- The paper demonstrates that tuning a single initial state matrix per recurrent layer improves performance, achieving zero inference overhead compared to LoRA.
- It employs a parameter-efficient fine-tuning method validated on Qwen3.5-4B and FalconH1-7B, with improvements up to +27.1 pp in pass@1 metrics.
- The study underscores the state-expressiveness threshold hypothesis, highlighting the power of matrix-valued recurrent states for effective domain adaptation.
S₀ Tuning: Zero-Overhead Adaptation for Hybrid Recurrent-Attention LMs
Overview and Methodological Innovations
S₀ Tuning introduces a parameter-efficient fine-tuning (PEFT) approach for hybrid recurrent-attention LMs where adaptation is realized exclusively by tuning a single initial state matrix per recurrent layer, without modifying any weight matrices. This method exploits a unique adaptation surface present in modern hybrid architectures—matrix-valued recurrent state, which is absent in pure Transformers. The central claim is that tuning this initial state (S0) allows for substantial downstream performance improvements with zero inference overhead. The approach is validated on Qwen3.5-4B (GatedDeltaNet hybrid) and FalconH1-7B (Mamba-2 hybrid), demonstrating superiority or parity with strong LoRA baselines.
The technique operates by replacing the default zero initialization of the recurrent state with a learned value, optimized via common supervised objectives. All model weights remain frozen during and after adaptation. As a result, the inference cost is identical to the base model since the state perturbation is "absorbed" after the initial step.
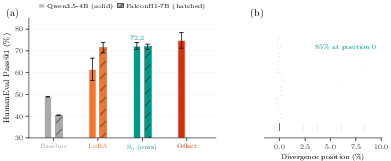
Figure 1: S₀ outperforms LoRA on Qwen3.5-4B and matches LoRA on FalconH1-7B; 85% of FAIL-to-PASS flips diverge at the very first generated character, underscoring S₀'s trajectory-steering effect.
Experimental Results and Numerical Comparisons
On HumanEval code-generation, S₀ tuning on Qwen3.5-4B yields a +23.6 pp improvement in pass@1 (72.2% vs. 48.8% baseline, 10 seeds), exceeding LoRA by +10.8 pp (p<0.001), with markedly reduced variance. On FalconH1-7B, S₀ achieves 71.8% (SD 1.3), statistically indistinguishable from LoRA (71.4%, SD 2.4) at current sample size, but without LoRA's weight merging and increased inference complexity.
A per-step "state-offset" variant further boosts Qwen3.5-4B to +27.1 pp but introduces per-token inference cost, highlighting the efficiency/accuracy tradeoff. In parameter-matched controls (LoRA rank 64, 12.6M parameters), LoRA's performance degrades (–15.5 pp), demonstrating S₀'s adaptation strength is not solely due to parameter count.
S₀ exhibits notable cross-domain transfer: MATH-500 sees +4.8 pp (p = 2e–5), and GSM8K +2.8 pp (p = 0.0003). No effect is detected on Spider (text-to-SQL), which aligns with the mechanistic account rooted in trajectory steering.
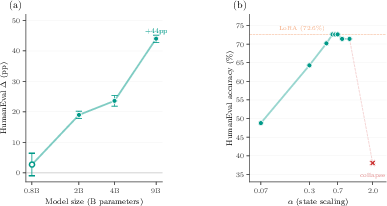
Figure 3: Performance gains with S₀ increase with model scale, indicating larger pre-trained models have more latent capability accessible via state initialization.
Mechanistic Analysis: Trajectory Steering and Recurrence
A salient empirical phenomenon is "first-character divergence": in 85% of cases where a formerly failed solution flips to correct (FAIL-to-PASS), the S₀-tuned and baseline completions diverge on the very first generated character. The cumulative effect is that all flips occur within the first 10% of the output sequence.
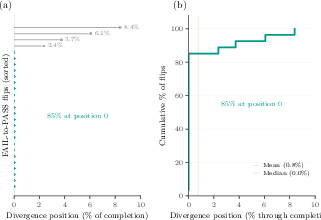
Figure 2: For 85% of FAIL-to-PASS flips, S₀-tuned and baseline completions diverge at the first generated character; all flips occur within the first 10%.
Persistence analysis shows that while S0's direct influence on output logits decays exponentially through the prompt (reaching a KL ratio of 0.03% at prompt end), its effect, "compressed" into the hidden state via recurrence, is sufficient to reliably steer the trajectory of greedy autoregressive decoding. This trajectory-steering behavior is not evident for PEFT methods that modify traditional weight matrices.
The efficacy of S₀ is tied to model architecture. Only state-rich (matrix-valued) recurrence, as in GatedDeltaNet and Mamba-2, provides sufficient adaptation expressiveness; diagonal-state architectures (Mamba-1) do not yield competitive results with this method, consistent with prior findings [galim_peft_ssm].
Practical Implications and Theoretical Impact
S₀ tuning eliminates the inference burden of adapter layers, weight merges, or batch-dependent state tracking. Loading a new task is reduced to swapping in a new set of initial recurrent state tensors (∼48 MB per task). This makes S₀ appealing for edge deployments and constrained-serving scenarios, especially when task data is scarce and execution verification is available.
The success of S₀ provides strong evidence for the state-expressiveness threshold hypothesis: only high-dimensional, matrix-valued recurrent states offer enough capacity for effective PEFT, distinguishing hybrid and advanced SSM architectures from traditional RNNs or diagonal-SSMs [galim_peft_ssm]. Its failures, e.g., for text-to-SQL tasks, further delineate the boundaries of in-context steering achievable by single-step state adaptation.
For practitioners, S₀ can serve as a first-line adaptation method in settings with limited data, high inference efficiency requirements, and availability of verified exemplars. The method is data-efficient; as few as 25 correct completions suffice for stable gains.
Limitations and Future Directions
S₀'s advantage is currently mostly restricted to code and (to a lesser extent) math problem solving. Larger and more varied benchmarks are needed to fully map the boundaries of this adaptation surface. The methodology requires verified completions for tuning, which can be expensive to obtain for some domains. The approach is less effective on tasks with low initial-token diversity or highly structured sequential outputs (e.g., Spider text-to-SQL).
Follow-up work might explore:
- Richer recurrence designs: Investigating other forms of state-space models or non-linear update rules to maximize adaptation surface expressiveness.
- Multi-task and continual adaptation: How state-initialization interacts with shared representations when multiple tasks are loaded/combined.
- Robustness and safety: Assessing how trajectory steering via S0 compares to weight adaptation in terms of model brittleness or susceptibility to out-of-distribution prompts.
Conclusion
S₀ tuning demonstrates that matrix-valued recurrent state in hybrid LMs provides a powerful, underutilized adaptation surface for zero-overhead parameter-efficient fine-tuning. For key open-weight hybrid architectures (Qwen3.5, FalconH1), the method offers statistically significant and practically meaningful performance improvements over LoRA and prefix tuning, especially in low-data, fast-adaptation regimes. These results motivate further exploration of expressive, state-based adaptation mechanisms as foundational tools for efficient model deployment and compositional generalization in next-generation sequence models.
References:
- "S0 Tuning: Zero-Overhead Adaptation of Hybrid Recurrent-Attention Models" (2604.01168)
- Additional citations as discussed in the text.

