Deep Kuratowski Embedding Neural Networks for Wasserstein Metric Learning
Published 6 Apr 2026 in cs.LG | (2604.04343v1)
Abstract: Computing pairwise Wasserstein distances is a fundamental bottleneck in data analysis pipelines. Motivated by the classical Kuratowski embedding theorem, we propose two neural architectures for learning to approximate the Wasserstein-2 distance ($W_2$) from data. The first, DeepKENN, aggregates distances across all intermediate feature maps of a CNN using learnable positive weights. The second, ODE-KENN, replaces the discrete layer stack with a Neural ODE, embedding each input into the infinite-dimensional Banach space $C1([0,1], \mathbb{R}d)$ and providing implicit regularization via trajectory smoothness. Experiments on MNIST with exact precomputed $W_2$ distances show that ODE-KENN achieves a 28% lower test MSE than the single-layer baseline and 18% lower than DeepKENN under matched parameter counts, while exhibiting a smaller generalization gap. The resulting fast surrogate can replace the expensive $W_2$ oracle in downstream pairwise distance computations.
The paper's main contribution is introducing DeepKENN and ODE-KENN, two architectures that efficiently approximate Wasserstein-2 distances.
Utilizing both CNN-based and Neural ODE frameworks, the models achieve a 28% improvement over Euclidean baselines on the MNIST dataset.
The approaches reduce per-pair computation from milliseconds to microseconds, enhancing scalability for geometric data analysis.
Deep Kuratowski Embedding Neural Networks for Efficient Wasserstein Metric Learning
Introduction and Motivation
Exact computation of pairwise Wasserstein-2 distances (W2) is a central challenge in high-dimensional data analysis, underlying tasks such as nonlinear manifold learning and optimal transport-based embedding algorithms (e.g., Wassmap, LOT Wassmap). For images and similar structured objects, W2 captures geometric similarity more robustly than alternatives like KL divergence. However, the O(n3logn) complexity of standard algorithms for evaluating W2 between discrete distributions prohibits their application in large-scale or interactive settings.
This work addresses the computational bottleneck by proposing two neural architectures—Deep Kuratowski Embedding Neural Network (DeepKENN) and ODE-KENN—which learn to approximate the W2 metric from data. Both are formally motivated by the Kuratowski embedding theorem, which ensures any bounded metric space can be isometrically mapped into a Banach space. Empirical investigation on MNIST demonstrates that these approaches, particularly ODE-KENN, yield precise metric surrogates, outperforming strong baselines in test MSE and generalization gap.
Theoretical Framework and Model Design
Wasserstein Geometry and Kuratowski Embedding
Embedding metric spaces into Banach spaces while preserving distances is fundamental to geometric data science. The Kuratowski–Wojdyła theorem guarantees that a bounded metric space can be isometrically embedded as a closed subset of ℓ∞(M), though no constructive or trainable method is implied. The proposed DeepKENN architecture discretizes this principle by representing the distance as a weighted sum across all hierarchical CNN feature spaces, with the learnable weights enforcing positivity via softplus transformation.
DeepKENN: Multi-Layer Product Space Embedding
Formally, for an L-layer CNN, DeepKENN defines the surrogate metric:
d^(x,x~)=k=1∑Lλk∥F(k)(x)−F(k)(x~)∥22
where λk≥0 are trained, and F(k)(x) is the W20-th layer's activation for input W21. This aggregate defines a Euclidean norm in the direct sum of the feature spaces, a discrete analog to the infinite-dimensional Kuratowski embedding. For generic expressive architectures, the injectivity and the triangle inequality are structurally guaranteed.
Transitioning to a continuous-depth setting, ODE-KENN leverages a Neural ODE dynamics:
W22
where the solution path W23 resides in the Banach space W24, and the learned metric is defined as:
W25
with a learnable, time-dependent nonnegative weight function W26. The architecture incorporates implicit regularization due to the Lipschitz continuity of the ODE's vector field, tightly controlling the model’s capacity to fit adversarial or spurious variations.
Experimental Analysis
The study evaluates the models on the MNIST dataset, treating normalized images as discrete probability measures. The dataset construction involves exact W27 computation for 55,000 image pairs, divided into training, validation, and test sets. The backbone encoder is fixed for all models to ensure matched parameter budgets, with convolutional and fully connected layers followed (if required) by a Neural ODE or metric head.
Quantitative Performance and Learning Dynamics
ODE-KENN achieves a test MSE of W28—a significant 28% improvement over the naive Euclidean baseline and an 18% reduction over DeepKENN. The relative mean absolute error is W29, confirming high-fidelity approximation of the ground-truth O(n3logn)0 oracle.
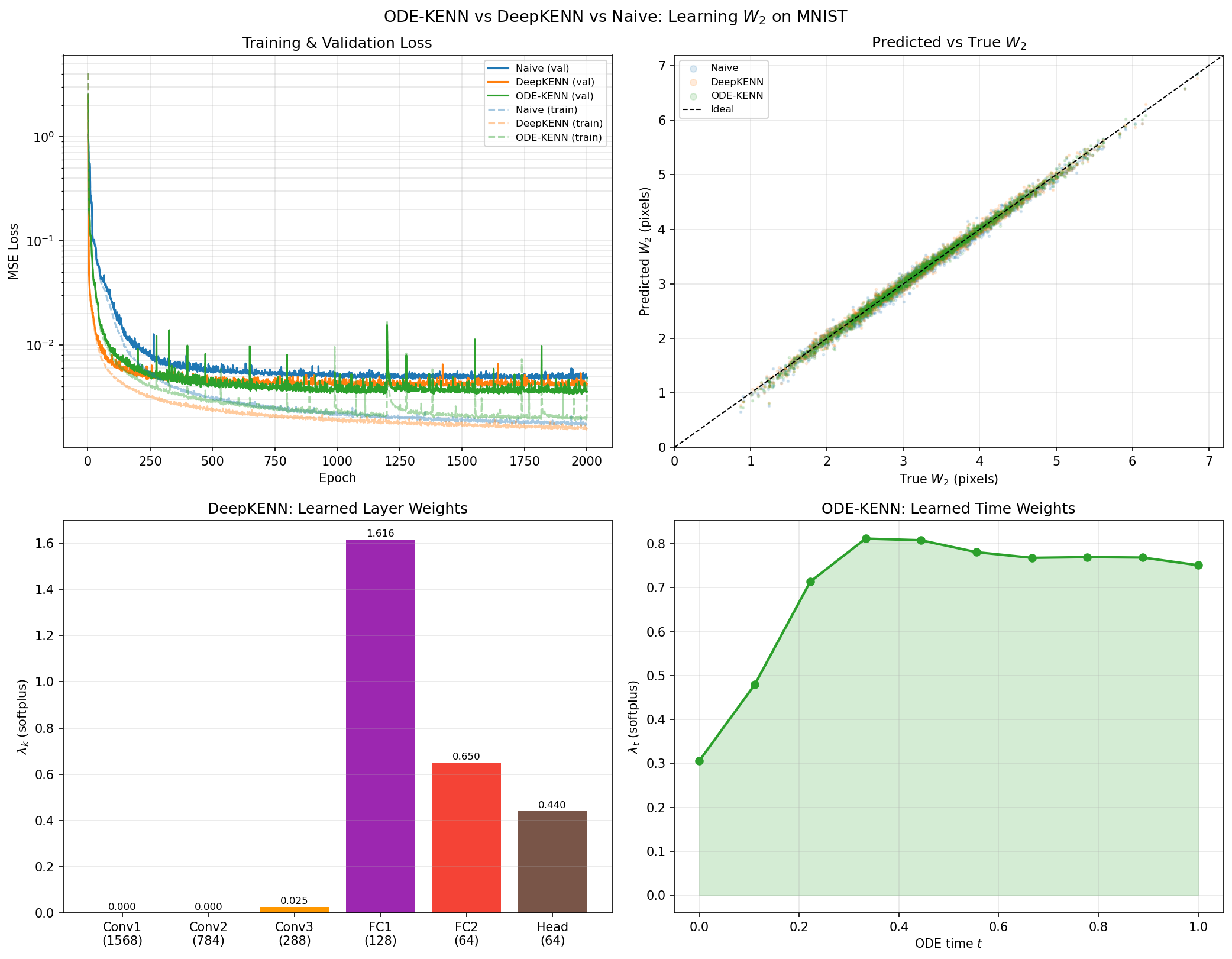
Figure 1: Experimental results for all three models trained for 2,000 epochs on MNIST O(n3logn)1 distance learning. ODE-KENN exhibits the fastest convergence, minimal generalization gap, and best fit to ground-truth distances, while weight analysis reveals that compressed representations are most informative.
The loss curves (Figure 1, top left) demonstrate that ODE-KENN not only converges fastest but also maintains the narrowest train/validation loss gap, substantiating claims of superior regularization and generalization. The predicted versus true scatter plot (Figure 1, top right) evidences the tightest alignment, especially in the small metric regime most relevant for local manifold recovery.
Analysis of Learned Representations
For DeepKENN, the learned weights (Figure 1, bottom left) nearly zero out early convolutional layers, while the first fully connected layer overwhelmingly dominates, indicating that local, translation-sensitive features are uninformative for O(n3logn)2—compressed, semantic encodings are preferred. In ODE-KENN, the time-dependent O(n3logn)3 profile peaks in the early-to-middle segment of the trajectory (Figure 1, bottom right), downweighting both raw input encodings and long-time features and emphasizing intermediate ODE-evolved representations crucial for metric discrimination.
Practical and Theoretical Implications
The principal practical utility lies in the acceleration of pipelines dependent on pairwise O(n3logn)4 matrices. Using ODE-KENN as a drop-in predictor reduces the per-pair cost from milliseconds (linear programming) to microseconds (neural forward pass), enabling scalable application of methods such as Wassmap. Critically, the learned surrogate generalizes robustly to novel test pairs, and its amortized training cost is negligible for large-scale downstream use.
On a theoretical level, this work demonstrates that appropriately structured neural architectures can learn metrics that respect the triangle inequality (and, for almost all practical purposes, positive definiteness) for non-trivial measures. The analysis reveals that convolutional spatial hierarchies offer no advantage for Wasserstein learning on MNIST, possibly generalizing to other grid-based imaging domains. The continuous-depth ODE embedding further regularizes the function space, yielding both statistically and computationally efficient surrogates.
Limitations and Future Directions
A precomputed ground-truth O(n3logn)5 training set is required, necessitating an upfront computational expense, though this is amortized by the inference gains. While approximate metric properties are maintained, strict positive definiteness is only empirically supported, potentially limiting application in settings sensitive to metric violations.
Future work could extend these results to O(n3logn)6 for general O(n3logn)7, provide sharper theoretical bounds on approximation error and injectivity, and scale experiments to higher-dimensional or more complex imaging domains. Integrating hard metric constraints directly into the loss, or exploring alternative neural infinite-dimensional embeddings, are promising avenues.
Conclusion
This paper introduces DeepKENN and ODE-KENN, two neural approximators for the Wasserstein-2 metric motivated by Kuratowski’s isometric embedding theorem. Extensive experiments provide strong evidence for the efficacy of the ODE-KENN design, which not only outperforms fixed-depth and single-layer baselines but does so with enhanced generalization and interpretability in terms of learned features and trajectories. This advances the state-of-the-art in learned optimal transport surrogates, providing a compelling tool for scalable geometric machine learning and metric-based analysis.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.