- The paper demonstrates that XAI-based corrections, notably CFKD and RR-ClArC, significantly improve worst-group accuracy in deep image classifiers.
- It shows that methodologies relying on counterfactual generation and robust optimization outperform non-XAI methods under severe group imbalance.
- Empirical results highlight the critical role of reliable group annotation and adaptive validation metrics for deploying robust, shortcut-resistant models.
Reproducibility and Comparative Evaluation of Spurious Correlation Mitigation and Correction in Deep Image Classifiers
Introduction
The incidence of shortcut learning and non-causal feature exploitation—characterized as the Clever Hans effect, spurious correlation reliance, or group-distributional non-robustness—remains a major barrier for reliable deployment of deep neural networks in high-stakes applications. While multiple communities have independently developed correction frameworks such as DRO, IRM, shortcut learning mitigation, and robust optimization, domain-dependent jargon, supervision requirements, and evaluation paradigms obscure holistic understanding and cross-domain benchmarking. This paper provides a reproducibility study that systematically re-implements and evaluates a spectrum of correction strategies, both XAI- and non-XAI-based, within imaging domains under severe group imbalance and data scarcity constraints (2604.04518).
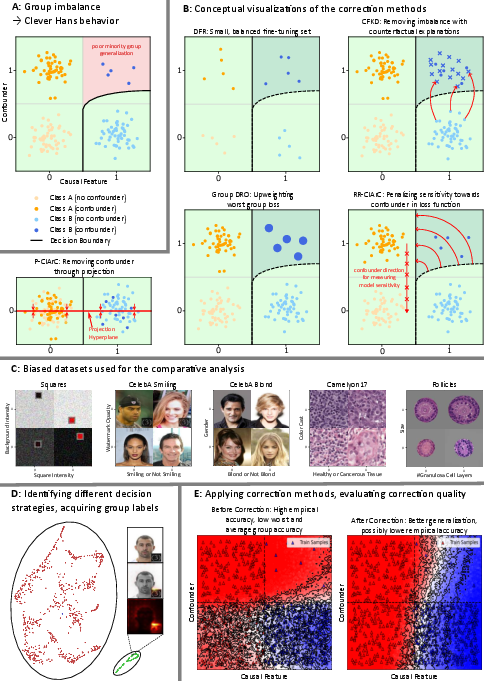
Figure 1: Schematic overview of how confounders create systemic non-robustness (Panel A), the discrete methodological space for corrections (Panel B), dataset axes (Panel C), XAI-driven strategy annotation (Panel D), and decision boundary shifts after correction (Panel E).
Taxonomy and Mechanisms of Shortcut Corrections
The authors categorize correction methods according to their reliance on group/causal annotations, type of confounder intervention (objective modification, representation transformation, dataset augmentation), and degree of explainability dependence:
- XAI-Based Correction: Layer-wise relevance propagation (LRP) provides local input relevance heatmaps; SpRAy leverages spectral clustering on attribution maps for automatic group discovery; concept activation vectors (CAV/PCAV) analytically extract confounder directions in model latent space; ClArC family (A-, P-, RR-ClArC) performs causal/intervention projections and gradient regularization to suppress confounder traces; counterfactual explainers generate interpretable data augmentations for distillation.
- CFKD Pipeline: A closed-loop framework iteratively augments the training set with counterfactuals. Counterfactuals not recognized as true instances of the target class by a teacher (oracle) are relabeled and supplement minority group density, thus directly counteracting shortcut-induced imbalance.
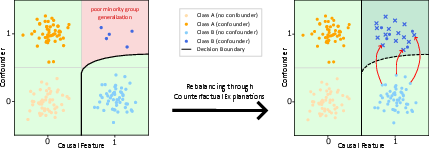
Figure 2: Dataset rebalance through CFKD: distribution shift by synthetic counterfactuals introduces formerly underrepresented group samples, eliminating the spurious class-confounder link.
- Non-XAI Methods: DFR performs last-layer fine-tuning on manually subsampled, balanced groups; Group DRO optimizes the worst-case group loss via reweighted objectives. Each method’s efficacy strongly depends on quality of group annotation and validation mechanism.
Experimental Protocol
Experiments span both synthetic (Squares) and real-world (CelebA, Camelyon17, Follicles) datasets, systematically introducing hard bias settings where the confounder’s spurious correlation is near total for majority groups and minority group samples are extremely sparse in both training and validation partitions. The tasks involve binary classification with two-level confounder factors, allowing controlled assessment of generalization and worst-group performance.
Dataset design and poisoning mechanisms are visualized in:
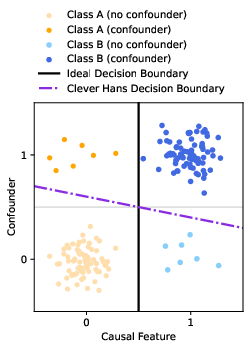
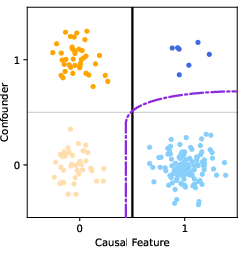
Figure 3: Symmetric and asymmetric group allocation visualizations for the experimental datasets.
Empirical risk minimization (ERM)-trained students act as initial, systematically shortcut-biased classifiers. Correction methods are applied post-hoc to identical initial models for strict comparability. Validation metrics prioritise average group accuracy (AGA) and worst group accuracy (WGA) rather than naive empirical accuracy, which would obscure Clever Hans failure.
The study leverages LRP to expose pixel-level shortcut reliance. For instance, in CelebA Smiling with artificial watermark confounders, heatmap overlays reveal that the classifier’s attributions focus on the watermark for “Smiling” prediction, demonstrating clear non-causal reasoning:

Figure 4: Heatmap overlays showing model reliance on watermarks as opposed to facial regions for class decision, confirming shortcut learning.
SpRAy is used for dataset-scale aggregation of attribution maps, with t-SNE embedding visualizations evidencing distinct clusters corresponding to causal and non-causal strategies:
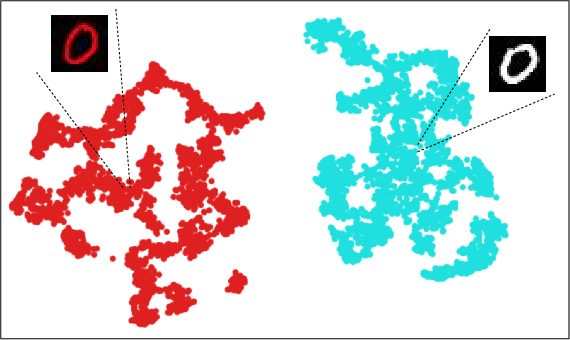
Figure 5: t-SNE embedding of LRP attributions in Colored MNIST, manifesting cluster separation between true digit and spurious color-based decision circuits.
Across all datasets, XAI-based corrections (especially CFKD and RR-ClArC) consistently outperform non-XAI baselines in terms of AGA and, crucially, worst-group generalization. For example, on strongly shortcut-dominated Squares, RR-ClArC improves average group accuracy from 51.1% (uncorrected) to 79.6%, while CFKD achieves 94.5%. Group DRO reaches 61.3%, and DFR yields only 52.1%. Similar trends hold for more realistic datasets where the confounder is harder to separate and minority data even scarcer.
Qualitative visual analyses of decision boundaries for synthetic data further corroborate that only XAI-based corrections successfully realign model confidence in the direction of the underlying causal feature.
SpRAy-derived confounder/group annotation proves robust only for simple, visually salient shortcuts; its performance collapses for complex, ambiguous, or continuous-valued confounders in real datasets, significantly reducing correction efficacy. This demonstrates the acute importance and bottleneck role of reliable group-finding methods.
Implications for Robust Model Deployment
Several empirical insights have major ramifications for both research methodology and practical deployment in real-world settings:
- Label Supervision Dependency: Correction efficacy for all methods except CFKD is sharply constrained by accuracy and coverage of group/confounder labels. Automated group annotation (e.g., via SpRAy) remains non-robust outside idealized settings.
- Validation Instability: Model selection based on group-averaged validation accuracy is unreliable with scarce minority-group samples—hyperparameter optimization can promote overfitting or select spurious solutions.
- Superior Efficacy of CFKD: By generating synthetic counterfactuals to fill minority group support, CFKD effectively bypasses group label dependence and validation misalignment, but at significant computational cost and with reliance on performant counterfactual explainers.
- Trade-off Between Correction Power and Efficiency: While RR-ClArC and CFKD achieve maximal worst-group accuracy, they incur considerable computational and tuning overhead versus DFR and Group DRO, which, although efficient, rarely suffice in the hard-bias regime.
For illustrative clarity, the study provides visualizations of the dataset designs and model-annotation overlays:
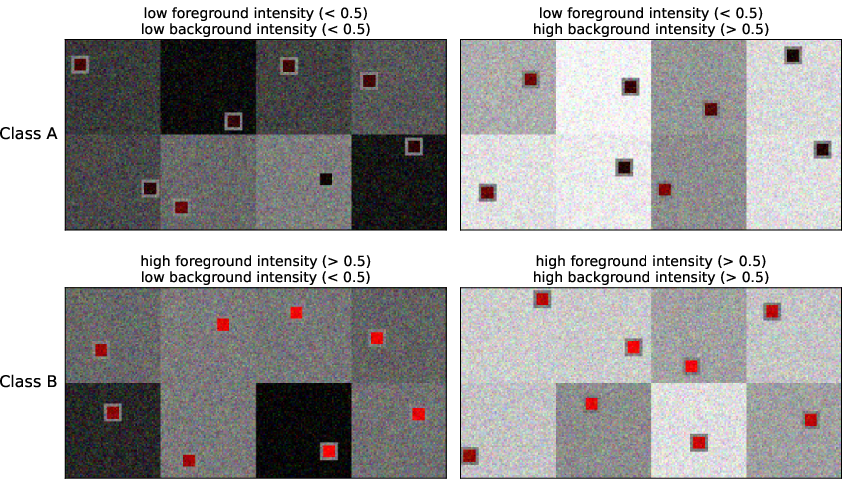
Figure 6: Realizations from the synthetic Squares dataset, indicating clear separation of causal (foreground color) and confounder (background color) features.

Figure 7: CelebA Smiling samples illustrating watermark opacity as confounder, with subsampled groups marked.
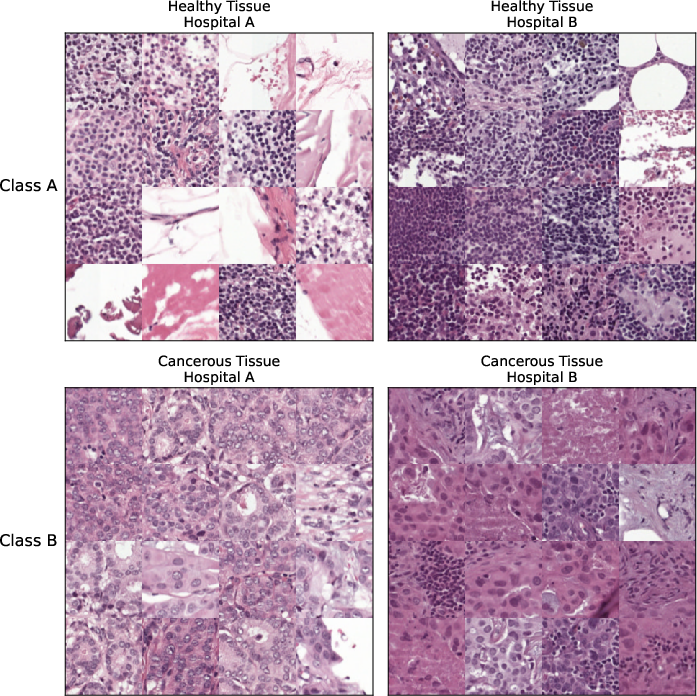
Figure 8: Camelyon17 group realizations, showing color-cast confounder aligned with hospital of origin.
Limitations, Theoretical Implications, and Future Work
The findings highlight the intractability of principled group-based correction in the presence of both feature entanglement and annotation scarcity—practically ubiquitous in medical and safety-critical imaging. Theoretically, these results challenge the assumption that group-level supervision or even reliable group discovery is tenable in operational pipelines. Developments in unsupervised or self-supervised confounder discovery, generally applicable counterfactual explainers, and validation metrics robust to extreme class/group imbalance are needed.
Additionally, the extension to multi-class, multi-confounder scenarios remains unresolved, and reproducibility under architecture shifts (beyond ResNet-18) and other data modalities is unaddressed by this experimental framework.
Conclusion
This work delivers an authoritative and reproducible empirical benchmark demonstrating that XAI-based bias mitigation—particularly counterfactual knowledge distillation—most consistently achieves robust, group-balanced generalization in shortcut-dominated regimes, given tractable confounder annotation or effective synthetic generation. Non-XAI alternatives (DFR, Group DRO) rarely suffice with extreme minority underrepresentation. The evaluation articulates the practical barriers imposed by subgroup annotation bottlenecks (e.g., limitations of SpRAy), model selection under data starvation, and computational burden of fully iterative counterfactual pipelines. The results argue that progress in confounder-agnostic robustification and better-automated XAI-group annotation are central to trustworthy, distributionally reliable DNN deployment. Future developments should also address scalable annotation, multi-confounder correction, and extension to other domains and modalities.