- The paper introduces the BiTDiff framework, a groundbreaking model leveraging BiMamba-Transformer diffusion to generate fine-grained, 3D conducting motions.
- It presents the CM-Data dataset, the first extensive 3D motion collection with detailed hand, body, and facial expressions for music-synchronized performances.
- Experimental results show that BiTDiff significantly outperforms baselines in fidelity, diversity, and beat alignment while efficiently synthesizing long-horizon sequences.
Introduction
The automation of expressive 3D conducting motion, synchronized with music, is technologically significant for music education, digital human animation, and human–AI co-creation. Previous approaches struggle with two dominant challenges: the lack of a comprehensive, high-fidelity dataset capturing fine-grained hand, body, and facial expressions of conductors in 3D, and the absence of efficient, high-quality generative models supporting temporally consistent long-sequence motion synthesis. This paper presents BiTDiff, which addresses both data and methodology deficiencies through the introduction of the CM-Data dataset and a BiMamba-Transformer Diffusion model supporting joint-level motion editing and state-of-the-art generation fidelity.
Dataset: CM-Data Construction and Properties
A major contribution is CM-Data—the first large-scale, fine-grained, public 3D conducting motion dataset. CM-Data is built on a robust, quality-oriented acquisition pipeline that utilizes multi-stage model fusion (PromptHMR for coarse body, HaPTIC for articulate hands, and SPECTRE for facial dynamics), resulting in temporally stable SMPL-X sequences with full-body coverage, detailed hand articulation, and facial expression:

Figure 1: The CM-Data pipeline captures both coarse and fine motion details, including hand and facial expressivity, with accurate temporal stability visualized in multiple views.
The dataset contains roughly 1,500 curated and processed samples totaling about 10 hours, spanning a diversity of conductors, genres, and scenarios (orchestral, choral, solo performances). It provides detailed per-frame annotation (root translations, 6D joint rotations), supporting scalable benchmarks for modeling expressive and realistic conducting.
Methodology: BiTDiff Framework
Generative Model
The generative pipeline is formalized as a conditional diffusion process mapping music features to SMPL-X motion sequences. The model leverages a hybrid BiMamba–Transformer architecture:
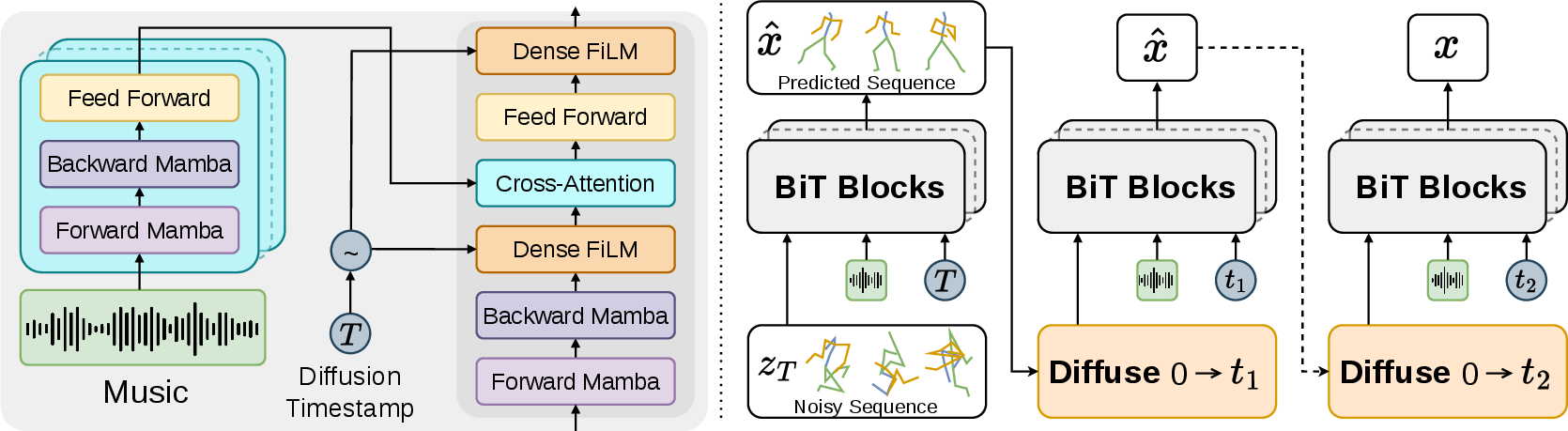
Figure 2: System overview—BiTDiff’s architecture (left) combines BiMamba for intra-modal temporal modeling and a Transformer block for cross-modal music-motion alignment; the right panel visualizes flexible inference with diffusion steps.
- BiMamba processes intra-modal dependencies (i.e., fine-grained temporal structure in motion or music) in both forward and backward directions, enhancing context modeling for non-causal tasks and supplying long-sequence modeling efficiencies that outperform classical autoregressive or transformer-only schemes.
- Transformer is employed as a cross-modal attention module, integrating global musical context to refine alignment between musical structure (beat, chroma, MFCCs) and expressive motion cues.
Auxiliary training objectives include hand/body-specific forward kinematics (FK) loss terms, promoting precise physical consistency, particularly for articulate hand and upper-body movements, and a velocity loss to encourage temporal smoothness. Joint training with classifier-free guidance enables musically controllable sampling.
Non-Autoregressive, Efficient Long-Horizon Synthesis
BiTDiff generates full-length sequences (up to 4,096 frames) non-autoregressively, avoiding exposure bias and inefficient segment-level inpainting. The bidirectional Mamba backbone ensures efficient memory scaling and uninterrupted long-term coherence.
Motion Editing Capabilities
The model supports fine-grained, training-free motion editing via masked denoising—for instance, temporal in-betweening, streaming continuation, lower-body synthesis conditional on upper-body input, and body-to-hand/face enrichment—all of which facilitate downstream interactive or creative workflows.
Experimental Results
BiTDiff is empirically validated against leading baselines in 2D conducting, 3D dance, and gesture generation on CM-Data, demonstrating clear superiority across fidelity (FID), diversity (DIV), and beat alignment (BAS):
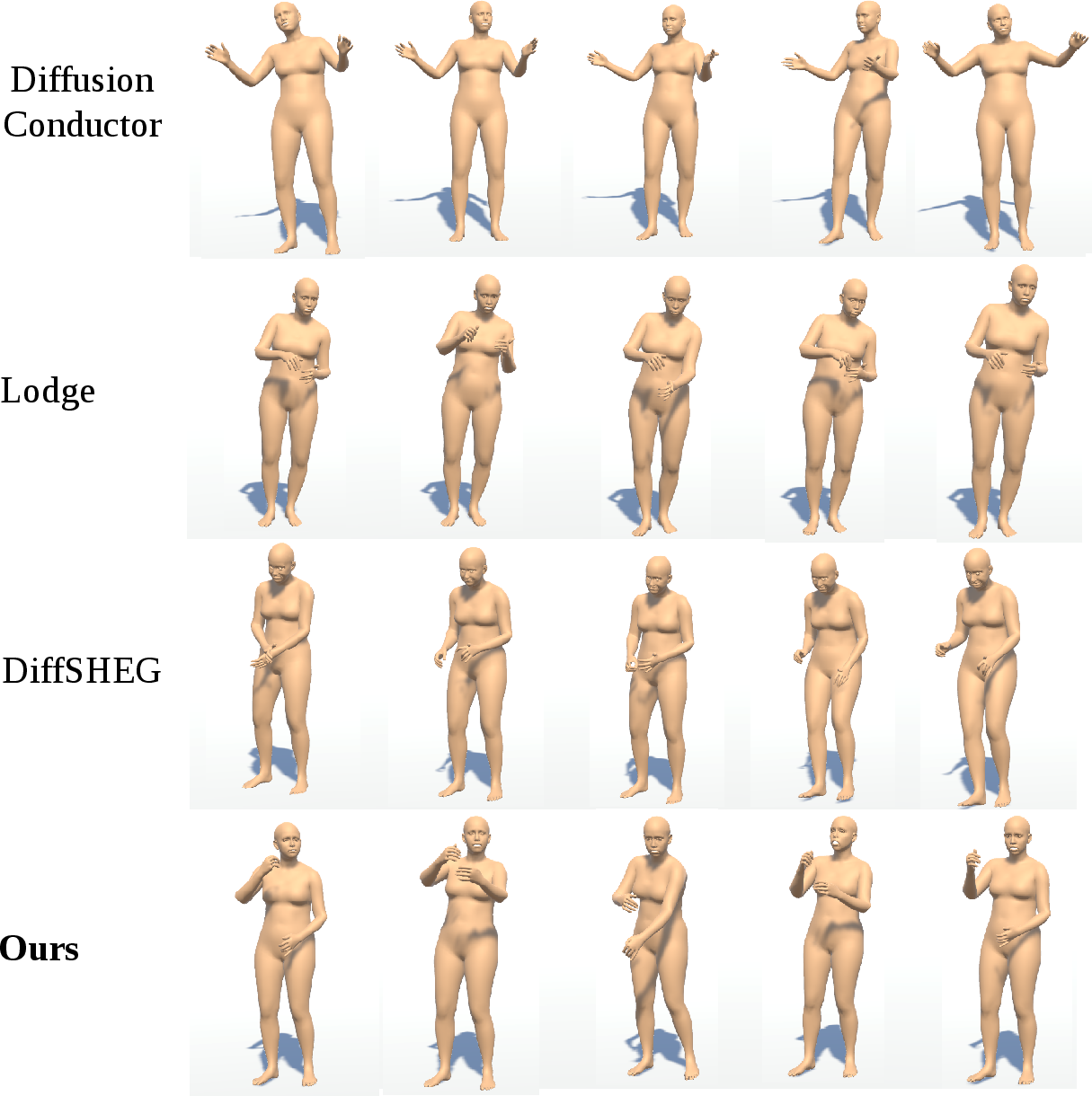
Figure 3: Qualitative results highlight the expressivity, temporal stability, and fine-grained detail of BiTDiff-generated motions compared to SOTA baselines.
Notably, BiTDiff reduces average FID by 18.1, increases DIV by 2.5, and improves BAS by 2.0 relative to the best prior method (Lodge). Latency analysis shows that BiTDiff achieves the fastest inference times, especially advantageous for long-sequence practical deployment. User studies with conducting experts confirm the model’s superiority in synchronization, fidelity, and especially in creativity (4.17/5).
Ablation Studies
Ablation indicates strong contributions from both the velocity loss (improved body dynamics) and the hand/body FK decomposition (marked improvement in hand motion realism). The hybrid architecture (BiMamba-Transformer) provides the optimal trade-off between quality and efficiency: unidirectional or pure Transformer backbones yield either degraded expressivity or increased inference cost, respectively.
Motion Editing
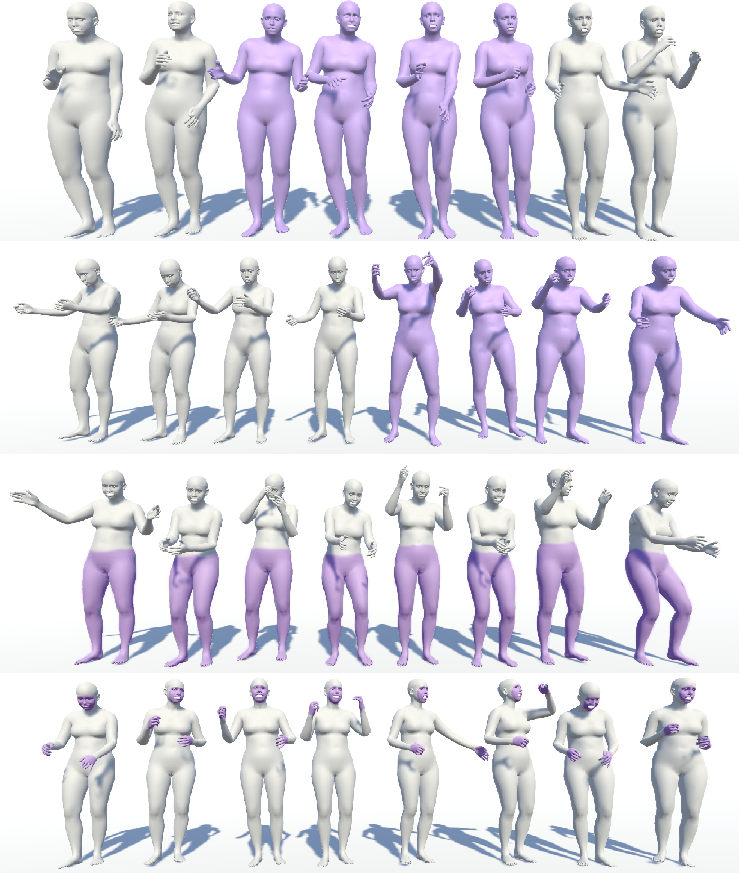
Figure 4: Motion editing visualization—BiTDiff supports temporally and spatially localized manipulation of generated sequences for flexible creative control.
BiTDiff exhibits robust inpainting, continuation, and enrichment capabilities, supporting real-time, user-guided joint-level motion control, which is not supported by prior methods.
Implications and Future Work
BiTDiff’s architecture demonstrates that bidirectional SSMs (Selective State Space Models) combined with transformative cross-modal attention enable highly efficient and expressive music-to-motion mappings at unprecedented levels of detail and control. The introduction of CM-Data sets a new standard for benchmarking, facilitating further advances in fine-grained multimodal motion synthesis. Future directions include integration of text-based control paradigms, expansion to multimodal editing, and practical deployments in digital performance or human-AI conducting ensembles.
Conclusion
This work fills a pivotal gap in fine-grained 3D conducting motion generation by introducing both the largest available dataset (CM-Data) and a hybrid generative framework (BiTDiff) that sets a new state-of-the-art in expressivity, temporal coherence, controllability, and efficiency. The principles established here—bidirectional SSMs for long-form generation and hierarchical control for joint-level editing—are likely to inform future research at the intersection of music, motion, and human-centered generative AI.