- The paper introduces DINO-world, a scalable video model leveraging a frozen DINOv2 encoder and transformer predictor to forecast future latent features.
- The model achieves robust performance on dense segmentation and intuitive physics tasks, with a 6.3% mIoU improvement on VSPW at a 0.5s horizon.
- The design’s modularity enables both unconditional pretraining and action-conditioned fine-tuning, supporting efficient control and planning across diverse video domains.
DINO as a Foundation for Video World Models: An Expert Analysis
Introduction
This paper introduces DINO-world, a scalable, generalist video world model that predicts future frames in the latent space of a frozen DINOv2 encoder. The approach leverages large-scale, uncurated video data to learn temporal dynamics across diverse domains, and demonstrates strong performance on dense forecasting, intuitive physics, and planning tasks. The architecture is designed for efficiency and modularity, enabling both unconditional pretraining and action-conditioned fine-tuning for downstream control and planning.
Methodology
Latent-Space World Modeling
The core innovation is to decouple visual representation learning from temporal dynamics modeling. A frozen DINOv2 ViT-B/14 encoder maps each video frame to a grid of patch tokens in a high-dimensional latent space. The world model, a transformer-based predictor, is trained to autoregressively predict future patch tokens given a context of past tokens and their timestamps. This design allows the model to operate at arbitrary frame rates, resolutions, and context lengths.
The predictor architecture consists of a stack of cross-attention blocks, where each query token (representing a future patch at a specific time and location) attends to all past patch tokens. Rotary positional encodings (RoPE) are injected along temporal and spatial axes, enabling the model to reason about spatiotemporal relationships and generalize across variable input configurations.
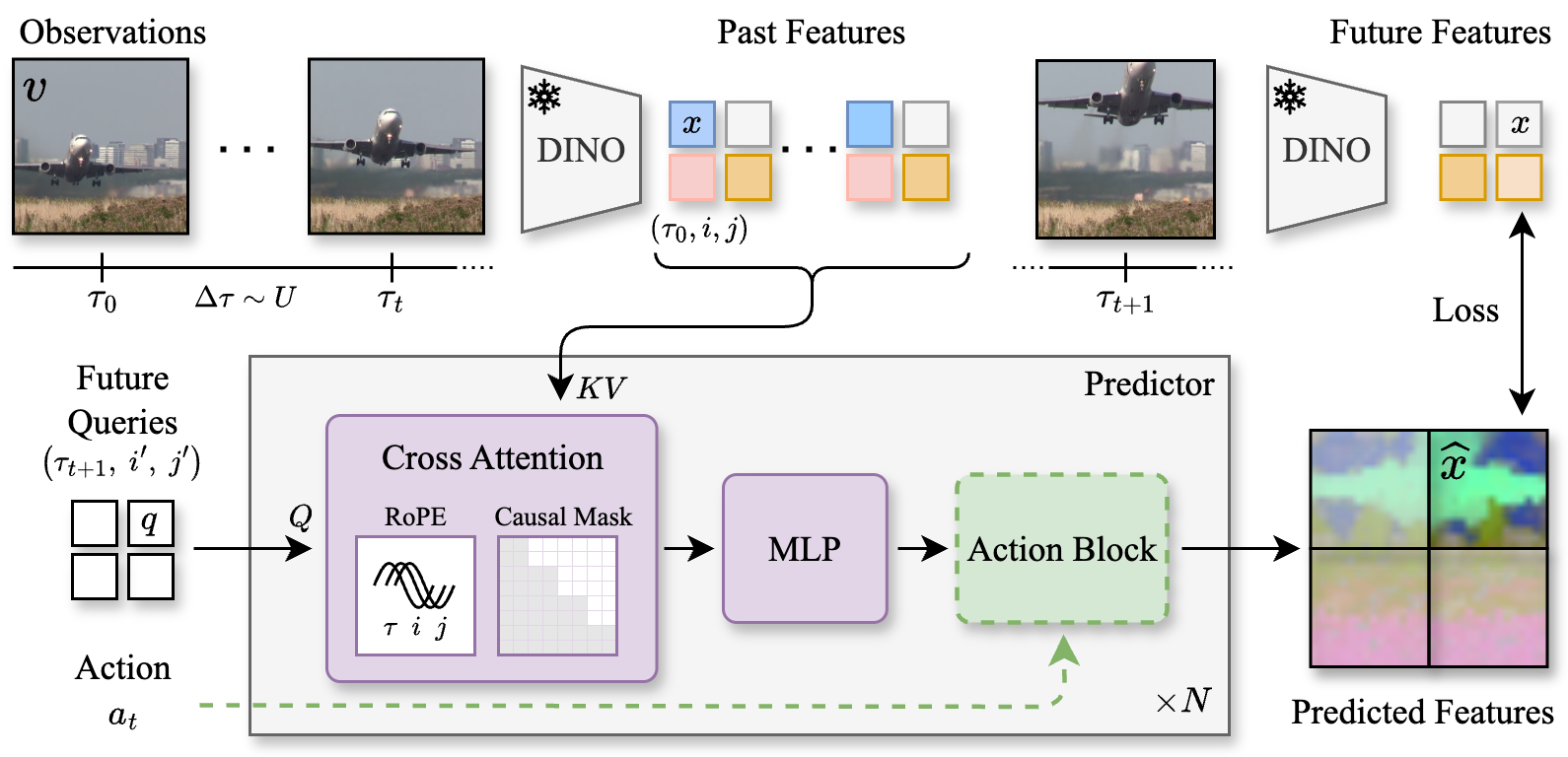
Figure 1: Latent video world model architecture. A frozen DINOv2 encoder maps video frames to patch tokens in latent space. The predictor is a stack of cross-attention blocks trained to predict future patch tokens from all past tokens and timestamps.
Training and Data
The model is trained on a private dataset of approximately 66 million uncurated web videos, spanning a wide range of domains, durations, frame rates, and resolutions. During training, time deltas between frames are uniformly sampled to ensure the model learns to predict at various temporal intervals, enhancing its ability to generalize to different prediction horizons.
The training objective is a smooth L1 loss between predicted and ground-truth patch features for all patches in all future frames, enabling efficient parallelization and stable optimization. The model is trained at scale, with predictor sizes up to 1.1B parameters, but remains significantly more resource-efficient than pixel-space generative models.
Action-Conditioned Fine-Tuning
For downstream control and planning, the unconditional predictor is augmented with action blocks. These blocks, inserted after each transformer layer, condition the query token on the agent's action at each timestep. Fine-tuning can be performed with a small dataset of observation-action trajectories, and optionally, only the action blocks are updated, preserving the general video understanding acquired during pretraining.
Experimental Results
Dense Forecasting and Intuitive Physics
The model is evaluated on dense forecasting tasks (semantic segmentation and depth prediction) using Cityscapes, VSPW, and KITTI datasets. Linear heads are trained on present-time DINOv2 features and applied to predicted features at future timesteps. DINO-world outperforms both pixel-space generative models (COSMOS) and joint encoder-predictor models (V-JEPA) in mid-term forecasting, with a notable 6.3% mIoU improvement over the next best model on VSPW at 0.5s prediction horizon.
On intuitive physics benchmarks (IntPhys, GRASP, InfLevel), the model achieves competitive or superior performance compared to other large-scale world models, indicating a robust understanding of physical plausibility and temporal consistency.


Figure 2: Autoregressive predictions. For each video, from top to bottom: frames with timestamps, encoder features, autoregressive predictions in latent space. The predictor has access to ground-truth encoder features for the initial context, then rolls out its own predictions.
Qualitative Analysis
Visualization of latent feature rollouts demonstrates the model's ability to track objects and scene dynamics over time, with uncertainty increasing at longer horizons. Cross-attention maps reveal that the model attends to relevant spatiotemporal regions, effectively tracking object trajectories and interactions.
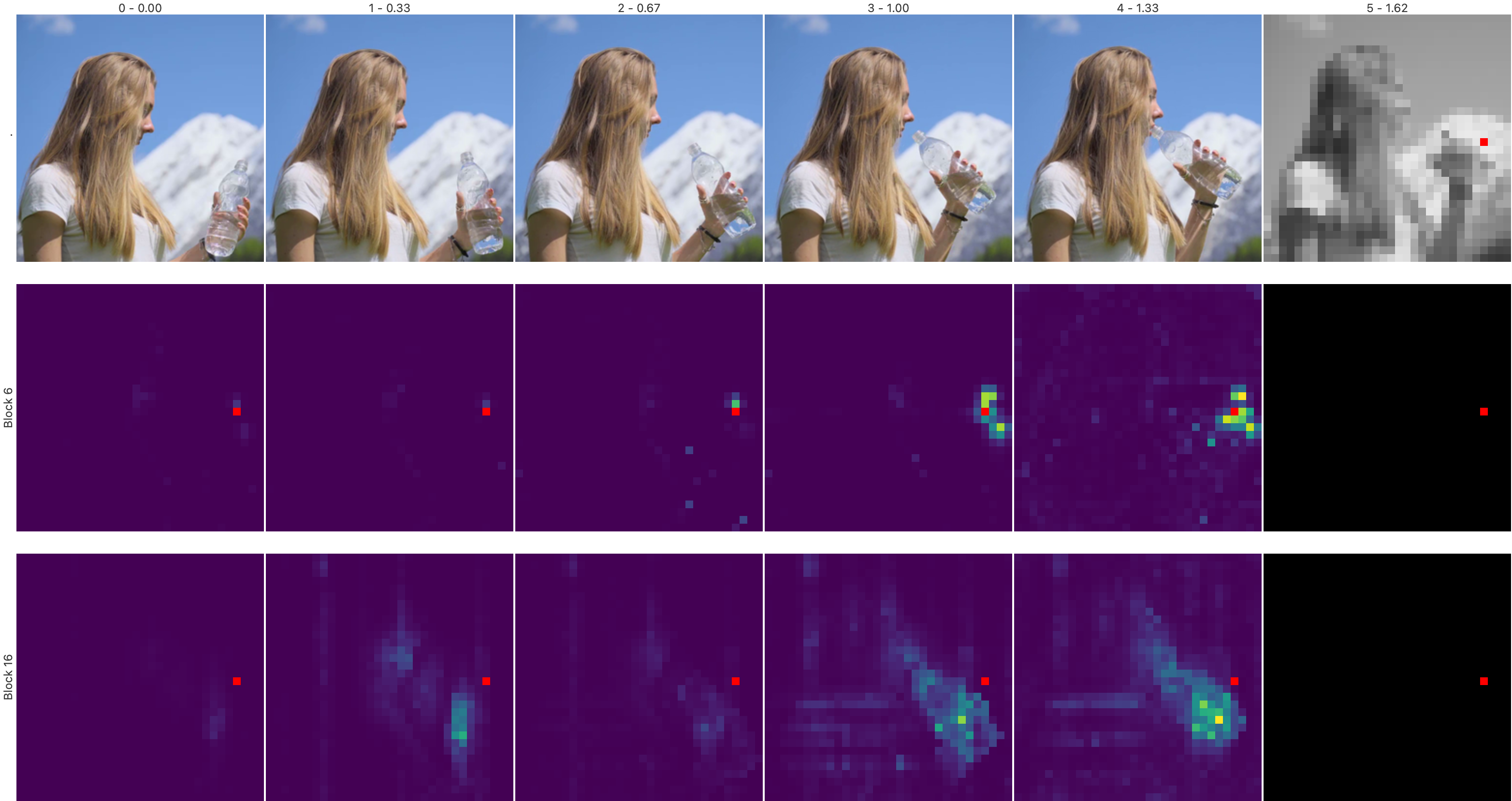
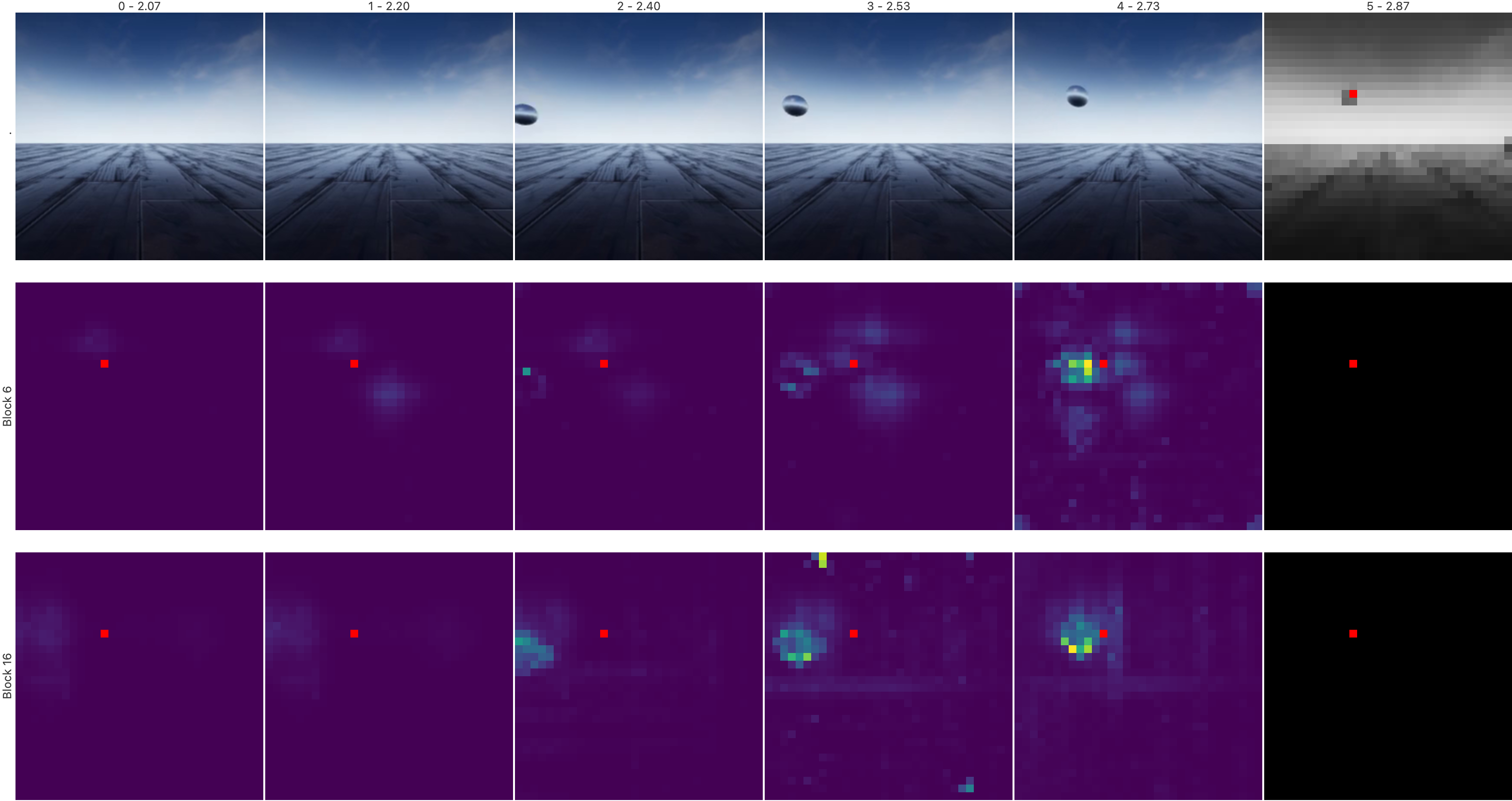
Figure 3: Visualization of cross attentions. The model tracks previous locations of the object of interest and its movement through the frames, as shown by the attention maps for two intermediate blocks.
Prediction Horizon and Autoregressive Rollouts
The model's ability to predict at varying temporal distances is assessed by comparing direct prediction to multi-step autoregressive rollouts. Direct prediction is more accurate at short intervals, while autoregressive rollouts maintain better performance at longer horizons, though all methods degrade as the prediction interval approaches one second.
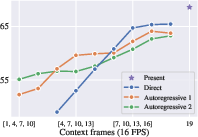



Figure 4: Cityscapes segmentation forecasting performance as context frames are shifted further from the target. Direct prediction is superior at short intervals, while autoregressive rollouts are more robust at longer horizons.
Ablation Studies
- Predictor Size: Larger predictors yield consistent improvements in both forecasting and physics understanding, indicating that temporal modeling is more parameter-intensive than spatial encoding.
- Training Data: Models trained on large, diverse datasets significantly outperform those trained on narrow or small-scale datasets, underscoring the importance of data diversity for generalist world modeling.
- Encoder Choice: DINOv2 provides superior features for downstream tasks compared to VAEs (optimized for reconstruction) and vision-LLMs (SigLIP2), validating the choice of a strong self-supervised encoder.
Action-Conditioned Planning
Fine-tuning the world model with action blocks enables effective planning in simulated RL environments (PushT, Wall, PointMaze). Pretraining on large-scale video data provides a clear advantage over training from scratch, with higher success rates in planning tasks. Freezing the base model and training only the action blocks is effective, supporting modular adaptation to new tasks.
Figure 4: Planning evaluations. Success rate of a planner that refines candidate trajectories by rolling them out in the latent space of the action-conditioned world model.
Implementation Considerations
- Resource Efficiency: The latent-space approach is orders of magnitude more efficient than pixel-space generative models, both in terms of parameter count and compute requirements.
- Scalability: The architecture supports variable input configurations, enabling deployment across diverse domains and tasks without retraining the encoder.
- Modularity: The separation of visual and temporal modeling allows for flexible adaptation to new conditioning signals (e.g., actions, language) with minimal fine-tuning.
- Limitations: Long-term prediction remains challenging, with performance degrading as the prediction horizon increases. The model cannot directly generate pixels, limiting its use in applications requiring high-fidelity video synthesis.
Implications and Future Directions
The results demonstrate that large-scale, latent-space world models built atop strong self-supervised encoders can achieve high performance on a range of video understanding and control tasks, with significant gains in efficiency and modularity. This paradigm enables leveraging vast pools of unlabeled video data for generalist world modeling, with minimal reliance on expensive action-labeled datasets.
Future research directions include:
- Improving long-term prediction via stochastic modeling or sampling diverse futures.
- Exploring data curation strategies to further enhance generalization.
- Extending action-conditioned fine-tuning to real-world robotics and embodied AI.
- Incorporating language or other modalities as conditioning signals for more general agent control.
Conclusion
DINO-world establishes a compelling framework for scalable, efficient, and generalist video world modeling by leveraging a frozen DINOv2 encoder and a transformer-based latent predictor. The approach achieves strong results on dense forecasting, intuitive physics, and planning tasks, and provides a modular foundation for future research in world models, embodied AI, and multimodal understanding. The findings highlight the importance of large-scale pretraining, latent-space modeling, and architectural modularity for advancing the capabilities of video world models.

