- The paper introduces a multiplicative adaptation approach (GAIN) that prevents catastrophic forgetting by preserving the pretrained weight subspace.
- Empirical results show that GAIN-FFN improves cross-domain performance with 7–13% better perplexity compared to additive methods like LoRA.
- The method eliminates the traditional adaptation–forgetting tradeoff and integrates seamlessly with existing models without inference overhead.
GAIN: Multiplicative Modulation for Domain Adaptation
Motivation and Problem Statement
Domain adaptation in LLMs is severely limited by catastrophic forgetting—adaptation to new domains, especially by means of full fine-tuning or parameter-efficient methods such as LoRA, often degrades the model's performance on previously mastered domains. This degradation primarily stems from the injection of new directions ("intruder dimensions") in the weight space outside the pretrained feature subspace, as shown in prior literature (Shuttleworth et al., 2024). Existing approaches, including regularized LoRA, can mitigate but not eliminate this effect, and always trade-off in-domain adaptation for stability.
GAIN (Gain modulation for Adaptation Intended for No-forgetting) addresses this structural flaw by proposing a strictly multiplicative approach to LLM adaptation. The method exploits the capacity of pretrained models to re-emphasize or suppress features already encoded, avoiding the introduction of new, potentially destructive directions. This is formally underpinned by the insight that scaling model weights via a diagonal matrix S leaves the model's output subspace invariant, precluding structural forgetting.
Methodology
Multiplicative Modulation Principle
GAIN reformulates adaptation as multiplicative scaling:
Wnew=S⋅W,
where W is a pretrained weight matrix and S is a learned diagonal matrix (parameters si with S=diag(s1,...,sn)). This is instantiated for both the attention output projection (GAIN) and the feed-forward down-projection (GAIN-FFN):
- GAIN: Scales the rows of the attention output projection WO.
- GAIN-FFN: Scales the columns of the FFN down-projection Wdown.
As all pretrained model parameters are frozen, only the scaling matrices are learned. Post-training, S is absorbed into the existing weights, incurring zero inference overhead.
Structural Forgetting Prevention
The central proposition is that for any diagonal S, the output subspace of Wnew=S⋅W,0 remains a subset of the pretrained Wnew=S⋅W,1—ensuring that all outputs are contained within the original output space. Formally,
- Left-multiplication by Wnew=S⋅W,2 preserves the row space: Wnew=S⋅W,3,
- Right-multiplication preserves the column space: Wnew=S⋅W,4.
This guarantees that no intruder dimensions are created, structurally preventing both backward forgetting and forward interference.
Empirical Analysis
Single-Domain Adaptation
Evaluation across 774M to 70B parameter LLMs shows that GAIN-FFN matches or exceeds LoRA's in-domain adaptation strength, with strikingly different effects on cross-domain generalization. While LoRA degrades performance on previous domains by Wnew=S⋅W,5--Wnew=S⋅W,6 (PPL), GAIN-FFN consistently yields positive transfer, improving prior domain perplexity by Wnew=S⋅W,7–Wnew=S⋅W,8. These effects are robust at both default and aggressive learning rates; LoRA demonstrates instability, catastrophic forgetting, or overfitting with increased rates, while GAIN maintains in-domain improvement and negligible cross-domain loss increase.
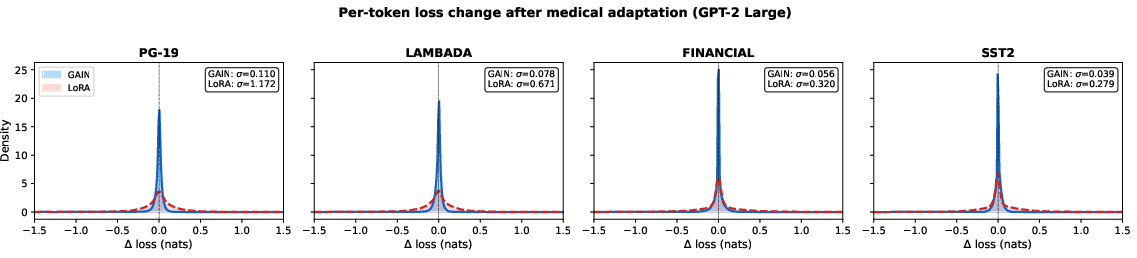
Figure 1: Per-token loss change on four unrelated domains after medical adaptation (GPT-2 Large). GAIN (Wnew=S⋅W,9) is W0 narrower than LoRA (W1).
Sequential Multi-Domain Adaptation
The stability-plasticity dilemma is empirically resolved in the multiplicative regime. Across sequential adaptation tasks (eight diverse domains, five model architectures), GAIN produces cumulative positive transfer to earlier domains, whereas LoRA rapidly accumulates catastrophic interference. GAIN’s post-adaptation PPL consistently improves for every domain previously encountered, whereas each subsequent LoRA adaptation overwrites prior knowledge.
Forgetting–Adaptation Tradeoff
LoRA and similar additive methods universally manifest a forgetting–adaptation Pareto frontier: reducing one exacerbates the other, requiring hyperparameter tuning and explicit regularization (e.g., L2, domain boundary signals). GAIN eliminates this tradeoff—strong adaptation and domain retention are simultaneously achievable, without regularization or tuning. The GAIN adaptation/retention curve exists entirely in the beneficial regime; increasing learning rates amplifies both current and previous domain performance improvements (within safe bounds).
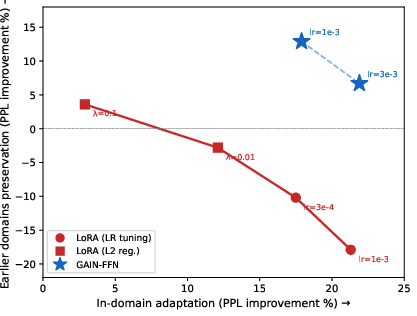
Figure 2: LoRA's forgetting-adaptation tradeoff. Red points are LoRA with different learning rates and L2 regularization strengths (W2). GAIN-FFN (blue stars) operates in a different regime—the entire curve lies above zero.
Loss Landscape Analysis
Loss landscape interpolations reveal that GAIN maintains flat cross-domain loss when traversing the adaptation direction, while LoRA produces sharp increases in cross-domain error as one moves away from the pretrained weights. In the multiple-domain case, GAIN sketches an orthogonal structure—simultaneous adaptation in two (or more) domains imposes minimal cross-domain cost, as the scaling directions are mostly uncorrelated.
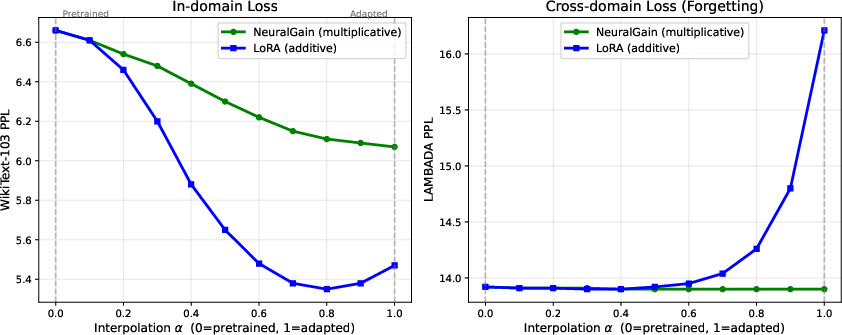
Figure 3: Loss landscape interpolation on Mistral-7B. Left: in-domain PPL decreases for both. Right: GAIN's cross-domain loss is flat; LoRA's rises steeply.
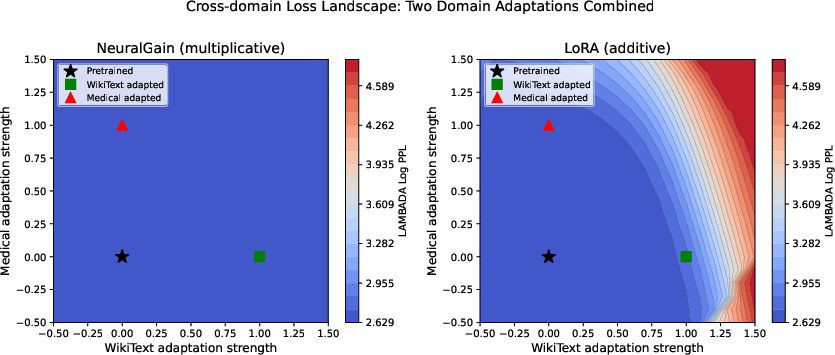
Figure 4: Cross-domain loss when WikiText and Medical adaptations are combined. Left: GAIN—uniform blue; any combination preserves LAMBADA. Right: LoRA—red regions appear when adaptations are combined.
Extension: Downstream Benchmarks and Scaling
GAIN-FFN consistently preserves or boosts accuracy on out-of-domain benchmarks (ARC, BoolQ, HellaSwag, PIQA, WinoGrande, etc.), even as LoRA damages them (up to W3 degradation on BoolQ; Table 4 of the main text). This behavior holds across small and large models (e.g., GPT-2 Large, Llama-2-70B), with GAIN's parameter count modest and constant per layer. Even with W4 more adaptation data, positive transfer persists.
Theoretical Scope and Broad Implications
The elimination of structural forgetting is attributed to the multiplicative parameterization—not to the precise matrices chosen. Comparative experiments with other multiplicative methods, such as (IA)W5 (Chakrabarty et al., 2022), confirm that scaling keys or activations, rather than outputs, yields comparable no-forgetting properties. This isolates the principle—multiplicative modulation as structural safeguard—rather than any specific parameterization, as the decisive factor.
Limitations and Future Directions
GAIN's preservation guarantee presumes that pretrained features suffice for the new domain; it cannot synthesize genuinely new semantic features absent from W6. Empirical results suggest that scaling is sufficient for very diverse domains (medical, financial, QA), but scenarios where new concepts must be composed or invented might expose a ceiling. Further, adaptation sequences longer than eight domains could necessitate regularization or normalization to ensure scaling factors remain positive and within a reasonable range, particularly at aggressive learning rates.
Conclusion
GAIN introduces a principled multiplicative adaptation protocol for LLMs, eliminating structural forgetting by construction. Strong numerical results demonstrate simultaneous gains in domain adaptation and cross-domain retention, with all retention/adaptation tradeoff curves compressed into the strictly beneficial regime. This multiplicative design paradigm is independently validated across model families, domains, parameter counts, and data scales. The main implication is that, for continual and parameter-efficient adaptation of LLMs, structurally preserving the pretrained space is both necessary and sufficient to break the adaptation–forgetting bottleneck that plagues additive approaches.
These findings open theoretical and practical avenues: hybridizing multiplicative and sparse additive adaptation for truly new features, further understanding feature sharing/orthogonality in learned LLM representations, and extending positive transfer regimes to even broader continual learning scenarios.

