A Frame is Worth One Token: Efficient Generative World Modeling with Delta Tokens
Abstract: Anticipating diverse future states is a central challenge in video world modeling. Discriminative world models produce a deterministic prediction that implicitly averages over possible futures, while existing generative world models remain computationally expensive. Recent work demonstrates that predicting the future in the feature space of a vision foundation model (VFM), rather than a latent space optimized for pixel reconstruction, requires significantly fewer world model parameters. However, most such approaches remain discriminative. In this work, we introduce DeltaTok, a tokenizer that encodes the VFM feature difference between consecutive frames into a single continuous "delta" token, and DeltaWorld, a generative world model operating on these tokens to efficiently generate diverse plausible futures. Delta tokens reduce video from a three-dimensional spatio-temporal representation to a one-dimensional temporal sequence, for example yielding a 1,024x token reduction with 512x512 frames. This compact representation enables tractable multi-hypothesis training, where many futures are generated in parallel and only the best is supervised. At inference, this leads to diverse predictions in a single forward pass. Experiments on dense forecasting tasks demonstrate that DeltaWorld forecasts futures that more closely align with real-world outcomes, while having over 35x fewer parameters and using 2,000x fewer FLOPs than existing generative world models. Code and weights: https://deltatok.github.io.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “A Frame is Worth One Token: Efficient Generative World Modeling with Delta Tokens”
What’s this paper about?
This paper is about teaching computers to predict what might happen next in a video—like how traffic will move in the next second. That’s important for robots and self-driving cars. The authors propose a new, much faster way to make several different future guesses at once by focusing only on what changes between video frames, instead of redrawing everything from scratch each time.
They introduce:
- DeltaTok: a way to compress “what changed” between two frames into one small piece of information called a “delta token”
- DeltaWorld: a small, fast model that uses these delta tokens to generate many possible futures in a single pass
What questions are they trying to answer?
The paper asks:
- Can we predict several different possible futures quickly and efficiently?
- Can we skip unnecessary details (like pixel-perfect textures) and work in a smarter “feature” space that captures meaning (like where the road and cars are)?
- If we represent each frame by just “what changed,” can we make the model smaller, faster, and still accurate?
How did they approach it? (With plain-language explanations)
To make this easy to understand, here are a few key ideas and simple analogies:
- World model: A system that tries to predict how the world (or a video) will evolve over time.
- Features vs pixels: Instead of looking at every pixel (every tiny dot of color), the model uses “features” from a vision foundation model—a pretrained network that summarizes what’s in the image (like “road,” “car,” “sky”). Think of features as a smart summary rather than a detailed photo.
- Tokenizer: A tool that compresses information so the model can process it easily. Like zipping a file before sending it.
- Delta token: Instead of saving the entire frame, it saves just the difference between the last frame and the next—like telling a friend “the car moved a bit forward and the light turned green,” not describing the whole scene again.
- Best-of-Many (BoM) training: During training, the model makes multiple guesses of the future at once. The training only rewards the best guess among them. This teaches the model to produce different, realistic futures in a single shot. Think: you throw several darts and count only the closest one—over time, you get better at throwing useful varieties.
- FLOPs and parameters: Roughly, FLOPs is how much “work” the computer does; parameters are how big the model is. Less of both means faster and cheaper.
What they actually built:
- They start with features from a strong vision model (so they focus on meaning, not perfect pixels).
- They design DeltaTok to turn the change between frames into just one token per frame (not hundreds). This collapses the video from a big 3D grid (height × width × time) into a simple 1D list over time—one token per frame.
- They train DeltaWorld to predict these delta tokens. Because each future is just one token per frame, the model can generate many possible futures in parallel, fast.
- They use BoM training to encourage variety: the model proposes many futures; the training rewards the one closest to the truth. At test time, those different inputs produce diverse futures in one pass.
What did they find, and why does it matter?
Main results:
- Huge compression: With 512×512 frames, using delta tokens reduces the number of tokens by about 1,024×. That’s a massive simplification.
- Speed and size: Their model uses over 35× fewer parameters and about 2,000× fewer FLOPs compared to a popular generative baseline (called Cosmos), yet still matches or beats it on key tasks.
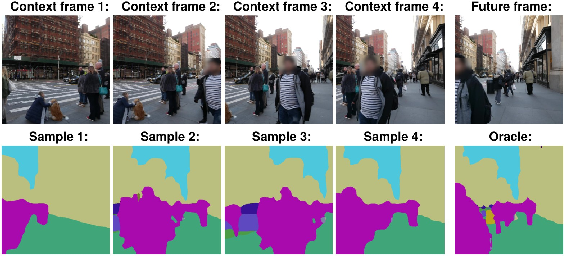
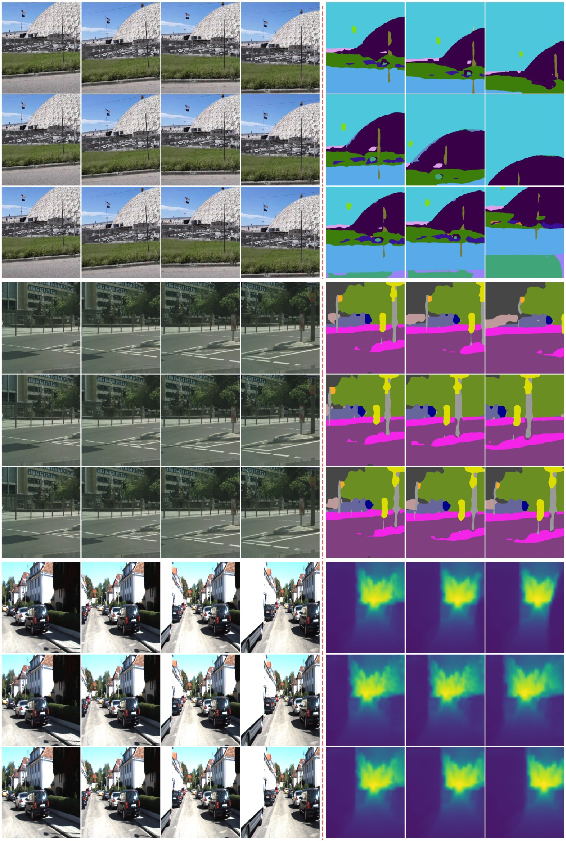
- Quality: On tasks like predicting future scene segmentation (which parts are road, car, sky) and depth (how far things are) on datasets like Cityscapes, VSPW, and KITTI:
- The “best” prediction among multiple samples is better than prior generative models.
- The average of predictions stays competitive, showing the futures are realistic rather than random noise.
- A helpful “no-change” rule: Because delta tokens describe change, predicting “no change” naturally keeps the scene consistent. This helps the model avoid weird or unstable predictions.
Why this matters:
- Making several future guesses is crucial for safety in real-world systems (like choosing a safe path in traffic).
- Doing it fast and with a small model means it’s practical for systems that have limited computing power (like onboard computers in cars or drones).
What could this lead to?
- Faster, safer planning for autonomous vehicles and robots, since they can consider many futures quickly.
- Lower energy use and hardware costs, because the model is smaller and more efficient.
- A general idea that “modeling changes, not everything” can be reused in other areas—like games, simulations, or any system that needs to forecast what happens next.
- Easier integration with many tasks, since the model works in a feature space that’s already useful for things like segmentation and depth.
In short
This paper shows a smart shortcut: predict only what changes between frames, pack that into one tiny token per frame, and train the model to generate many different futures at once. The result is a smaller, faster, and surprisingly accurate system for predicting what happens next in videos—just what you’d want for robots and self-driving cars.
Knowledge Gaps
Below is a concise list of the paper’s key knowledge gaps, limitations, and open questions that remain unresolved and could guide future research:
- Action conditioning is absent: the model predicts futures from visual context only; integration of control inputs (ego-motion, agent actions) and evaluation in embodied settings (robotics/AV) are unaddressed.
- Long-horizon stability is unknown: results are limited to short (~0.2 s) and mid (~0.6 s) horizons; error accumulation, drift, and stability over many autoregressive steps are not evaluated.
- Diversity and uncertainty are under-characterized: only best-of-N and mean scores are reported; there is no assessment of coverage, calibration (e.g., CRPS, ECE), likelihood, or diversity metrics.
- No selection/scoring mechanism for inference: best-of-N requires ground-truth to pick “best”; the paper does not propose a way to rank or weight futures at test time for downstream use.
- Single-token capacity is unanalysed: a single delta token per frame may be insufficient for complex, multi-agent, or highly nonrigid scene changes; there is no study of token dimensionality or capacity limits.
- Lack of adaptive tokenization: there is no mechanism to allocate multiple or variable-rate delta tokens when motion complexity is high; the trade-off vs. a single global token is unexplored.
- Robustness to low temporal redundancy is untested: hard cuts, fast camera motion, dynamic backgrounds, and high-frequency appearance changes are not evaluated; the claimed fallback to “absolute compression” is not empirically validated.
- Occlusion/disocclusion handling is not benchmarked: despite claims of natural handling, there is no targeted evaluation against flow/warping baselines on occlusion-focused datasets.
- Exposure bias remains: training uses teacher forcing while inference is autoregressive; no scheduled sampling or mitigation is studied, and compounding error analysis is missing.
- VFM dependence is narrow: only DINOv3 is used; sensitivity to VFM choice (e.g., CLIP/SigLIP), resolution/patch size, and potential end-to-end VFM fine-tuning are not investigated.
- Separate training may be suboptimal: tokenizer and predictor are trained independently; joint or task-aware training to improve predictability (vs. reconstruction) is not explored.
- Tokenizer loss is simplistic: MSE on VFM features may not align with semantic/task salience; perceptual, contrastive, or task-weighted objectives are not assessed.
- No pixel-space synthesis: the approach operates purely in feature space; feasibility, quality, and efficiency of decoding delta tokens to photorealistic video remain open.
- Evaluation breadth is limited: only segmentation and monocular depth are tested; tracking, detection, optical flow, 3D occupancy, and closed-loop planning/control benefits are not assessed.
- Stochastic input prior is simplistic: Gaussian noise queries lack structure; learning a richer, controllable, or interpretable prior over futures is not examined.
- No probabilistic weighting: samples are unweighted; absence of calibrated probabilities hinders planner integration that requires likelihoods for different futures.
- Data efficiency is unknown: models are trained on ~4M videos; performance under limited data and data-scaling laws are not studied.
- Domain shift and robustness are untested: OOD conditions (night, weather, rare events), sensor noise, motion blur, and compression artifacts are not evaluated.
- Temporal rate generalization is unclear: training uses offsets in [1/25, 1/3] s; behavior under varying frame rates, irregular sampling, or extrapolation beyond trained time scales is not analyzed.
- Scaling laws and compute–accuracy trade-offs are limited: beyond a BoM heatmap, there is no systematic study of model/tokenizer size, token dimensionality, and K (train vs. inference) for optimal Pareto performance.
- System-level efficiency reporting is incomplete: FLOPs are emphasized, but end-to-end inference latency, throughput, and memory across hardware configurations are not comprehensively reported.
- First-step initialization is ad hoc: using a black frame to create an “absolute” first token may create a train–test mismatch; its impact on cold-start quality is not quantified.
- Baseline fairness may be imperfect: re-encoding Cosmos pixel outputs into VFM features could bias the comparison; pixel-level metrics or feature-space-aware decoders for Cosmos are not reported.
- Multi-view/sensor fusion and audio are not considered: extension to multi-camera rigs, LiDAR/radar fusion, or audiovisual modeling remains unexplored.
- Physical and geometric consistency is unconstrained: there are no dynamics or geometry priors; temporal consistency of predicted depth/segmentation is not analyzed.
- Failure mode analysis is missing: there is no taxonomy of typical errors (e.g., mode dropping, implausible trajectories) or safety-critical failure assessment.
- Adaptive bitrate/token budget is not explored: learning to allocate more tokens when needed (variable-rate coding) could improve fidelity without sacrificing efficiency.
- Downstream selection under compute budgets is open: strategies to choose a task-optimal subset of generated futures for planners are not provided.
- Reproducibility details are sparse: training data composition, potential overlaps, and licensing are not fully specified, complicating exact reproduction.
Practical Applications
Immediate Applications
Below are actionable, deployable-now uses that leverage DeltaTok/DeltaWorld’s compact delta-token representation and single-pass, multi-hypothesis forecasting in VFM feature space.
- Robotics and Autonomous Systems (autonomous driving, drones, mobile robots)
- Use case: Low-latency, multi-hypothesis scene forecasting for safer planning (e.g., predict pedestrian/vehicle layouts, free space, and depth 0.2–0.6 s ahead).
- Tools/workflows: Embed DeltaWorld as a forecasting module in ROS-based stacks; feed K future feature-rollouts into sampling-based or risk-aware planners; run on embedded GPUs due to low FLOPs.
- Assumptions/dependencies: Requires a frozen VFM (e.g., DINOv3) on-device; segmentation/depth heads must be trained for the domain; planners must be able to evaluate multiple futures, not just a single “best” sample; sensor framerate/time-sync must be reliable.
- Edge Video Analytics and Smart Cameras (security, retail, logistics)
- Use case: On-camera predictive analytics (e.g., next-frame semantic segmentation/depth to anticipate crowding, line formation, or anomalous motion).
- Tools/workflows: Integrate as a microservice in VMS; export delta tokens and inferred labels instead of pixels for privacy-lean pipelines; run on low-power edge accelerators.
- Assumptions/dependencies: Camera viewpoints and motion regimes seen in training; accurate feature heads for the specific classes of interest; downstream alert logic to operate on an ensemble of futures.
- AR/VR and Mixed Reality
- Use case: Predictive occlusion handling and depth for time-warping and late-stage reprojection; reduce perceived latency by forecasting semantic/depth features one step ahead.
- Tools/workflows: Integrate DeltaWorld’s future feature maps into ARKit/ARCore pipelines as a pre-render step; fuse with IMU for better temporal stability.
- Assumptions/dependencies: Stable frame intervals; domain adaptation for egocentric footage; feature-to-rendering bridges (e.g., using depth/segmentation-based compositing).
- Sports Broadcasting and Live Production
- Use case: Forecast player/ball occupancy maps and depth for auto-framing and camera switching; anticipate where to pan/zoom.
- Tools/workflows: Plug-in for production switchers that consumes multi-hypothesis future masks; on-edge inference in smart PTZ cameras.
- Assumptions/dependencies: Training on sport-specific footage; robust tracking or re-identification may still be required for individual targets; variable stadium lighting may require domain finetuning.
- Warehousing and Industrial Automation
- Use case: Predict forklift/pallet paths and free-space evolution to schedule robot routes and avoid congestion.
- Tools/workflows: Warehouse VMS plugin that streams features from static cams or robot cams; planners consume multiple futures for robust routing and pause/resume policies.
- Assumptions/dependencies: Consistent camera placement; trained heads for relevant semantic classes; integration with WMS/robot fleet management.
- Public Safety and Smart Cities
- Use case: Proactive traffic management by forecasting near-future occupancy/segmentation at intersections to adapt signal timing or trigger V2I warnings.
- Tools/workflows: Roadside cameras running DeltaWorld; traffic control systems simulate outcomes across K futures and choose conservative control actions.
- Assumptions/dependencies: Municipal data governance; calibrated cameras; roadway domain heads; policy guardrails for privacy when storing features.
- Software/ML Tooling
- Use case: Efficient multi-hypothesis forecasting module in CV pipelines and RL simulators.
- Tools/workflows: Release of DeltaTok/DeltaWorld SDKs, ONNX/TensorRT inference; plug-ins for PyTorch-based planners and gym-like environments; unit tests for BoM sampling.
- Assumptions/dependencies: Access to pre-trained VFMs and tokenizer weights; reproducible timing; proper seeding for BoM diversity.
- Sustainability/Green AI (cross-sector)
- Use case: Lower compute and energy for video forecasting tasks compared to diffusion/AR models.
- Tools/workflows: Procurement criteria and MLOps dashboards that track FLOPs/energy per forecast; edge deployment profiles.
- Assumptions/dependencies: Realized energy savings depend on hardware utilization and end-to-end system design; upstream training costs should be amortized.
Long-Term Applications
These opportunities require further research, scaling, domain adaptation, or standardization before broad deployment.
- Action-Conditioned World Models for Decision-Making (autonomous driving, robotics)
- Use case: Predict how the world evolves given candidate actions (e.g., ego-vehicle maneuvers) with K futures per action, enabling model-predictive control.
- Potential products: Unified perception-planning module that couples DeltaWorld with action embeddings; training-in-the-loop with closed-loop RL.
- Dependencies/assumptions: Action-conditioned training data; safe exploration/simulation; robust evaluation under distribution shift; formal verification for safety-critical domains.
- Feature-Space Video Coding/Standards
- Use case: A new codec paradigm that transmits delta tokens instead of pixels for analytics-first pipelines; downstream tasks decode features, not images.
- Potential products: “DeltaTok Codec” profiles for smart cameras and NVRs; standard VFMs embedded in devices.
- Dependencies/assumptions: Industry consensus on reference VFMs; privacy-risk management (features can sometimes be inverted to pixels); mixed ecosystems where some consumers still require pixels.
- Multi-Modal Delta Tokens (vision + LiDAR/IMU/audio)
- Use case: Fuse temporal changes across sensors into unified tokens for robust forecasting in varied weather/lighting.
- Potential products: Robotics world models that operate on joint delta tokens; cross-modal distillation frameworks.
- Dependencies/assumptions: Time-synchronized multi-sensor datasets; tokenizers that align different modalities in shared embedding spaces.
- 3D/Scene-Level Predictive Digital Twins
- Use case: Predictive scene graphs and 3D occupancy flow for digital twins (factories, campuses), enabling “what-if” analyses.
- Potential products: Twin simulators that roll out many futures via delta tokens and feed them to simulators for policy stress tests.
- Dependencies/assumptions: Consistent multi-view geometry; calibration; 3D-aware tokenizers/decoders; scalable data infrastructure.
- Healthcare and Surgical Assistance (high regulation)
- Use case: Anticipate next instrument/tissue states to assist surgeons or endoscopic navigation with low-latency forecasts.
- Potential products: In-the-loop advisory systems that surface multiple plausible evolutions and risk scores.
- Dependencies/assumptions: Domain-specific VFMs trained on medical data; stringent validation and regulatory approval; bias and safety risk assessments.
- Personalized and Egocentric Assistants
- Use case: Predict hand/object interactions and free space from head-mounted cameras for anticipatory prompts, safety cues, or accessibility aids.
- Potential products: Wearable assistants that schedule actions based on K plausible futures (e.g., warn about tripping hazards).
- Dependencies/assumptions: Egocentric datasets, on-device inference; privacy-preserving design; seamless integration with UX.
- Retail Operations and Crowd Flow Forecasting
- Use case: Multi-hypothesis forecasts of customer movement to dynamically staff counters, open lanes, or redirect flows.
- Potential products: Store analytics dashboards with predictive heatmaps and confidence bounds from ensembles of futures.
- Dependencies/assumptions: Domain adaptation for indoor scenes; ethics/privacy compliance; ability to act on predictions (staff rostering systems).
- Training-Efficient RL via Compact World Models
- Use case: Model-based RL that learns policies by rolling out many futures cheaply, improving sample efficiency.
- Potential products: RL platforms that replace costly pixel-space models with delta-token world models.
- Dependencies/assumptions: Task-specific rewards in feature space; stable training of BoM with exploration noise; action-conditioned extensions.
- Safety and Policy Tooling
- Use case: Risk evaluation frameworks that quantify uncertainty by analyzing spread/diversity across K futures for safety cases and audits.
- Potential products: Policy dashboards and audit trails that record multi-hypothesis forecasts and decisions taken under uncertainty.
- Dependencies/assumptions: Accepted metrics for plausibility/diversity; storage and governance for forecast ensembles; standards for “green” and “safe” AI procurement.
- Pixel-Level Generation via Feature-to-Image Decoders
- Use case: Turn predicted features into future frames (for visualization, editing, or downstream pixel-based tasks) by coupling DeltaWorld with a learned feature-to-pixel decoder.
- Potential products: Lightweight predictive frame interpolation/editing tools with controllable diversity.
- Dependencies/assumptions: Reliable feature-to-image decoders; careful handling of identity/appearance drift over long horizons; compute budgets for decoding.
Cross-Cutting Assumptions and Dependencies
- Representation: Relies on strong, stable VFMs (e.g., DINOv3). Domain gaps may degrade feature predictability; domain-adaptive finetuning may be necessary.
- Task Heads: Downstream segmentation/depth heads must be trained and validated for the deployment domain.
- Diversity Use: In practice, there is no ground truth at inference to pick the “best” sample; applications must either evaluate policies across all futures or implement scoring/consensus mechanisms.
- Temporal Redundancy: Delta tokens exploit inter-frame redundancy; performance may drop for abrupt cuts or extremely high-motion scenes unless the model is trained for such regimes.
- Data and Ethics: Large-scale, representative video datasets are required; privacy and bias considerations apply, even in feature space.
- Safety-Critical Deployment: Requires rigorous testing, calibration, and possibly formal methods to translate forecast diversity into safe decisions.
Glossary
- autoencoder: An encoder–decoder neural network that compresses inputs into a latent representation and reconstructs them. "A typical visual tokenizer follows an autoencoder~\cite{hinton2006reducing} architecture"
- autoregressive models: Generative models that predict the next element conditioned on previous ones in a sequence. "and autoregressive models~\cite{esser2021taming,yu2022scaling,sun2024autoregressive,tian2024visual,yu2025randomized}"
- autoregressive rollout: Iteratively feeding a model’s own predictions back as inputs to forecast multiple steps ahead. "At inference, the model can perform an autoregressive rollout, appending to the context before predicting the next."
- Best-of-Many (BoM): A training objective where multiple hypotheses are generated and only the one closest to ground truth is supervised. "we adopt a simple Best-of-Many (BoM)~\cite{bhattacharyya2018bom} training objective that achieves this in a single forward pass."
- causal attention mask: An attention constraint that prevents a model from accessing future tokens, enforcing temporal causality. "a causal attention mask restricts it to attending only to earlier frames"
- cross-attention: An attention mechanism that lets a query attend to a separate context sequence. "applying cross-attention from a single learnable query embedding to the context "
- delta token: A single token that encodes the change between consecutive frame features. "a single continuous ``delta'' token"
- DeltaTok: A tokenizer that encodes the VFM feature difference between consecutive frames into a single delta token. "we introduce DeltaTok, a tokenizer that encodes the VFM feature difference between consecutive frames into a single continuous ``delta'' token"
- DeltaWorld: A generative world model that operates on delta tokens to efficiently produce diverse future predictions. "DeltaWorld, a generative world model operating on these tokens to efficiently generate diverse plausible futures."
- diffusion denoising: The iterative reverse process used by diffusion models to generate data from noise. "continuous world models typically use diffusion denoising over a spatial grid."
- FLOPs: A measure of computational cost counting floating-point operations. "using fewer FLOPs"
- Gaussian distribution: A normal distribution characterized by mean and covariance, used here to sample noise queries. ""
- interframe (delta) compression: Video coding that encodes differences between frames rather than full frames. "interframe (delta) compression~\cite{wiegand2003overview}"
- latent space: A learned representation space where inputs are compressed for modeling or reconstruction. "rather than a latent space optimized for pixel reconstruction"
- Mean Squared Error (MSE): A regression loss measuring the average squared difference between predictions and targets. "trained with a Mean Squared Error (MSE) loss."
- mIoU (mean Intersection-over-Union): A segmentation metric averaging IoU across classes or frames. "Cityscapes mid mIoU"
- monocular depth estimation: Predicting scene depth from single-camera (single-view) images. "as well as monocular depth estimation on KITTI~\cite{geiger2013vision}."
- multi-hypothesis training: Training that generates many candidate futures in parallel and supervises only the best. "enables tractable multi-hypothesis training, where many futures are generated in parallel and only the best is supervised."
- noise queries: Random query embeddings used to stochastically sample diverse futures. "we draw noise queries from a Gaussian distribution"
- occlusions: Regions where objects block others from view, causing visibility changes across frames. "This naturally handles occlusions and new objects, where warping-based approaches struggle."
- optical flow: A per-pixel motion field describing apparent motion between frames. "optical flow~\cite{teed2020raft}"
- positional embeddings: Encodings that inject spatial or temporal position information into model inputs. "with positional embeddings ensuring position-dependent predictions."
- quantized: Discretized representations (e.g., codebook indices) instead of continuous latents. "depending on whether the latent representation is quantized."
- query embedding: A learned vector that queries context via attention to produce predictions. "a single learnable query embedding "
- semantic segmentation: Pixel-wise classification assigning a semantic label to each pixel. "which includes semantic segmentation on VSPW~\cite{miao2021vspw} and Cityscapes~\cite{cordts2016cityscapes}"
- self-attention: An attention mechanism where tokens attend to each other within the same sequence. "stacks of Transformer blocks with self-attention."
- spatio-temporal redundancy: Repetition or predictability across space and time in video data. "spatio-temporal redundancy that consecutive frames exhibit."
- teacher forcing: Training technique that feeds ground-truth previous outputs instead of model predictions. "using teacher forcing~\cite{williams1989learning}"
- tokenizer: A module that converts frames into compact tokens (latents) for modeling. "World models typically employ a tokenizer, which encodes frames into a spatio-temporal latent grid"
- Transformer blocks: Neural network blocks based on attention mechanisms for sequence modeling. "a stack of Transformer blocks~\cite{vaswani2017attention}"
- Vision Foundation Model (VFM): A large pretrained vision model providing general-purpose feature representations. "feature space of a vision foundation model (VFM)"
- Vision Transformer (ViT): A Transformer architecture applied to images by treating patches as tokens. "Both encoder and decoder are Vision Transformers (ViT)~\cite{dosovitskiy2021image} trained with a Mean Squared Error (MSE) loss."
- warping-based approaches: Methods that transform images using motion fields to align frames over time. "warping-based approaches struggle."
Collections
Sign up for free to add this paper to one or more collections.

