- The paper presents AffectSpeech, a novel dataset that replaces traditional emotion labels with detailed natural language annotations to capture nuanced affective speech dynamics.
- It employs a hybrid human–LLM collaborative pipeline that combines algorithmic pre-labeling with expert validation across multiple annotation styles.
- Empirical results show that models trained on AffectSpeech achieve superior performance in speech emotion captioning and synthesis, demonstrating enhanced prosodic and emotional accuracy.
AffectSpeech: A Large-Scale Emotional Speech Dataset with Fine-Grained Textual Descriptions for Speech Emotion Captioning and Synthesis
Introduction and Motivation
AffectSpeech addresses fundamental constraints in emotional speech modeling imposed by legacy annotation paradigms, namely discrete categorical or low-dimensional continuous representations. These traditional schemes are insufficient for capturing the intricate, multi-granular structure of human affect, especially in the context of expressive modeling tasks such as speech emotion captioning (SEC) and emotional speech synthesis (ESS). The dataset is motivated by the need for more expressive and interpretable data, utilizing human–LLM collaboration to generate fine-grained, natural language-based annotations over a vast corpus of authentic, human-recorded speech.
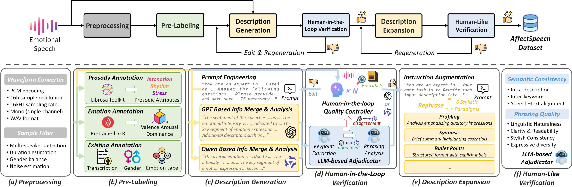
Figure 1: The construction and annotation pipeline of the AffectSpeech dataset.
Dataset Construction and Annotation Scheme
The construction of AffectSpeech is grounded in maximizing emotional expressiveness, acoustic quality, and annotation reliability, while ensuring legal and reproducible data curation. AffectSpeech aggregates 253,799 utterances from nine benchmark corpora, including both acted and spontaneous data encompassing nine emotion classes. The dataset is characterized by meticulous preprocessing for format standardization, signal quality, and metadata filtration, ensuring high inter-source consistency.
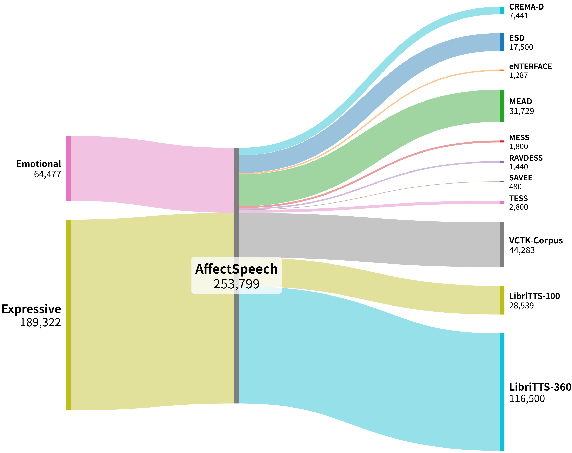
Figure 2: Composition and scale of the AffectSpeech dataset categorized by original data sources.
The annotation pipeline is multi-stage and hybrid. An initial algorithmic pre-labeling phase extracts prosodic and emotion priors (e.g., pitch, tempo, VAD, and category) using standard toolkits and pretrained SER models. These features are input to multiple state-of-the-art multimodal LLMs (GPT- and Qwen-based) prompted with both acoustic and auxiliary metadata for generation of open-vocabulary, structured text captions; six stylistic variants (narrative, profiling, synopsis, bullet-point, technical, structural) are produced per utterance to promote linguistic and functional diversity.
A human-in-the-loop verification loop, involving expert annotators in linguistics and psychology, adjudicates ambiguous or low-consensus LLM outputs to ensure alignment between captions and true emotional/prosodic content. This collaborative approach realizes a balance between scale and annotation reliability not achieved by prior works.

Figure 3: Illustration of diverse speech emotion captioning styles.
Annotation Properties and Statistical Insights
AffectSpeech supports annotation across six dimensions: sentiment polarity, free-form emotion caption, emotional intensity, prosodic attributes (pitch, tempo, energy), prominent segment localization, and emotion-related semantic keywords. This multi-granular architecture provides unprecedented flexibility for downstream models in capturing nuanced emotional dynamics and context-sensitive expression.
The corpus demonstrates balanced gender representation, rich sentiment and prosodic diversity, and lexical coverage. Notably, narrative descriptions are the most verbose, while synopses and bullet-points are concise, facilitating a range of interpretability and control in model training and evaluation.
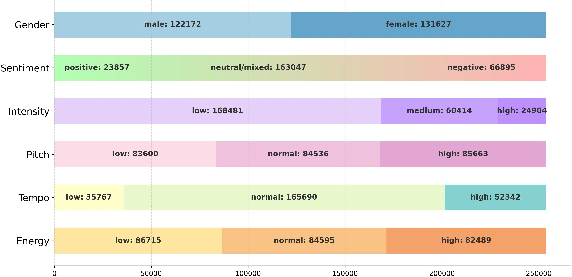
Figure 4: Quantitative distributions of speaker gender, sentiment polarity, intensity level, and prosodic attributes (pitch, tempo, and energy).
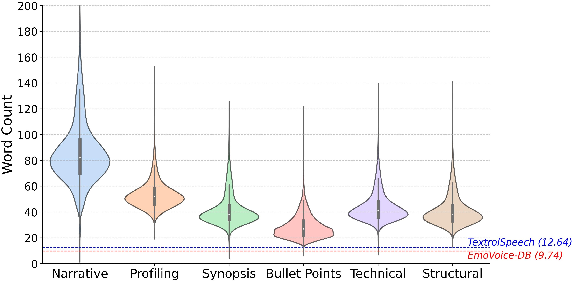
Figure 5: Text length distributions across six textual description styles.
Utterance durations in AffectSpeech are generally compact (95% under 15.2s), supporting a focus on segment-level emotional outbreaks. The word cloud confirms that the annotation lexicon extends far beyond basic categories, incorporating nuanced valence, intensity, and prosodic descriptors.
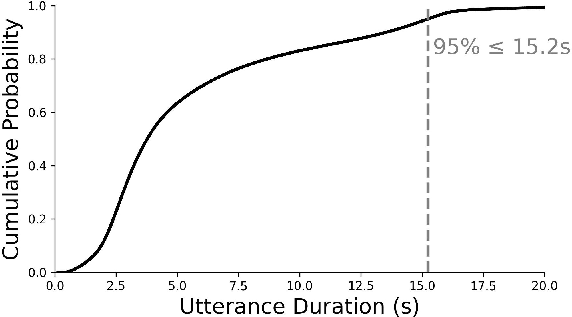
Figure 6: Empirical cumulative distribution function of utterance duration.
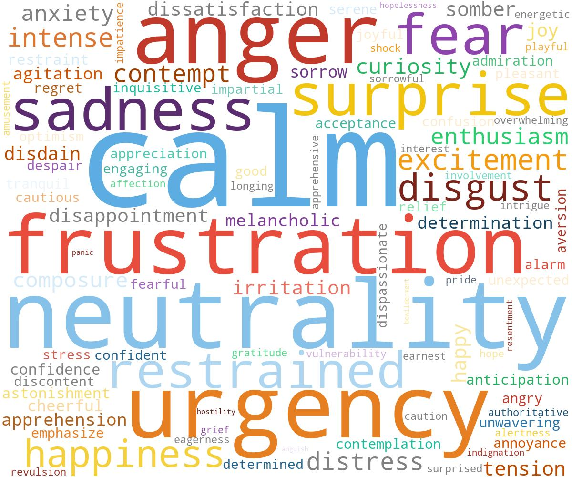
Figure 7: Word cloud of the top-100 most frequent emotion-related words.
Benchmarking: Speech Emotion Captioning (SEC)
Extensive supervised fine-tuning (SFT) experiments were conducted on the Qwen2-Audio and Qwen2.5-Omni backbones using AffectSpeech, TextrolSpeech, and EmoVoice-DB as training corpora. Zero-shot and SFT models are comprehensively evaluated using emotion and prosody classification accuracy, lexical diversity (Distinct-2), structural consistency (Self-BLEU), and mean word count.
Key empirical results:
- Qwen2.5-Omni SFT on AffectSpeech attains highest category accuracy (73.25%) and strong prosodic alignment (e.g., pitch accuracy 46.75%), clearly surpassing both zero-shot Foundation models and SFT on coarser-grained datasets.
- AffectSpeech-trained models achieve an optimal trade-off between lexical diversity and stylistic regularity, producing texts of medium length and high content density unlike the short, repetitive or generic baselines.
Subjective preference testing confirms that human raters consistently favor AffectSpeech-trained model captions (over 68% in the prosody dimension), highlighting the perceptual relevance and interpretability of its fine-grained descriptions.
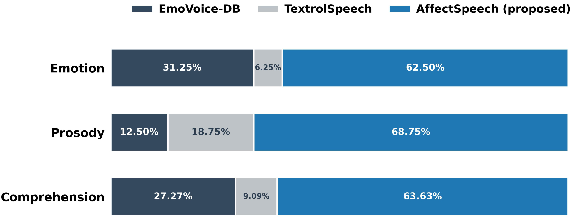
Figure 8: Subjective preference test results, which compare SFT variants trained on EmoVoice-DB, TextrolSpeech, and the proposed AffectSpeech across three perceptual dimensions.
Benchmarking: Emotional Speech Synthesis (ESS)
ESS experiments used VoxInstruct as the backbone, trained on each of the three datasets above. Objective metrics include word error rate (WER), rhythmic similarity (DDUR), and embedding-based emotion similarity/diversity (Emo_Sim, Emo_Div). Subjective MOS and Likert attribute ratings quantify perceptual quality and expressivity.
Key empirical findings:
- VoxInstruct SFT on AffectSpeech achieves competitive or superior WER (4.36%) compared to foundation TTS systems, with highest emotion similarity (86.40%) and diversity (19.91e-4), indicating improved breadth and detail in generated emotional prosody.
- Human listening tests demonstrate that AffectSpeech models produce more fluent, intelligible, and natural emotional speech, maximally leveraging multi-granular textual conditioning.
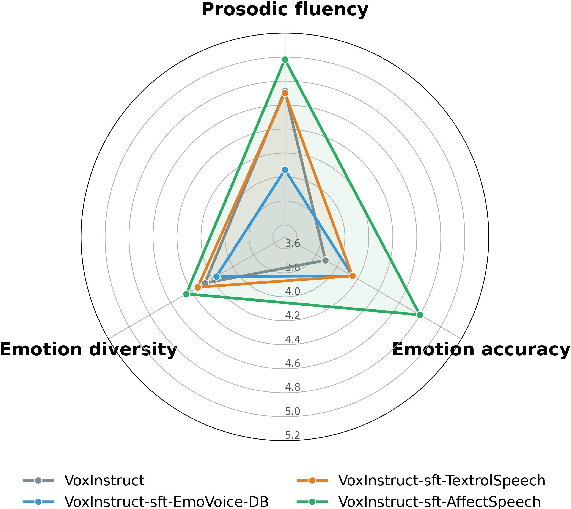
Figure 9: Perceptual attribute analysis of synthesized speech, illustrating subjective ratings (1--7 Likert scale) for prosodic fluency, emotion accuracy, and emotion diversity.
Theoretical and Practical Implications
AffectSpeech exemplifies a paradigm shift in affective computing corpora, replacing legacy low-dimensional signal annotations with open-vocabulary, context-rich textual schemes. This shift enables:
- Semantic-level control of expressive synthesis and advanced SEC, supporting mixed emotions, subtle transitions, and context-driven emphasis.
- Improved evaluation realism through human-aligned, fine-grained metrics rather than proxies based solely on categorical or dimensional accuracy.
- Better generalization and debiasing of neural models due to the multiplicity of annotation styles and human validation.
For practical systems in empathetic AI, affect-aware dialogue, or expressive TTS, AffectSpeech-trained models can synthesize or interpret nuanced emotional content well beyond the capabilities of models constrained by older corpora. The hybrid annotation and expansion pipeline also provides a reproducible template for future multimodal dataset construction.
Future Developments
There are clear trajectories for extending AffectSpeech: (a) scaling to additional languages and cultures to support multilingual and cross-cultural emotion learning, (b) increasing temporal granularity towards frame-level or hierarchical annotations, and (c) fusing richer multimodal (e.g., facial, gestural) data streams for holistic affect synthesis and recognition. The dataset and annotation approach may further catalyze more advanced controllable synthesis paradigms and real-time emotional dialog systems.
Conclusion
AffectSpeech establishes a new benchmark for emotional speech datasets by systematically integrating fine-grained, natural language-based multi-style annotations at scale, with human-in-the-loop verification. Its empirical superiority across both SEC and ESS demonstrates the critical value of multi-dimensional, context-aware annotation for high-fidelity emotional modeling. The dataset is destined to underpin the next generation of affective neural architectures and research in human-centric speech AI.