- The paper presents a novel DRS algorithm that automates selection of decision-relevant concepts to minimize state abstraction error.
- It derives theoretical bounds linking abstraction error to value loss and demonstrates robust performance improvements across RL tasks.
- Comprehensive empirical evaluations confirm its scalability, efficiency, and enhanced interpretability in both simulated and real-world environments.
Selecting Decision-Relevant Concepts in Reinforcement Learning
Introduction
Concept-based models in RL integrate interpretability and decision-making by mapping high-dimensional state observations to human-understandable binary concepts, on which policies are conditioned. Traditionally, the selection of concept sets has relied on labor-intensive expert engineering and iterative evaluation to ascertain their relevance for sequential tasks. This process is costly, non-scalable, and lacks performance guarantees. The paper "Selecting Decision-Relevant Concepts in Reinforcement Learning" (2604.04808) formulates the concept selection challenge formally, recasting it in terms of state abstraction to select concepts most pertinent to decision distinctions required for optimal performance. The authors present algorithmic advances—the Decision-Relevant Selection (DRS) framework and variants—for automatic concept subset selection, derive bounds linking abstraction error to agent performance, and offer extensive empirical validation on RL and real-world health environments.
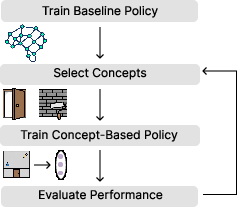
Figure 1: The canonical pipeline for training concept-based policies requires repeated manual selection, training, and evaluation of concept subsets—a process this work automates.
The central premise is that a concept is decision-relevant if its removal causes states requiring different actions to be aggregated, leading to suboptimal policies. Formally, each concept defines a partition over the state space; proper concept selection minimizes state abstraction error—that is, it aims for a representation such that all states with identical concept values have near-identical action-value profiles under the optimal policy.
The authors formalize the concept selection problem as a constrained combinatorial optimization: from a bank of candidate binary concepts, select a subset of size k that minimizes the maximum Q-abstracted error among pooled states. This selection is shown to be NP-hard, reducible to weighted maximum coverage. They connect the abstraction error ϵ induced by a given concept set to value function loss using the following bound: for all states s,
Vπ∗(s)−Vπc∗(s)≤(1−γ)22ϵ
where πc∗ is the optimal policy operating over concept predictions.
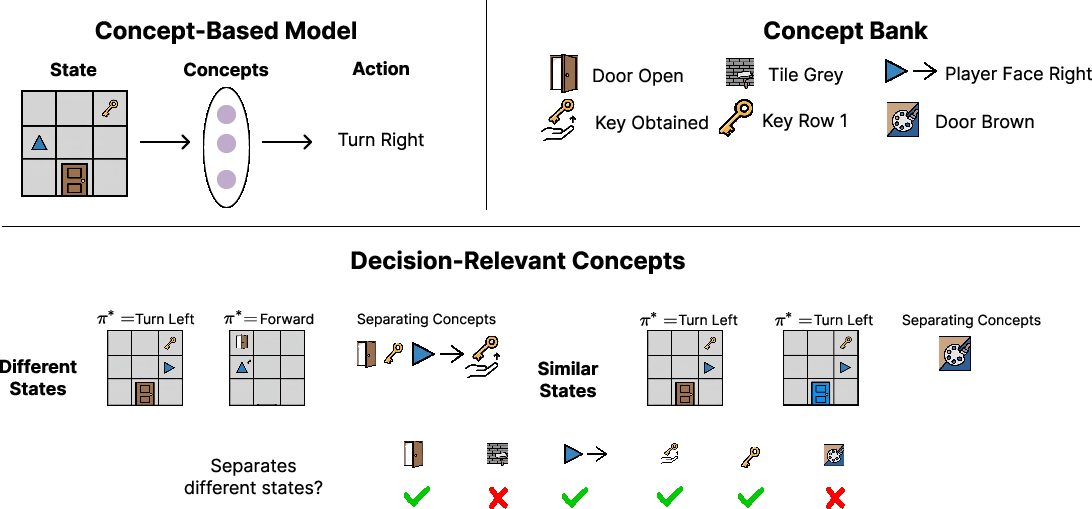
Figure 2: Decision-relevant concepts sharply separate states with distinct decision consequences. The approach provides performance guarantees rooted in abstraction theory.
Decision-Relevant Selection Algorithms
The DRS algorithm, and its extension DRS-log for imperfect predictors, optimize over sampled pairs of states from RL rollouts, enforcing explicit separation constraints for state pairs with distinct optimal actions. The objective is a mixed-integer (or nonlinear) program minimizing maximum abstracted Q-difference while controlling the number of selected concepts.
Perfect Concept Predictors: DRS computes constraints by counting disagreements over binary concept assignments. For state pairs with differing optimal actions, at least one selected concept must assign them different values.
Imperfect Concept Predictors: DRS-log integrates predictor accuracy, constraining expected state separation probabilistically using the accuracy profile δj for each concept. A logarithmic relaxation makes the constraints concave and efficiently optimizable.
Robustness theorems establish that DRS maintains tight abstraction errors (and thus, strong value bounds) under Q-estimation noise. However, the worst-case abstraction error under adversarial concept noise is inescapable, motivating stochastic assumptions in practice.


Figure 3: DRS substantially outperforms random, variance, and greedy baselines in RL settings with both perfect and imperfect concept predictors.
Empirical Evaluation
DRS consistently achieves superior or optimal normalized rewards across multiple environments (CartPole, MiniGrid, Pong, Boxing, Glucose) compared to baselines. In settings where concepts are perfectly predicted, DRS yields up to 159% improvement over alternatives, underscoring the importance of proper selection. When concept predictors are imperfect, DRS and DRS-log maintain dominance or parity, demonstrating robustness to predictor noise.
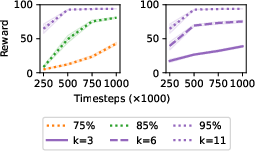
Figure 4: In MiniGrid, concept predictor accuracy controls learning speed, and the number of selected concepts sets the attainable performance ceiling.
Ablation reveals that both the number and accuracy of selected decision-relevant concepts are critical—training speed increases with higher predictor accuracy, while the attainable policy reward depends primarily on the expressivity (number) of concepts.

Figure 5: Increasing the number or accuracy of concepts drives higher policy performance; both axes must be sufficient for near-optimality.
Test-Time Intervention
The DRS framework is particularly effective for human-AI collaboration paradigms (e.g., clinical settings) where users can correct mispredicted concept values at deployment. With test-time intervention, DRS-selected concepts amplify reward gains over alternative selection strategies, as intervening on highly decision-relevant concepts produces maximal policy improvement.
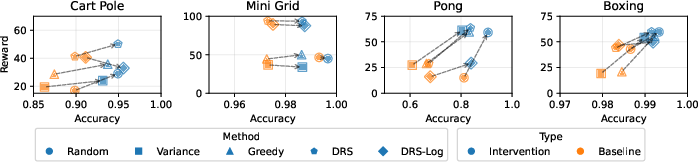
Figure 6: DRS consistently provides the highest reward both before and after intervention across environments, demonstrating improved utility for human correction at test time.
This substantiates the theoretical monotonicity claims: as the fraction of accurate pivotal concepts increases (either through predictor improvement or human correction), policies grounded in decision-relevant concepts benefit disproportionately.
Comparison With Manual and LLM-Based Concept Engineering
On supervised datasets such as CUB, DRS recovers or even augments manually curated concept sets, while achieving equivalent performance with fewer concepts. This demonstrates that the framework is not only effective in sequential RL but generalizes to classical concept bottleneck settings, outperforming heuristic selection by maximizing coverage of necessary label distinctions.
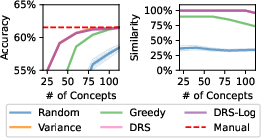
Figure 7: DRS-selected concepts can closely match or improve upon manually curated sets (left), using fewer features (right).
Computational Efficiency
All concept selection algorithms run in under ten minutes, several orders of magnitude faster than comprehensive policy training, and scale favorably even for high-dimensional concept banks due to effective state sampling.

Figure 8: Comparison of concept selection algorithm runtimes. DRS and DRS-log add modest computational overhead.
Practical and Theoretical Implications
Automating concept selection in concept-based RL leads to dramatic improvements in policy interpretability and reliability without sacrificing task performance. DRS directly addresses concerns of scalability, reproducibility, and the "no performance guarantee" limitation of manual engineering. The framework strengthens the deployment of interpretable agents by ensuring that all dimensions in the compacted state representation are substantiated by demonstrable decision-relevance.
On the theoretical side, the bridging of state abstraction theory with practical concept selection is significant: abstraction errors are linked tightly to agent value loss, providing actionable tools for performance certification and analysis.
Future Directions
Potential research avenues include:
- Extension of the selection framework to continuous and compositional concepts.
- Online or adaptive concept selection in non-stationary environments.
- Integration with self-supervised or unsupervised discovery of human-aligned concept banks via large foundation models.
- Human-in-the-loop selection paradigms optimizing for both statistical and causal relevance.
Conclusion
The principled approach to automated concept selection in RL developed in this work substantively reduces manual cost and increases agent interpretability and intervention efficacy. The DRS framework achieves tight value bounds, matches or exceeds the performance of engineered concept sets, and is robust to imperfect predictors—making it of high practical and theoretical interest for scalable interpretable RL research and deployment.

