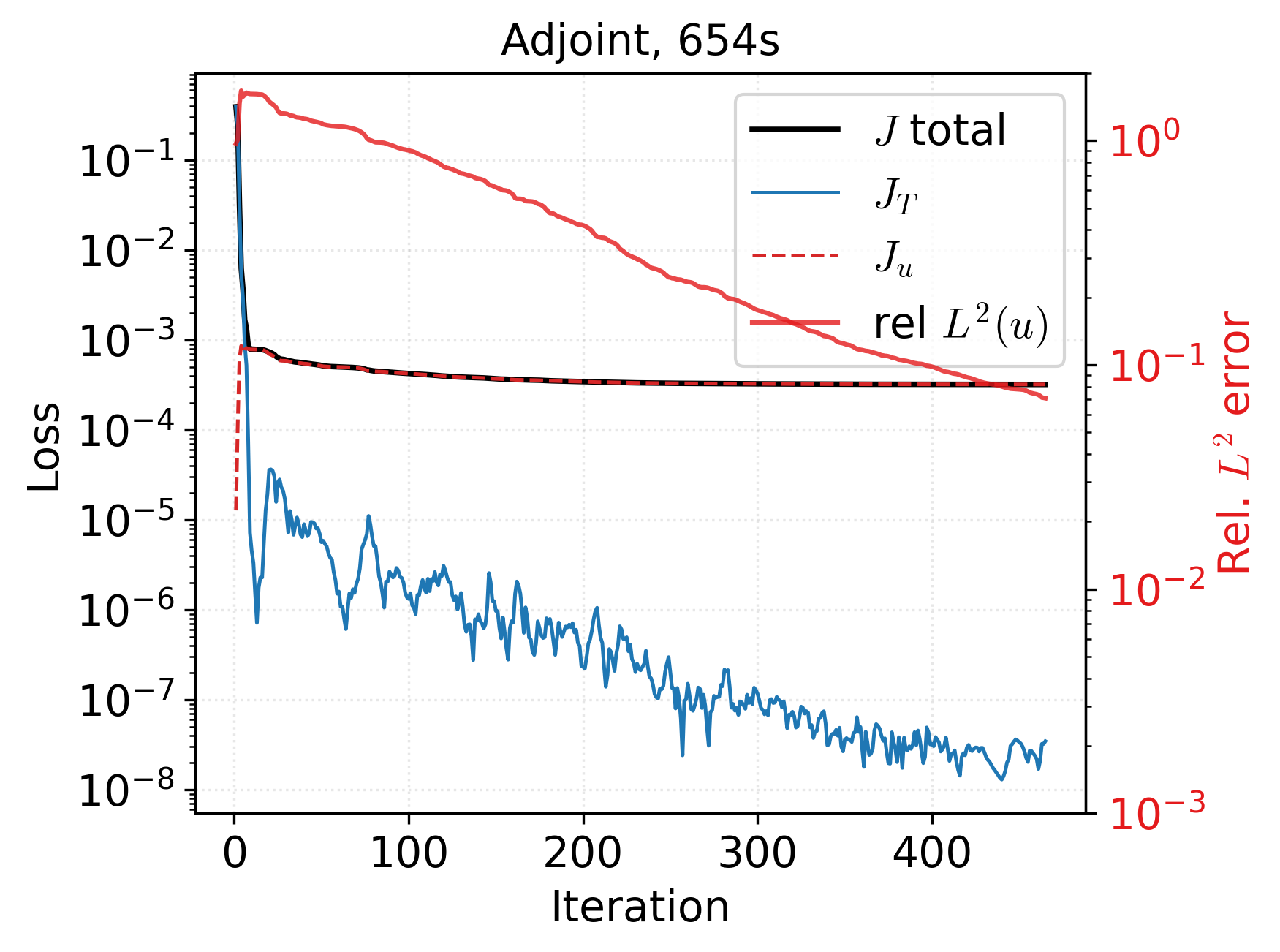
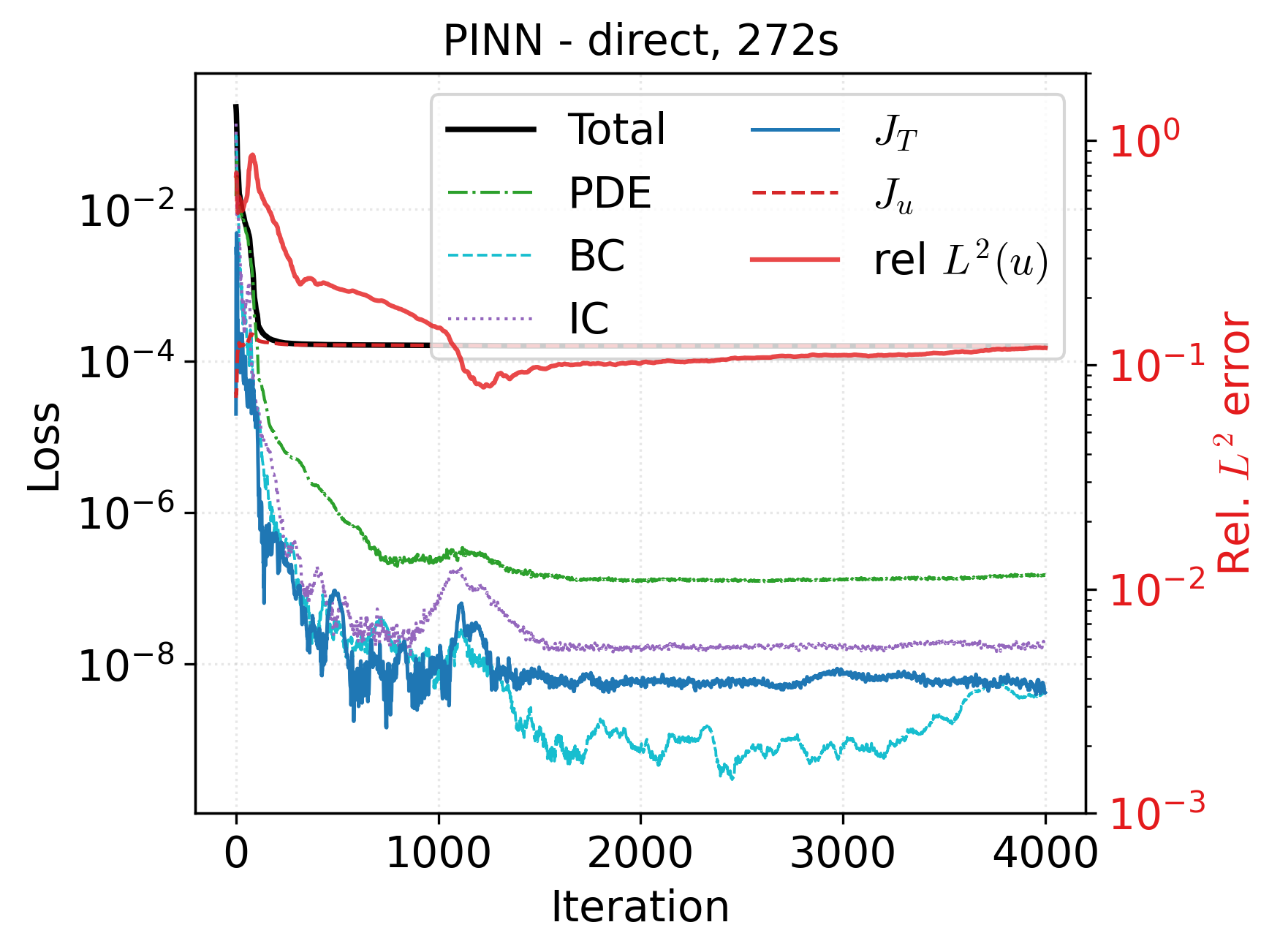
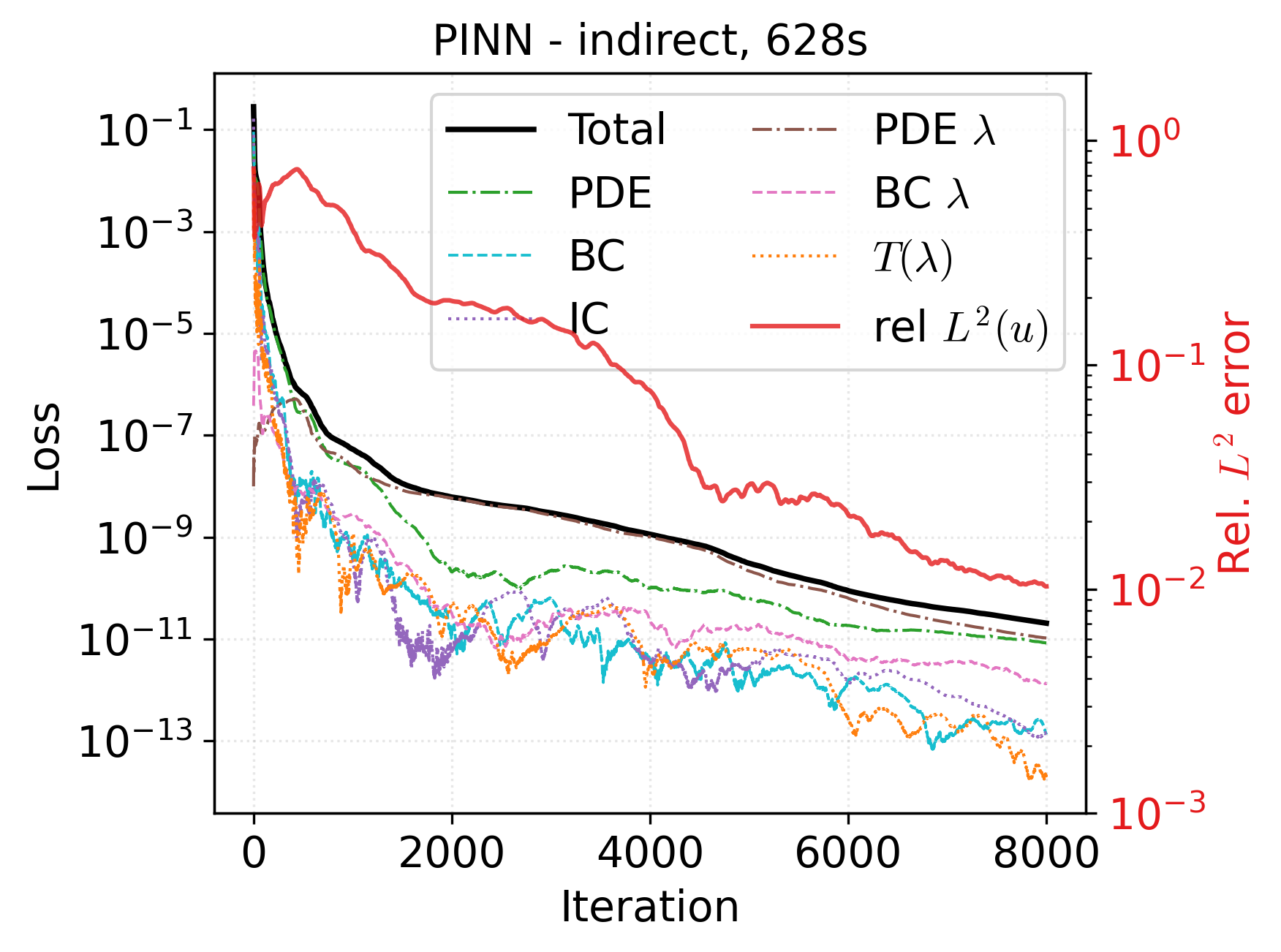
Figure 1: Loss histories show adjoint (top) converges steadily, direct PINN (middle) suffers from loss balancing challenges, and indirect PINN (bottom) attains consistently minimal residuals for both state and adjoint equations.
Control and state comparison exposes qualitative and quantitative differences:
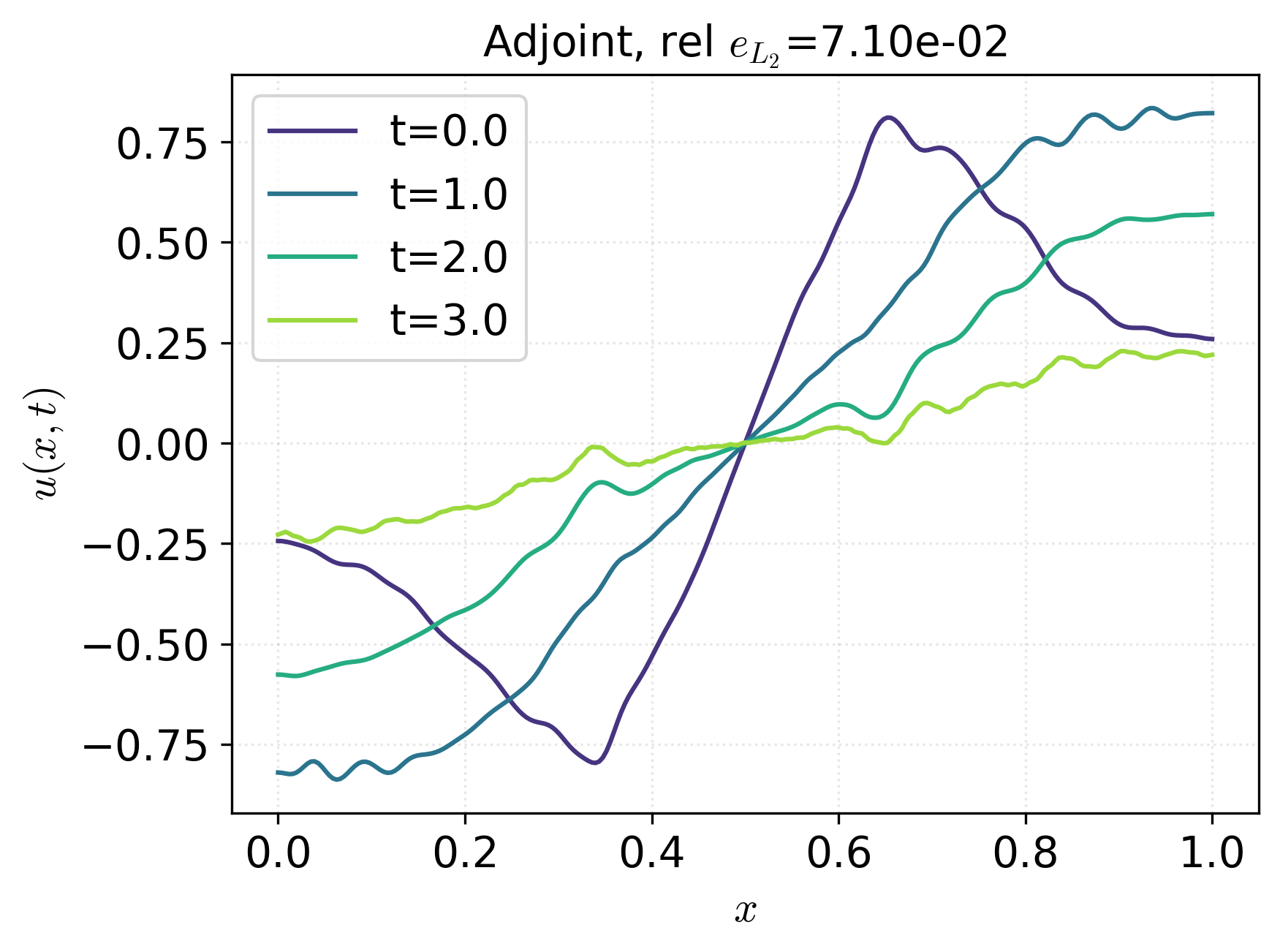
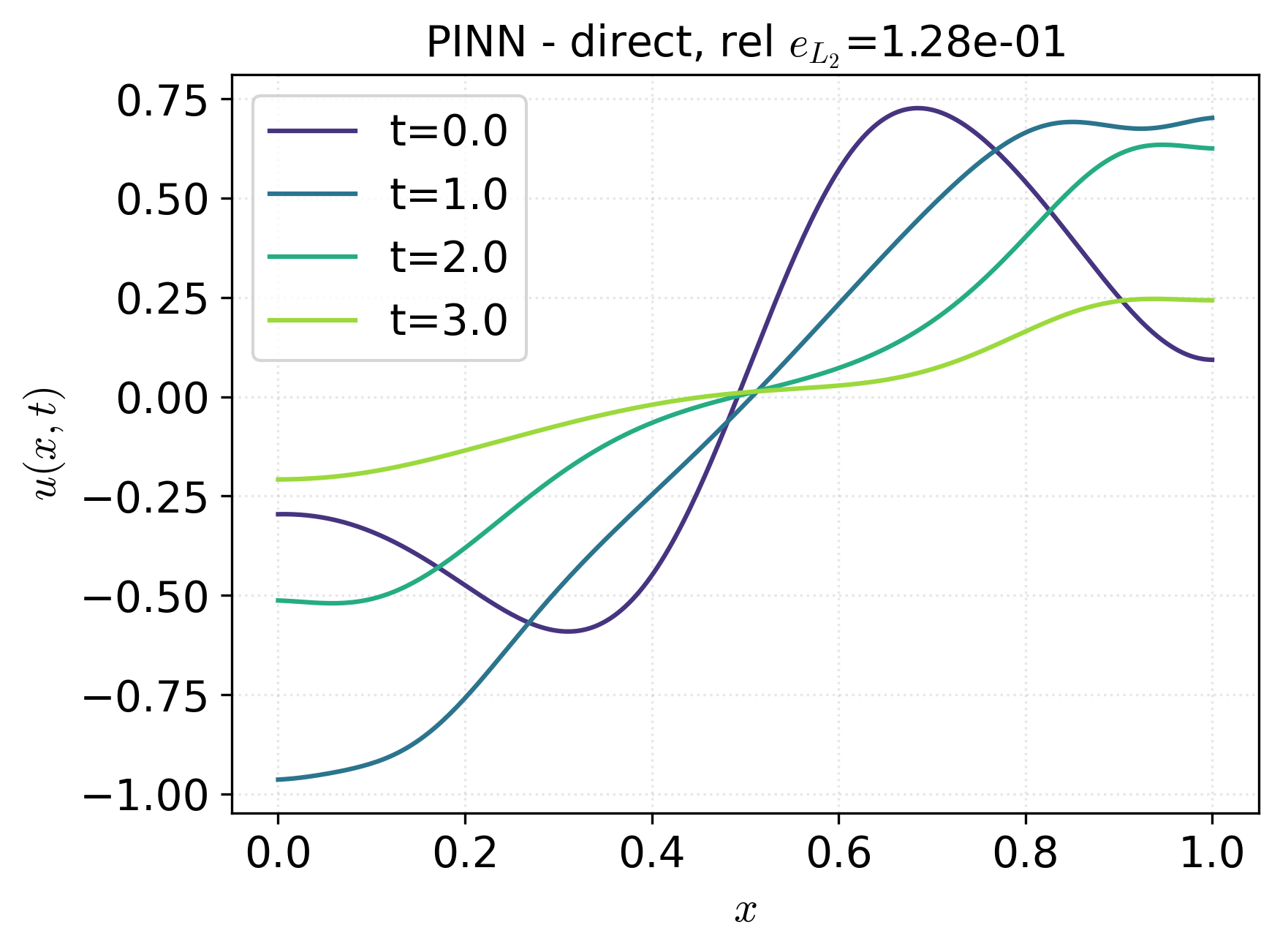
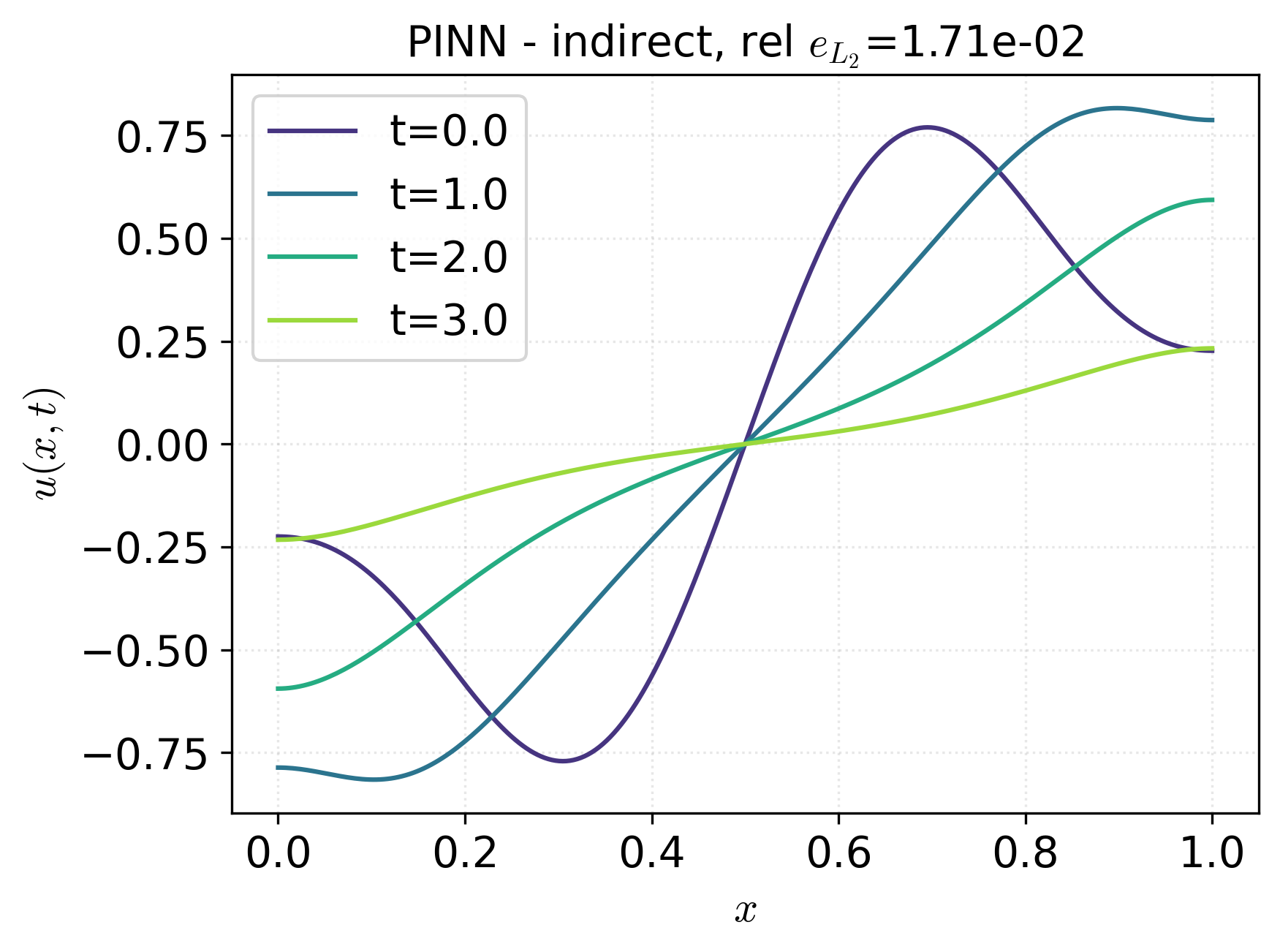
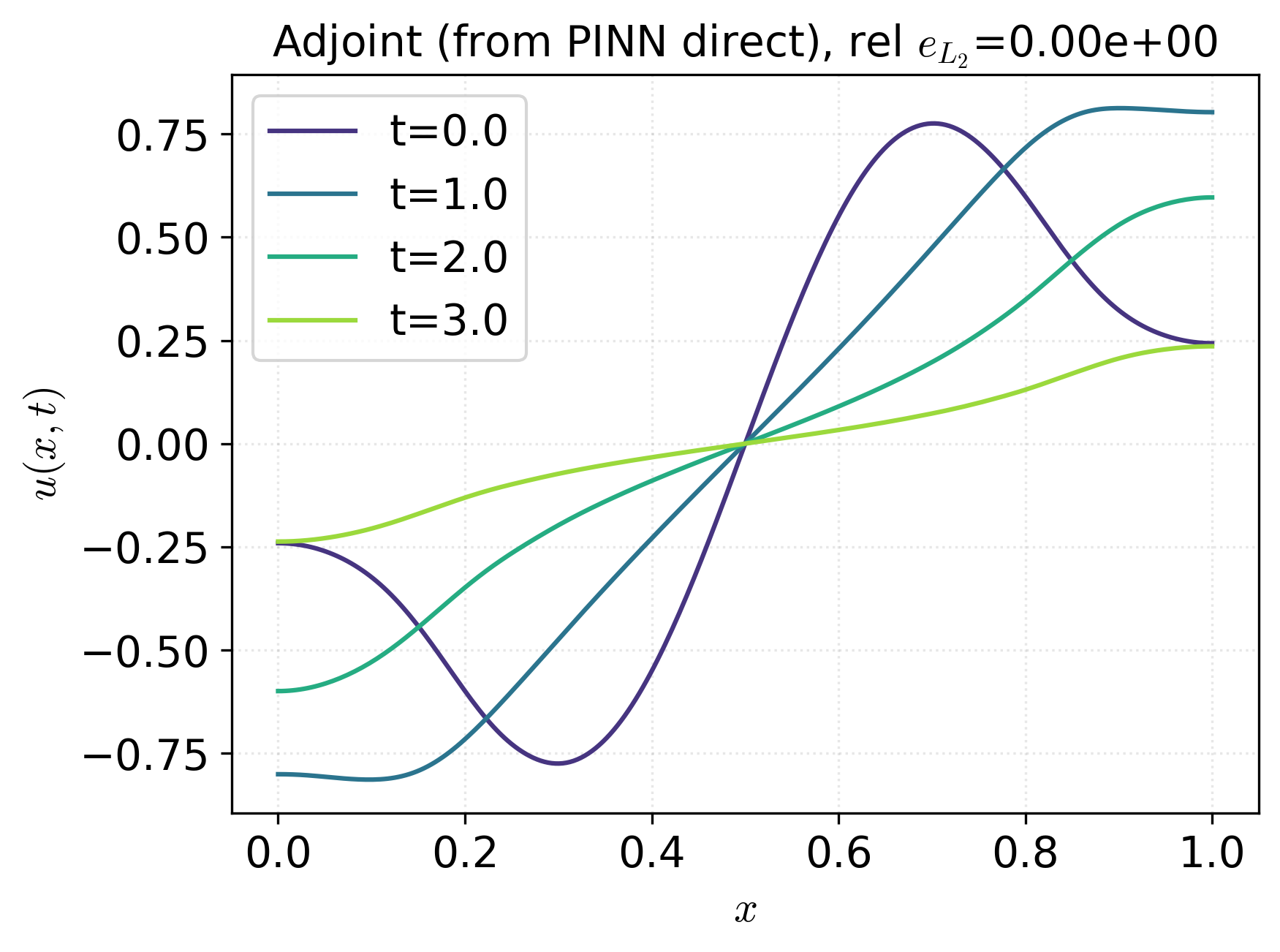
Figure 2: Control profiles for adjoint, direct PINN, indirect PINN, and adjoint initialized by direct PINN, with relative L2 errors annotated, indicating superior control approximation by the indirect PINN approach.
State evolution, recomputed with each method's control via the reference time-stepping solver, further underscores these aspects:
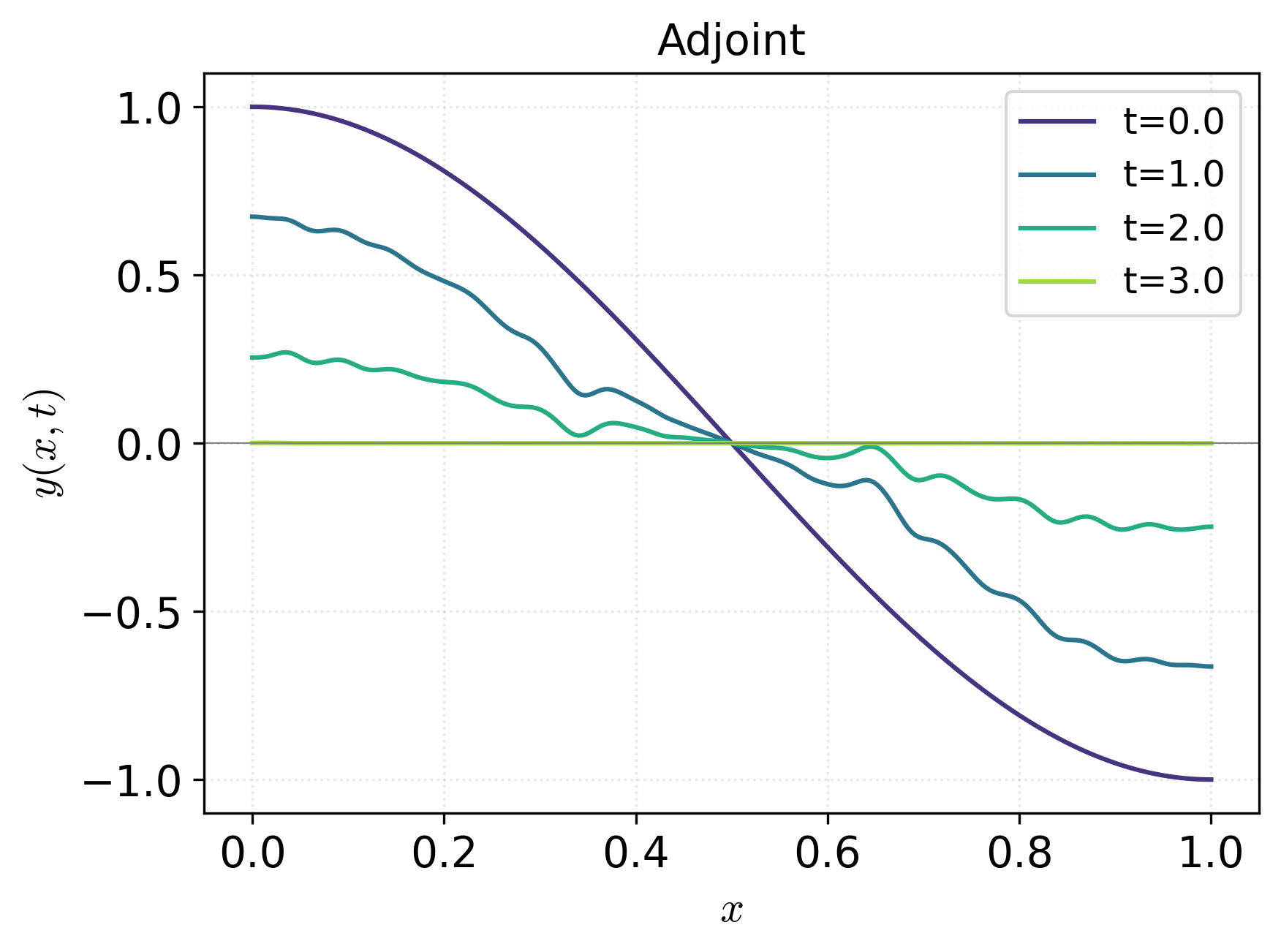
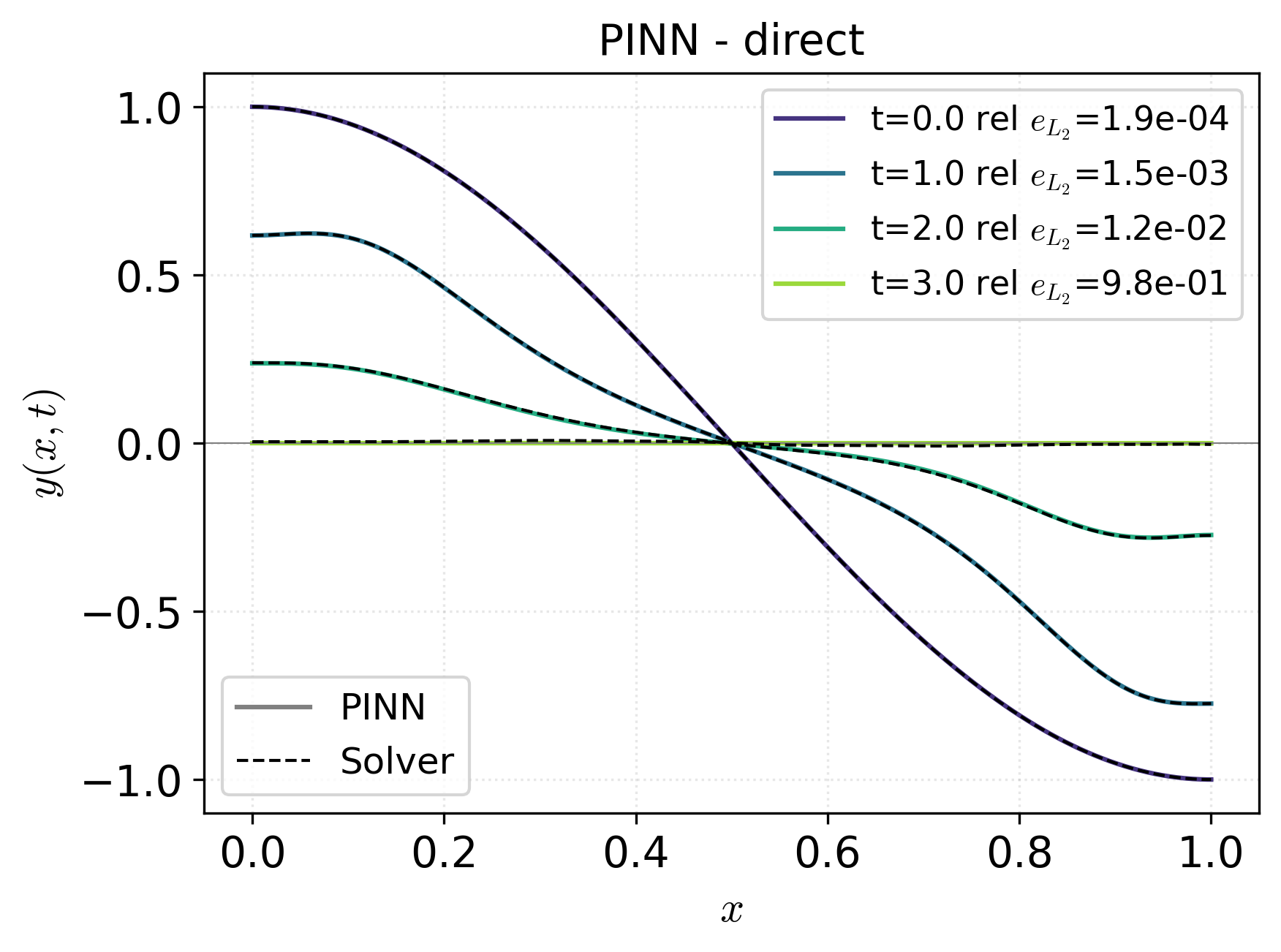
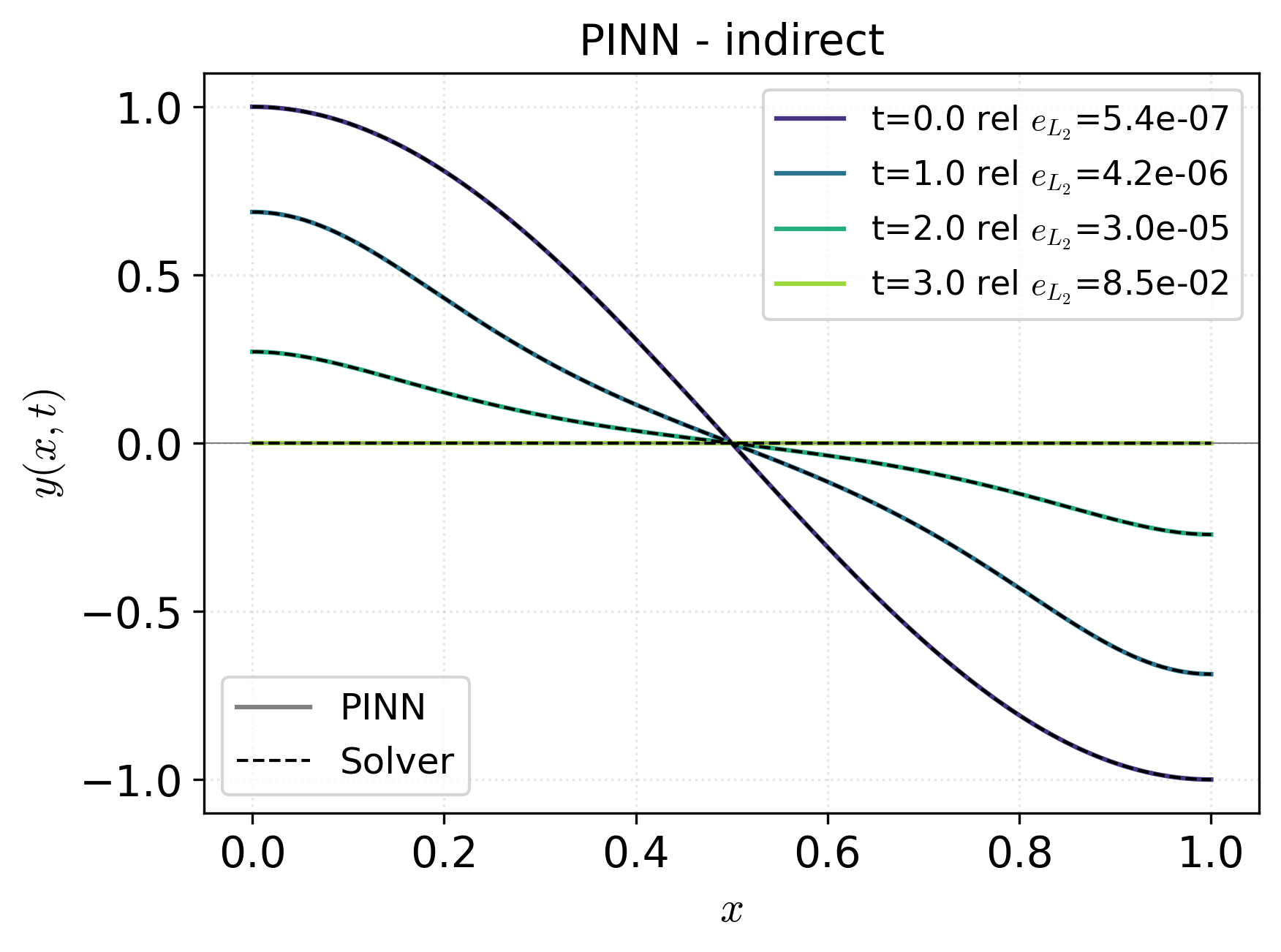
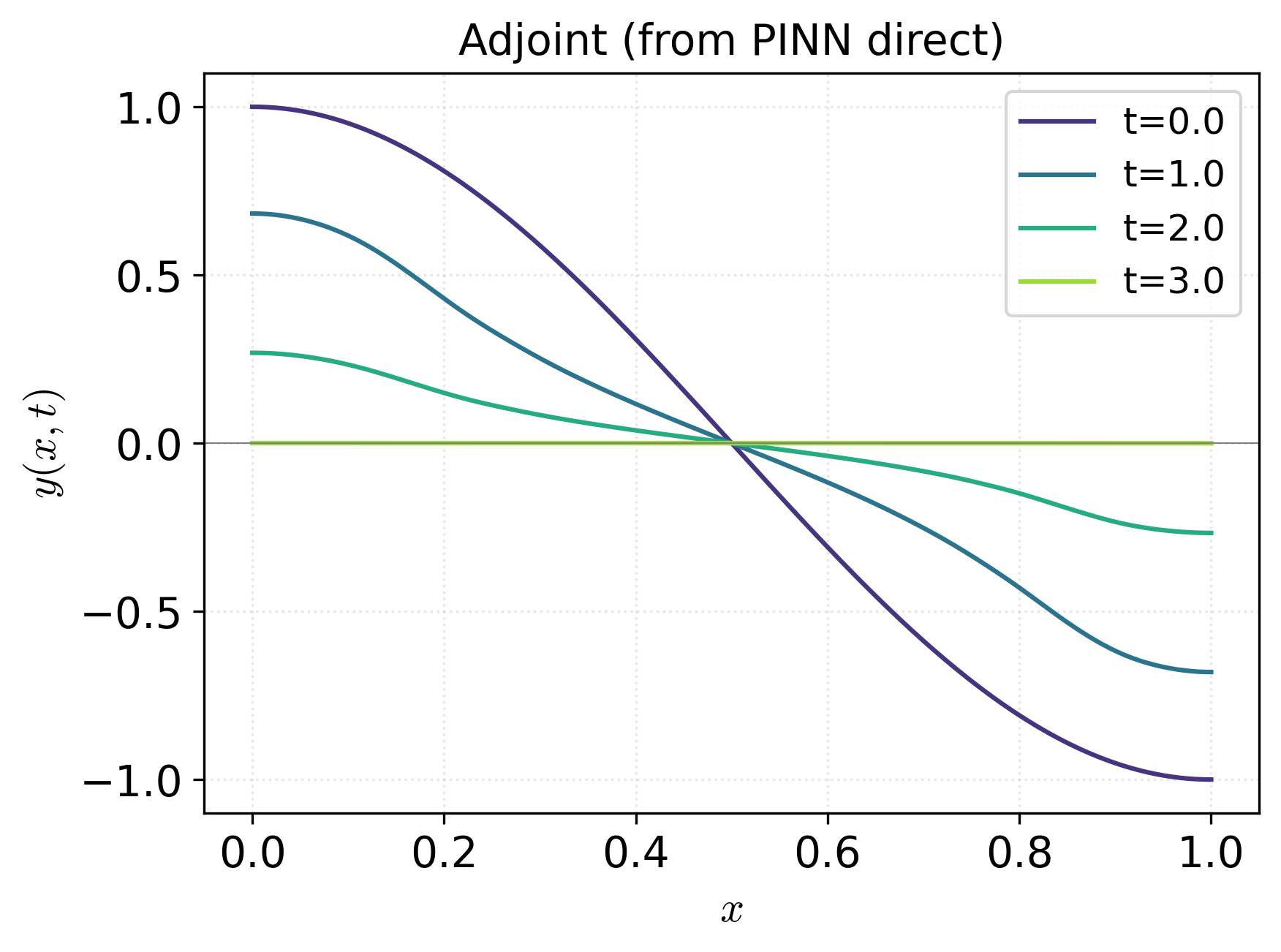
Figure 3: State trajectories highlight that only indirect PINN and adjoint-refined-from-PINN deliver high-accuracy solutions, as indicated by small L2 errors; the direct PINN's state-network prediction diverges increasingly at later times.
Key Numerical Findings
- The indirect PINN obtains control and state solutions with significantly lower relative L2 errors compared to the direct PINN, closely matching the high-fidelity reference.
- Direct PINN results are dominated by the penalization trade-off, yielding suboptimal control and state, but the resulting parametric smoothness is useful as an initializer in adjoint optimization cycles.
- The discrete adjoint method, when started from a smooth direct PINN control, achieves the most favorable objective values, showing that PINN-derived controls can regularize and accelerate traditional solvers.
Practical and Theoretical Implications
The results articulate strong guidance for method selection and workflow design in PDE-constrained control using PINNs:
- Indirect PINNs, when properly optimized with second-order methods and at high precision, are statistically and practically superior for recovery of the correct optimality system solution, hence preferred for applications demanding accuracy.
- Direct PINNs, benefiting from architectural smoothness and low parameterization capacity, act as effective smoothers and warm-start generators, especially for high-dimensional or nonconvex problems where adjoint codes are costly or inaccessible.
- The study demonstrates that hybrid strategies—in which a direct PINN provides initialization for either an indirect PINN or a traditional adjoint method—yield the best overall performance in terms of solution quality and computational efficiency.
On a theoretical level, the findings highlight the importance of respecting the structure of the KKT system in neural-parametric approaches, cautioning against reliance on surrogate penalization unless only approximate solutions are acceptable. Furthermore, the numerical sensitivity and convergence characteristics showcased here stress the necessity of adopting advanced optimization techniques for physics-informed models.
Future Directions
Building on these insights, future research in scientific machine learning for control should address:
- PINN architectures better adapted for saddle-point problems, potentially incorporating explicit constraints or Lagrangian parameterization.
- Automated and adaptive loss weighting schemes to mitigate the balancing issues present in direct methods.
- Scalable implementations of indirect PINNs for high-dimensional and nontrivial control constraint settings, potentially exploiting transfer learning and neural operator frameworks.
- Theoretical quantification of error propagation from neural PDE solvers to downstream control objectives.
Conclusion
This work establishes that indirect PINN formulations, directly enforcing the KKT optimality system, outstrip direct objective-based PINNs in PDE-constrained optimal control—provided that advanced optimization and high precision are used. Direct PINNs retain utility as smooth initializers, enabling hybrid workflows that combine machine learning-based regularization with classical adjoint refinement. These findings inform both the design of PINN-based optimization algorithms and their integration with legacy control solvers for nonlinear PDE systems.