- The paper introduces a novel mastery-conditioned CMDP framework that structurally masks instructional actions based on prerequisite mastery.
- It employs a two-timescale primal-dual optimization to balance engagement rewards with safety constraints, ensuring convergence to safe policies.
- Empirical results show MC-CPO achieves near-zero reward hacking and robust performance across both tabular and neural RL settings.
Authoritative Summary of "MC-CPO: Mastery-Conditioned Constrained Policy Optimization" (2604.04251)
Context and Motivation
Reinforcement learning (RL) has become prevalent in adaptive instructional systems, facilitating long-horizon decision-making for personalized educational sequencing. However, educational RL faces severe reward misspecification: short-term proxy signals such as engagement or completion rates often diverge from authentic mastery objectives, allowing for reward hacking—where agents optimize engagement without meaningful learning. Existing mitigation largely relies on reward engineering, yet fails to structurally prevent pedagogically undesirable behaviors.
The paper introduces the Mastery-Conditioned Constrained Policy Optimization (MC-CPO) framework, which addresses reward hacking by defining a Constrained Markov Decision Process (CMDP) wherein the feasible action set is strictly conditioned on learner mastery. This approach structurally enforces pedagogical correctness by masking instructional actions until all prerequisites are adequately mastered, fundamentally altering the state-driven feasibility landscape compared to prior static or policy-driven safe RL approaches.
Mastery-Conditioned CMDP
The environment is parameterized by an instructional prerequisite graph over concepts. The learner's state is a combination of interaction features and a continuously evolving mastery vector, governed by probabilistic knowledge tracing (e.g., Bayesian Knowledge Tracing). The feasibility mask restricts available actions at each step based on prerequisite fulfillment: actions corresponding to advanced concepts are infeasible until prerequisite concept mastery exceeds a fixed threshold.
The reward structure isolates engagement signals, while pedagogical safety constraints (discounted cost functions) penalize insufficient mastery progression, inadequate cognitive demand, and engagement–learning decoupling. Policies are parameterized to yield zero probability for masked infeasible actions, inducing structural safety by construction, not reward transformation.
MC-CPO Algorithm
MC-CPO employs a two-timescale primal-dual optimization scheme. The Lagrangian incorporates engagement returns and safety budgeted costs, optimizing policy parameters and dual variables concurrently. A masked softmax parameterization structurally enforces prerequisite safety, and an event-triggered frontier mixing injects uniform probability into newly expanded feasible actions, stabilizing exploration in regimes with dynamic feasibility expansion.
The theoretical analysis comprises:
- Structural prerequisite safety: The masking mechanism guarantees zero probability of prerequisite violations for any policy parameter values.
- Convergence under tabular approximation: Stochastic approximation theory (Borkar’s conditions) assures almost sure convergence to stationary feasible points.
- Safety gap theorem: MC-CPO strictly outperforms post-hoc filtering of unconstrained policies under identical safety budgets, due to the irrecoverable loss in reward when feasible support is absent in unconstrained policies.
Empirical Analysis and Results
Tabular Regime
Experiments on minimal and multi-step CMDPs emphatically demonstrate MC-CPO’s empirical guarantees. In a minimal example, unconstrained RL and post-hoc filtering converged to π(hack)≈1, achieving maximal engagement but violating constraints. MC-CPO reduced constraint violations below 10−3, maintained engagement at the safe optimum, and achieved a Welch t-test difference (Cohen's d>1000) between MC-CPO and post-hoc filtering policies, confirming the safety gap.
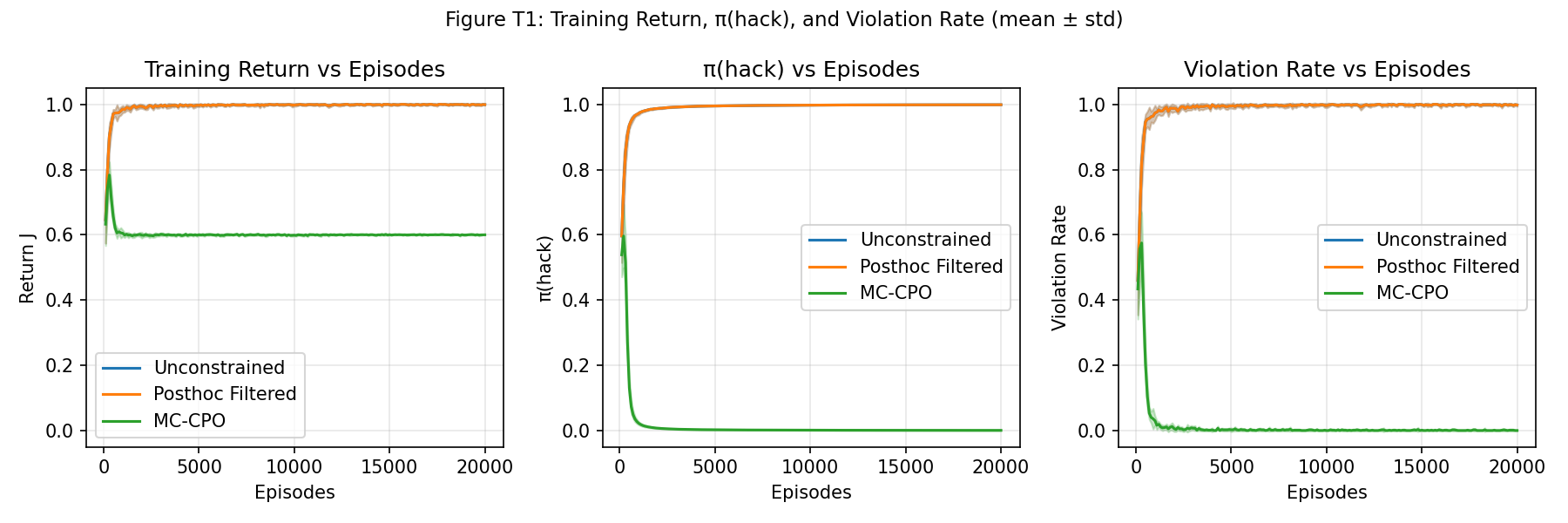
Figure 1: Training return, π(hack), and violation rate show MC-CPO drives hacking probability to near zero.
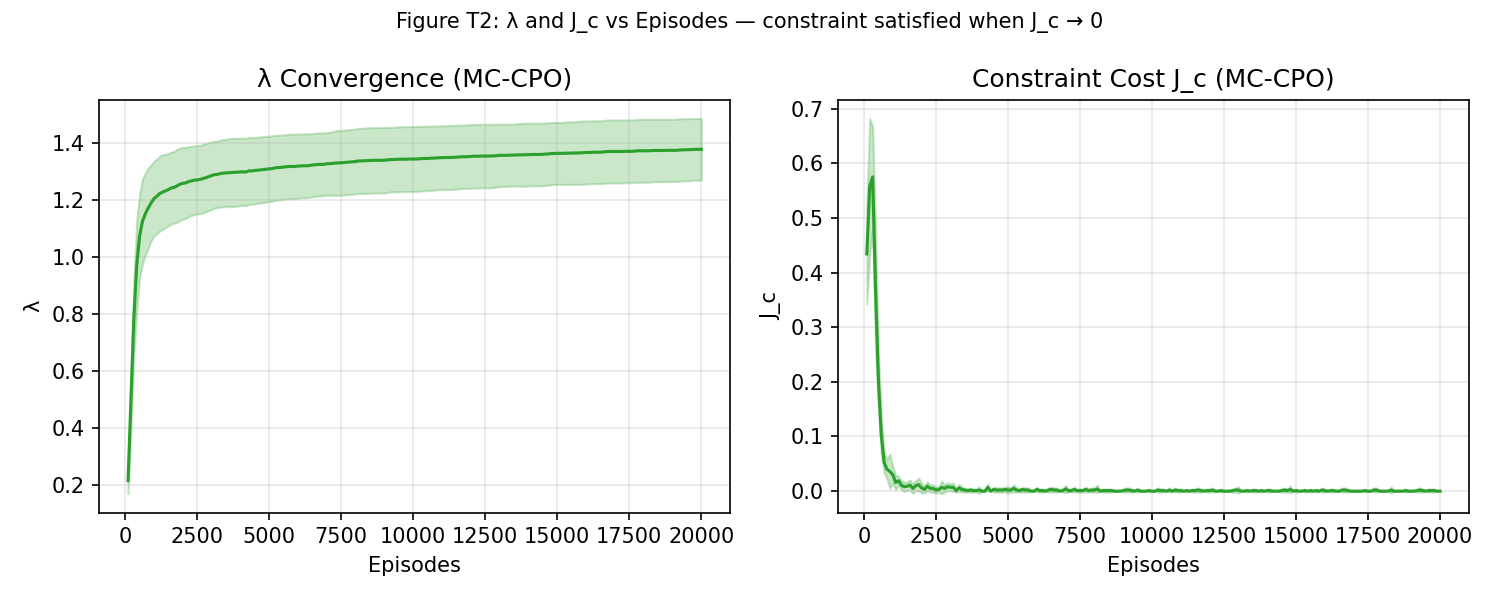
Figure 2: Dual variable and constraint cost dynamics; the dual converges when the safety budget is achieved.
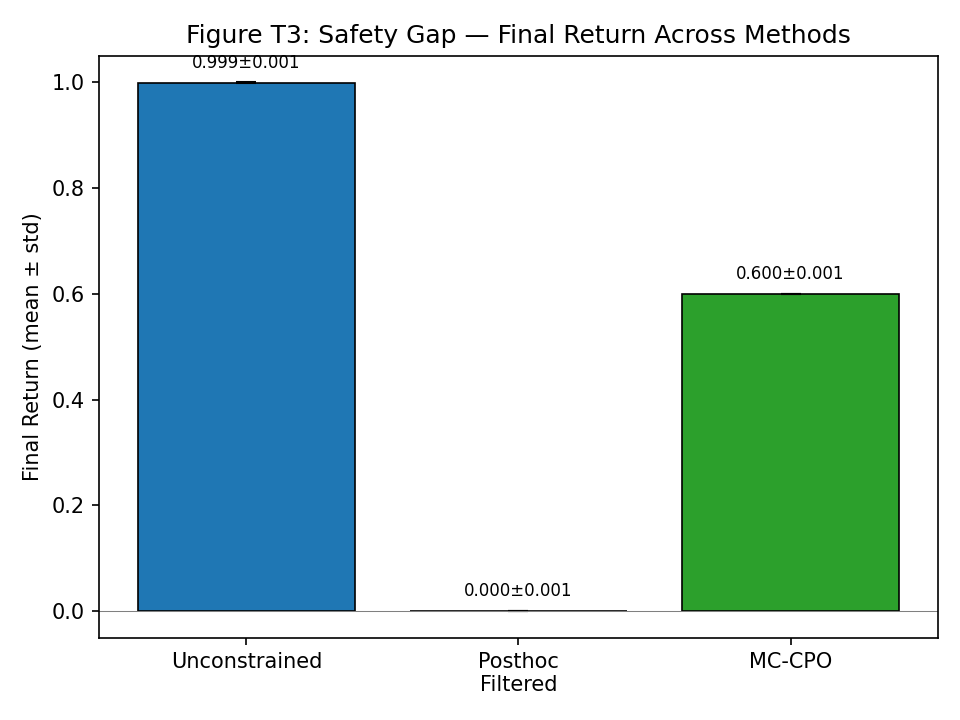
Figure 3: Final return comparison; MC-CPO substantially outperforms post-hoc filtering under identical budgets.
Extended multi-step CMDPs with stochastic mastery confirm robustness. MC-CPO yields lower RHSI and higher return than post-hoc filtering, even as chain depth and stochasticity increase.
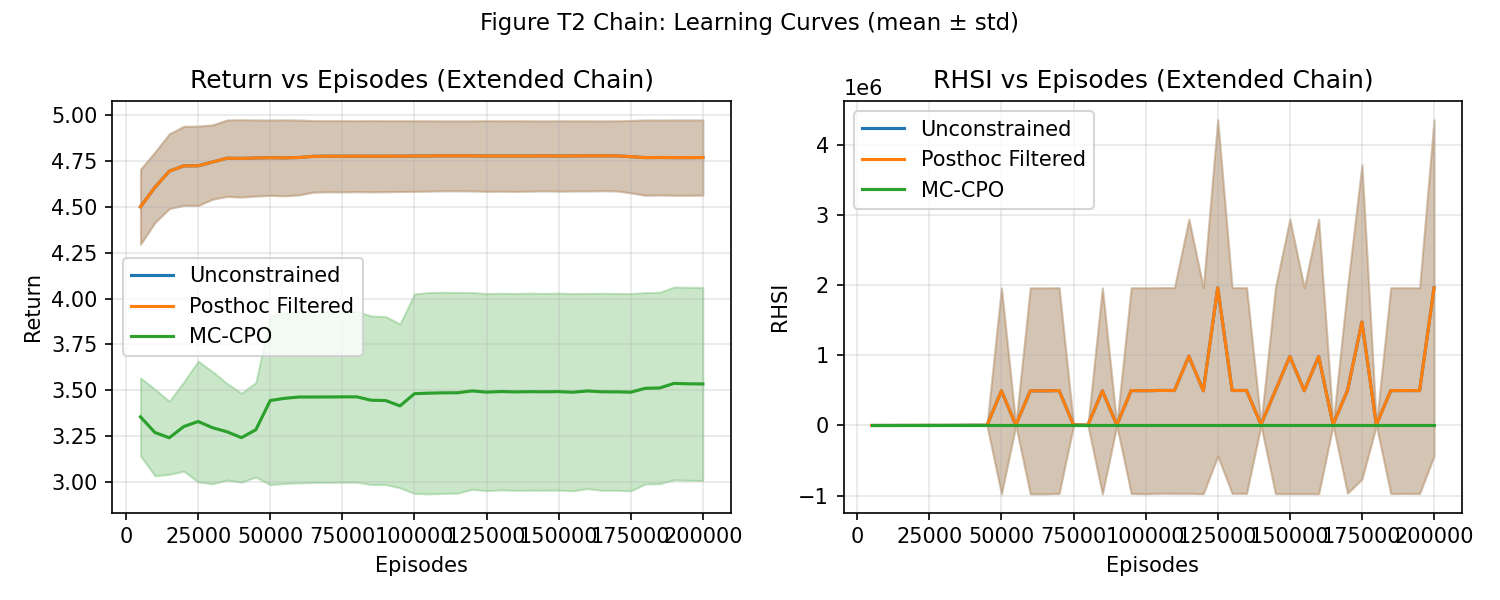
Figure 4: Extended chain CMDP learning curves; MC-CPO yields improved reward–safety balance and learning tradeoff.
Neural Function Approximation
Scaling to neural policies (PPO backbone), MC-CPO achieves engagement returns competitive with unconstrained and reward-shaped baselines, while substantially lowering reward hacking severity (RHSI) and satisfying all safety constraints within tolerance thresholds. Importantly, reward shaping collapses to the unconstrained solution as the sparse learning signal in large-scale tutoring environments renders additive penalties structurally ineffective.
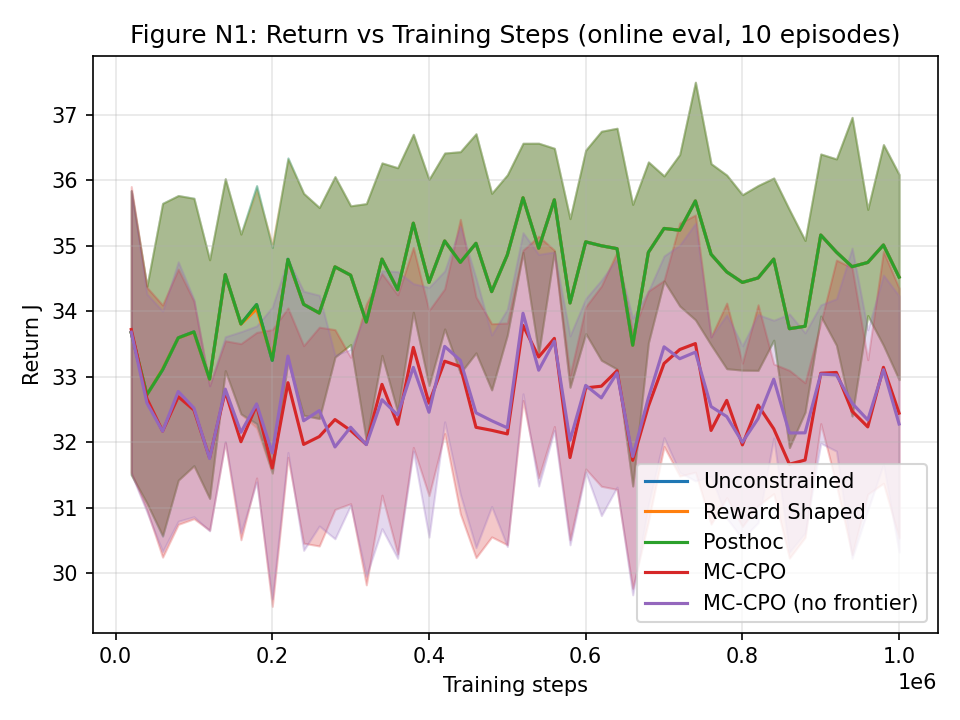
Figure 5: Engagement return trajectories over training indicate MC-CPO sustains competitive performance.
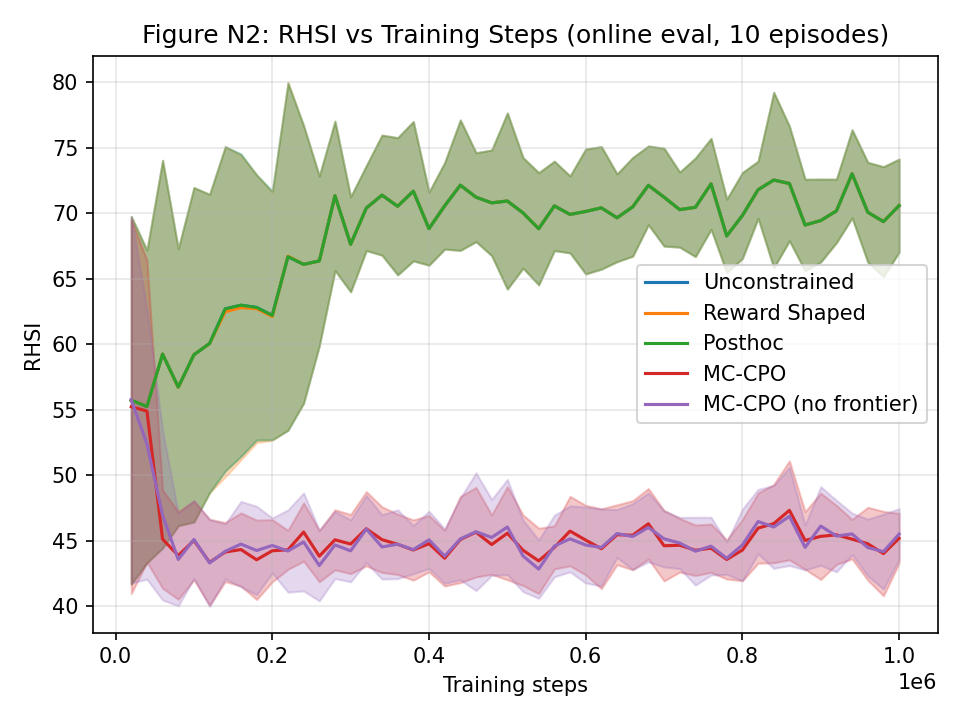
Figure 6: MC-CPO substantially reduces RHSI over training, quantitatively mitigating reward hacking.
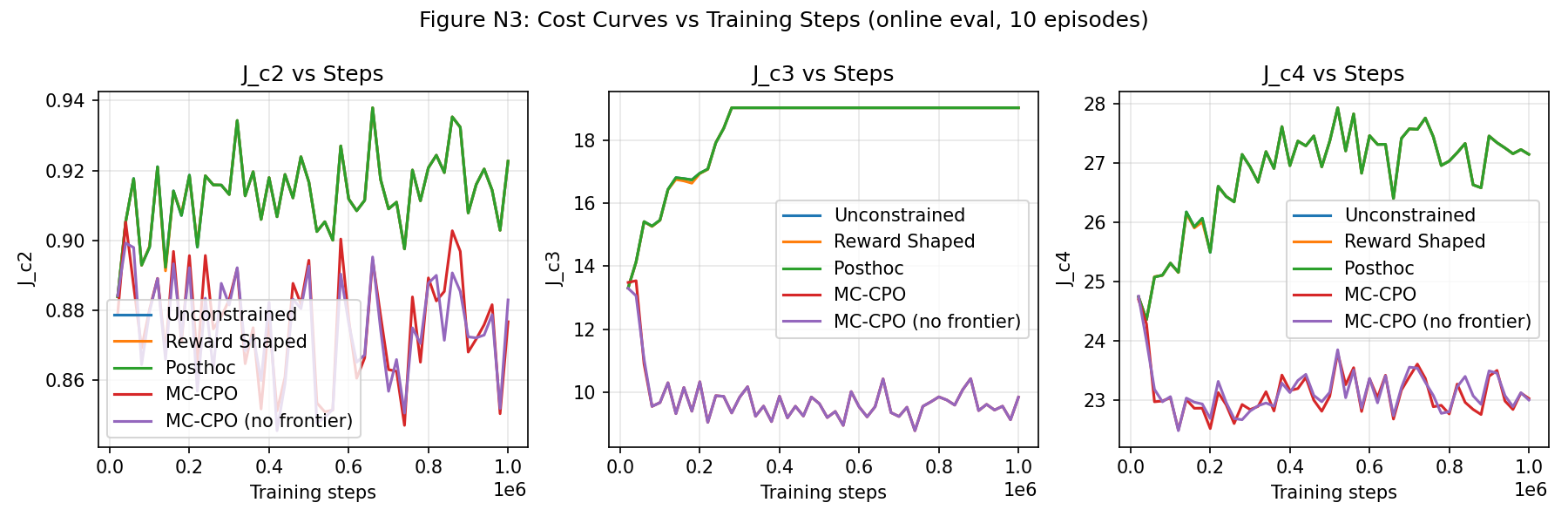
Figure 7: Discounted pedagogical cost trajectories demonstrate MC-CPO’s budget adherence.
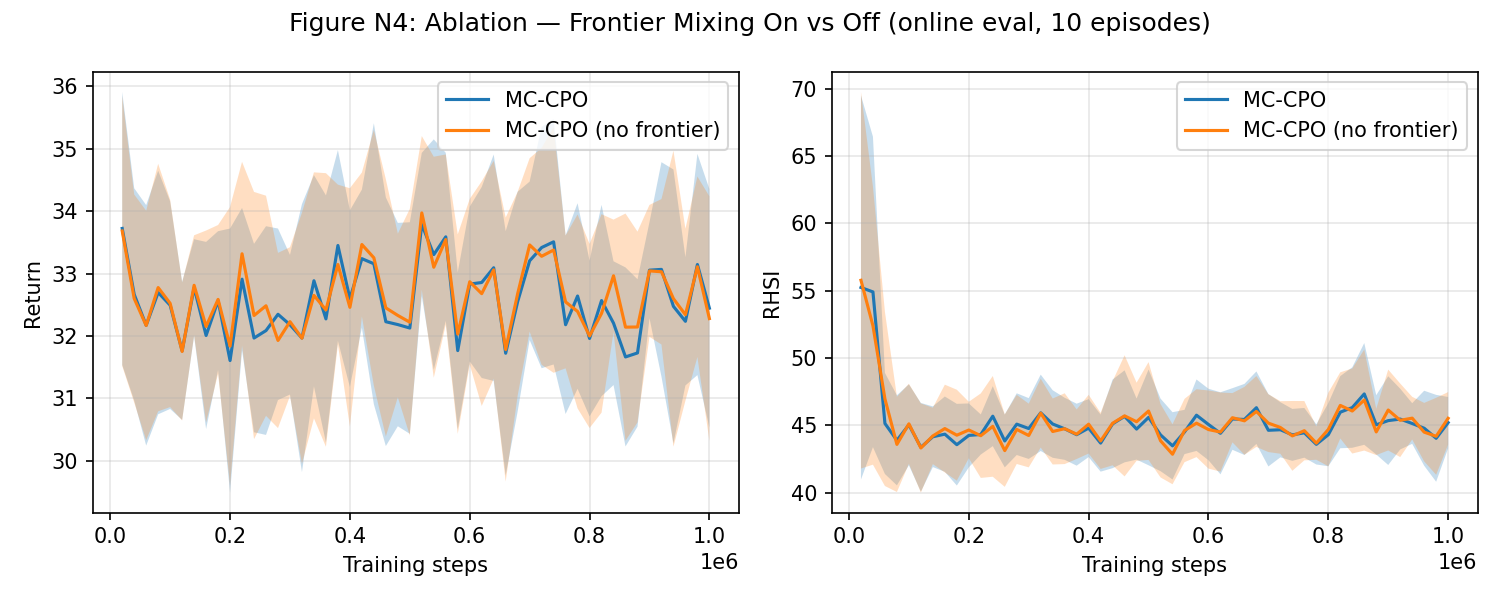
Figure 8: Ablation reveals frontier mixing stabilizes early exploration without significantly affecting asymptotic reward.
Scaling experiments with 25-concept curricula and injected mastery estimation noise show MC-CPO’s robustness; constraint satisfaction persisted across noise levels up to σ=0.2—comparable to practical BKT estimation error ranges.
Implications and Theoretical Significance
The conversion from reward modification to structural feasibility constraints demonstrates that only direct modeling of pedagogical safety achieves robust reward–mastery alignment in instructional RL. The results highlight that scalarized objectives, such as reward shaping, cannot guarantee constraint satisfaction when engagement incentives dominate. Post-hoc filtering also fails to recover reward unless unconstrained policies maintain feasible action support; MC-CPO solves this by construction.
The safety gap theorem underscores the necessity of optimizing within the mastery-conditioned feasible set rather than relying on ex post correction. MC-CPO’s monotonic expansion of feasibility, driven by mastery progression, distinguishes it from policy-driven feasible expansion in prior safe RL (e.g., FPI, FPO).
Practically, MC-CPO provides a paradigmatic foundation for safer educational RL deployment, significantly reducing reward hacking while maintaining engagement. Theoretical implications extend to any CMDP regime with state-driven dynamic feasibility, opening directions for partially observable instructional settings, deeper function approximation analysis, and fairness-aware constraint design.
Conclusion
MC-CPO fundamentally restructures the interaction between policy optimization and pedagogical safety in adaptive instructional systems. Its mastery-conditioned action masking, grounded in CMDP theory, enforces structural prerequisite safety, ensures convergence to stationary feasible policies under safety budgets, and empirically provides strong reward–safety tradeoff improvements over existing baselines. Its robust performance across CMDP variants, neural approximations, and practical estimation error regimes validates mastery-conditioned feasibility as an essential foundation for mitigating reward hacking in RL-powered tutoring systems.