- The paper demonstrates that increased prompt complexity does not improve annotation accuracy while revealing systematic, context-dependent biases.
- Annotation accuracy varies by educational level and subject, with affective dimensions achieving the highest correctness compared to cognitive and meta-cognitive measures.
- Bias analysis uncovers model-specific variances, such as optimistic, cognitive, and meta-cognitive misclassifications that impact the reliability of automated annotation.
Decoding Student Dialogue: Multi-Dimensional Evaluation and Bias Analysis of LLMs for Automated Annotation
Introduction
Automated annotation of educational dialogue has become essential with the ubiquity of student-AI interactions. This paper conducts a rigorous empirical assessment of GPT-5.2 and Gemini-3, examining both annotation accuracy and underlying biases across three prompting strategies—few-shot, single-agent self-reflection, and multi-agent reflection—using a multi-dimensional rubric (behavioral, cognitive, meta-cognitive, affective) over disparate educational levels and subjects. The work distinguishes itself by integrating fine-grained context-aware evaluation with comprehensive bias diagnostics, thus filling critical gaps in the current LLM-as-judge literature for education (2604.04370).
Methods: Contexts, Annotation Framework, and Prompt Engineering
The study samples 800 utterances evenly distributed across K-12 Biology, K-12 Mathematics (from CoMTA), and university-level AGI and Psychology, encompassing both STEM and non-STEM domains. Annotation utilizes a four-dimensional framework:
- Behavioral: 7 categories (e.g., Question, Negotiation, Statement)
- Cognitive: Bloom’s four-level hierarchy
- Meta-cognitive: Planning, Monitoring, Reflecting, None
- Affective: 6 states, from Neutral to Boredom
Human annotation (Cohen’s κ>0.8) serves as ground truth.
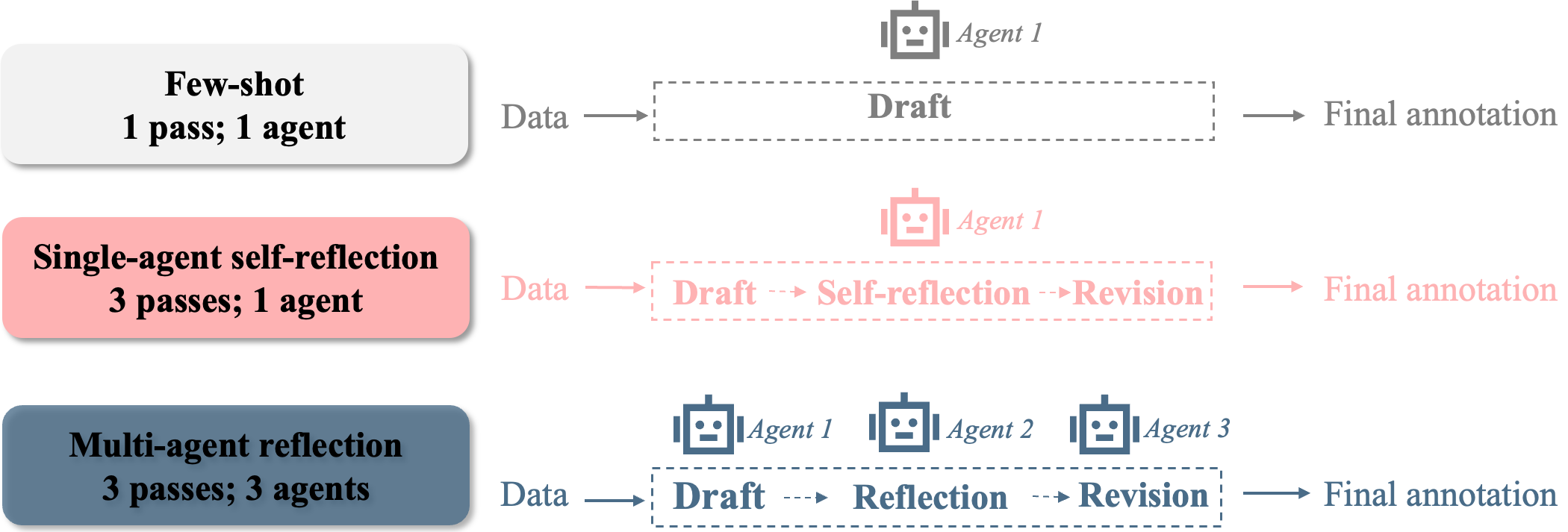
Prompting Methods
Results: Accuracy is Context- and Dimension-Dependent, Not Prompt-Dependent
Across all settings, annotation accuracy was higher for K-12 conversations versus university-level dialogues (notably more challenging in Psychology). No prompting method (neither reflective variants nor multi-agent) yielded a statistically significant increase in annotation accuracy beyond the few-shot baseline, though small descriptive gains were noted. This has strong implications: increased prompt complexity does not translate to cost-effective accuracy gains, a finding salient for large-scale deployment of annotation systems.
Accuracy also varied by annotation dimension. The affective dimension yielded the highest correctness; cognitive annotation, particularly of higher-order reasoning, suffered the lowest accuracy. Annotation of behavioral and meta-cognitive categories also lagged behind affective labeling. Substantial intra- and inter-disciplinary variation was observed, with STEM subjects demonstrating distinct error profiles compared to non-STEM.
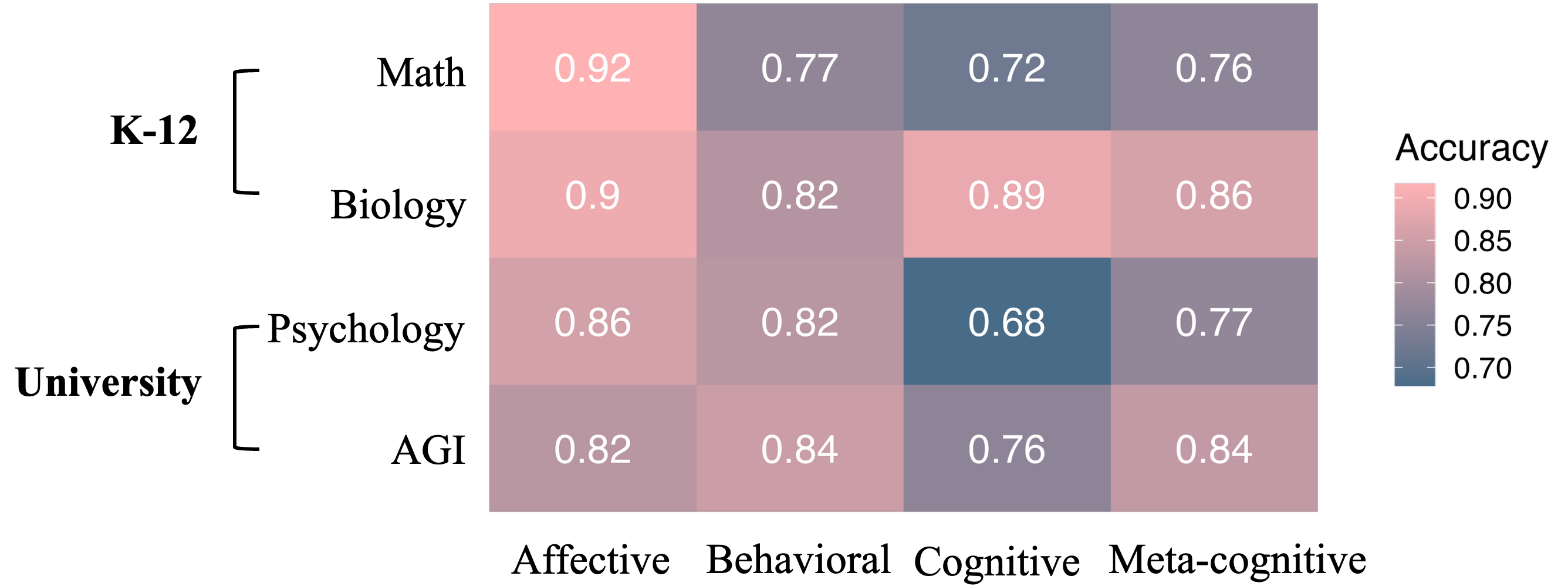
Figure 2: Annotation accuracy distribution across different subjects.
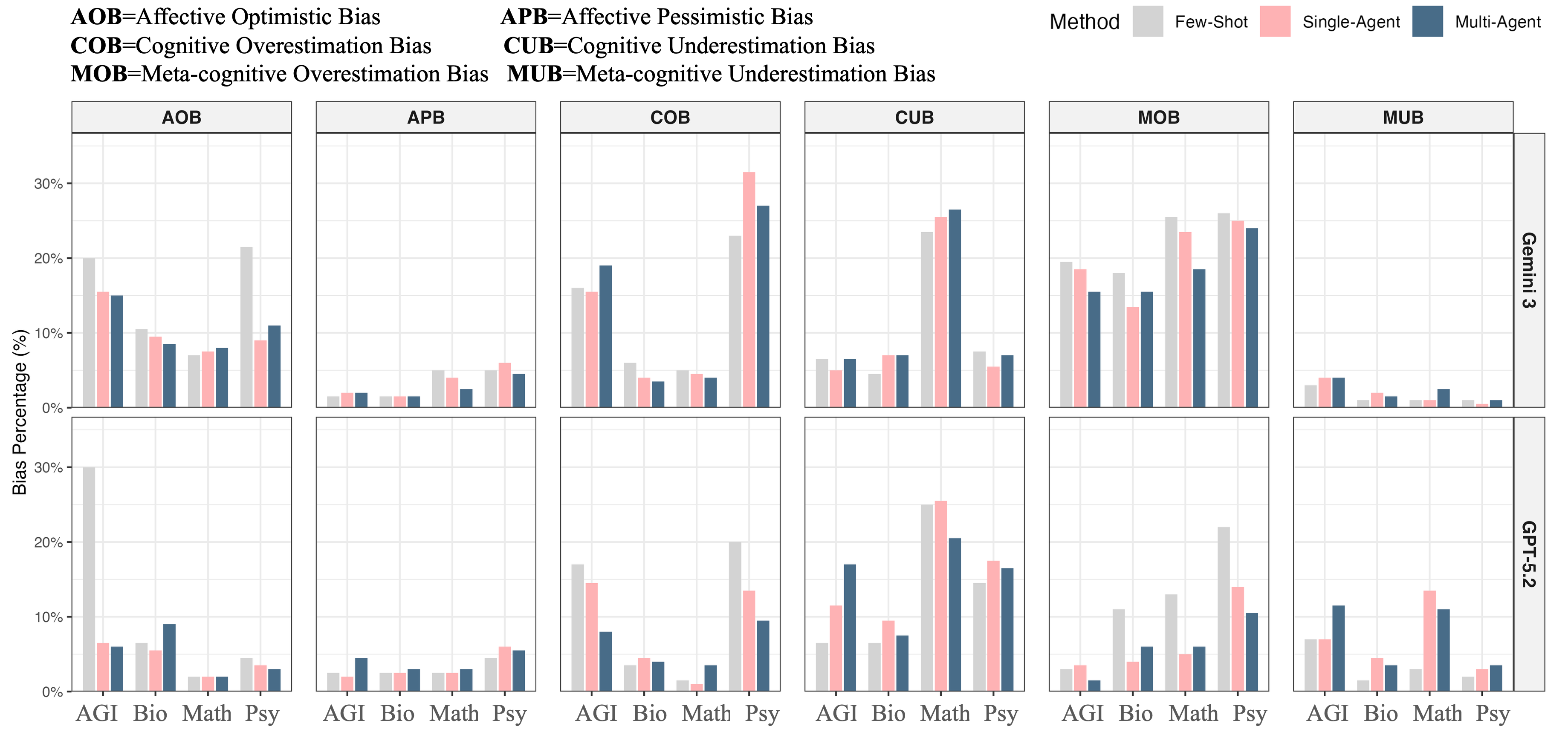
Annotation Bias: Systematic Patterns and Model-Specificity
Bias analyses revealed four consistent patterns:
Discussion: Implications and Future Directions
These results underline two chief constraints for LLM-based educational annotation systems:
- Prompt Complexity Plateau: Adding self-reflection or multi-agent critique, without further contextual adaptation, does not reliably improve annotation accuracy. This plateau suggests diminishing returns for “out-of-the-box” prompt sophistication—substantial improvements will likely require targeted model fine-tuning, expansion of in-context examples with edge cases, or explicit debiasing interventions.
- Bias Is Multidimensional and Contextual: The annotation biases are not random but systematically depend on the interaction between model, prompt design, subject domain, and annotation dimension—consistent with findings in LLM cognitive and social bias research [lin-etal-2025-investigating, echterhoff-etal-2024-cognitive]. For example, affective optimism in Gemini-3 and cognitive underestimation in Mathematics have material consequences for downstream learning analytics and educational interventions.
Practically, few-shot prompting remains the parsimonious choice unless domain, dimension, or context analysis reveals critical systematic deficiencies. For tasks requiring nuanced meta-cognitive or cognitive annotation, particularly in STEM, prompt engineering alone is inadequate; future work should pursue hybrid pipelines involving human-in-the-loop curation, enhanced diagnostic probing, and model-level interventions.
Methodologically, statistical treatment via GLMM supports robust inference across nested, contextually confounded data (educational level and subject). However, further disambiguation of domain effects would benefit from more balanced sampling and inclusion of additional (especially non-Western) educational contexts.
Conclusion
This study demonstrates that LLMs exhibit context- and dimension-sensitive patterns in student dialogue annotation, with systematic, model-dependent annotation biases that persist independent of increased prompt complexity. These findings shape both the deployment and development of future educational annotation systems—with cost-effective, accurate labeling being viable in affective and lower-level behavioral coding but less so in meta-cognitive and cognitive constructs absent further intervention. Addressing these nuanced deficiencies requires disciplinary and model-specific prompt refinement, possible multi-label classification frameworks, and deeper integration of human-AI annotation workflows.
Future research should systematically benchmark newer LLMs, test interventions such as model fine-tuning for educational annotation, and develop domain-specific mitigation strategies informed by direct bias analysis. The findings in this paper serve as a foundational baseline for such work.
References
- (2604.04370) Decoding Student Dialogue: A Multi-Dimensional Comparison and Bias Analysis of LLMs as Annotation Tools
- [lin-etal-2025-investigating] Investigating Bias in LLM-Based Bias Detection
- [echterhoff-etal-2024-cognitive] Cognitive Bias in Decision-Making with LLMs