- The paper introduces a dual-space dataset annotating both continuous affect (VAD) and low- to mid-level perceptual cues to enable fine-grained controllable image generation.
- The methodology integrates automated entity detection, prompt-based chain-of-thought inference, and human-in-the-loop verification to ensure high annotation fidelity and precise affect-perception mapping.
- The baseline using APMV modulation significantly improves VAD and color matching, paving the way for more intuitive and consistent affective image synthesis.
Dual-Space Affective–Perceptual Dataset for Fine-Grained Controllable Image Generation
Introduction and Motivation
Despite significant advances in text-to-image generation, nuanced control over the affective attributes and perceptual atmosphere of generated scenes has remained an open challenge. Prevailing approaches primarily utilize prompt engineering—replacing adjectives such as "happy" with more intense modifiers—which yields weak and inconsistent influence on the generated affect. The core limitation is the lack of datasets that jointly annotate images with both continuous affective semantics (e.g., Valence–Arousal–Dominance, VAD) and low- to mid-level perceptual cues such as color, luminance, and structural complexity. Existing datasets are generally constrained to faces, artistic imagery, or narrowly defined domains, with coarse or predominantly discrete labels, preventing systematic investigation of the affect–perception interface in generation.
The "EmoScene: A Dual-space Dataset for Controllable Affective Image Generation" (2604.00933) introduces EmoScene, a large-scale dataset uniquely designed to address these gaps. EmoScene delivers fine-grained annotation in a dual-space format, encompassing affective (discrete emotions, continuous VAD) and explicit perceptual descriptors (HSV color, structural features), contextual semantics, and textual descriptions.
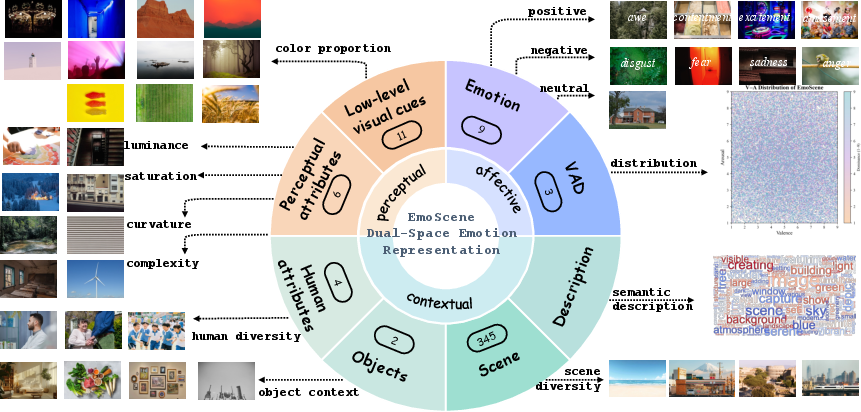
Figure 1: Multi-space attributes in the EmoScene Dataset, illustrating the integration of affective, perceptual, and contextual information for each image.
Dataset Construction: Dual-Space Annotation Pipeline
EmoScene is constructed on a curated collection of 1.2 million images spanning 345 real-world and artistic scene categories, sourced from diverse public and artistic platforms. The annotation pipeline comprises 11 steps, integrating automated entity detection, multimodal LLMs, prompt-based chain-of-thought inference, perceptual feature extraction, and a human-in-the-loop (HITL) verification stage. Key aspects include:
- Entity and Contextual Analysis: Human and object detection, attribute estimation, and scene–entity interaction reasoning using VLMs.
- Rich Language Descriptions: Automatic and MLLM-driven captions in multiple stylistic variants for each scene.
- Affective Annotation: Dual model CoT protocol assigns both discrete emotions (amusement, anger, awe, contentment, disgust, excitement, fear, sadness, neutral) and continuous VAD values on a [1,9] scale.
- Perceptual Annotation: Extraction of dominant colors (CIE Lab/HSV), achromatic vs. chromatic ratios, spatial structure (curvilinearity, edge density), and complexity.
The entire pipeline is summarized in Figure 2.
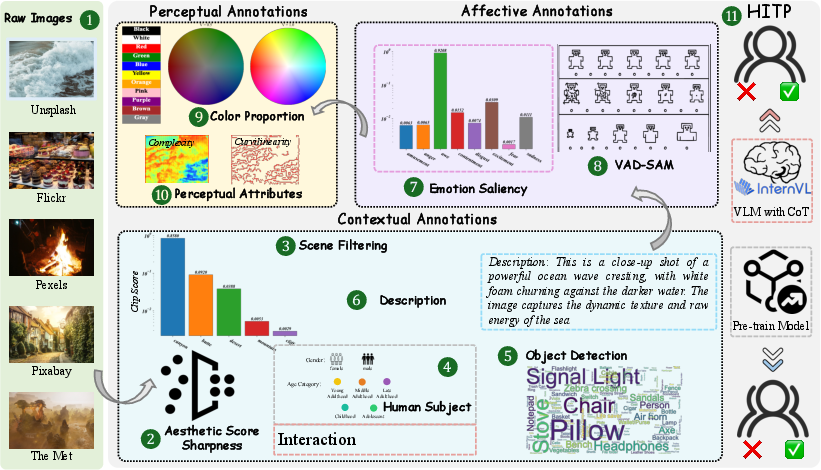
Figure 2: Dual-Space Annotation Pipeline, integrating automated and human-in-the-loop strategies for attribute fidelity and semantic consistency.
Representative samples of annotated images demonstrate how the dual-space provides robust ground truth for both affect and low-level perceptual aspects.
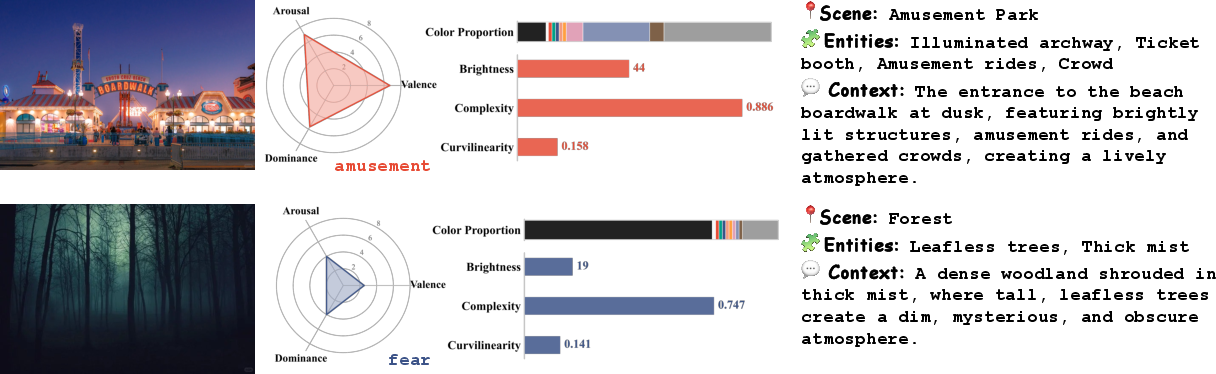
Figure 3: Representative examples of EmoScene's dual-space annotations, highlighting joint affective and perceptual signals.
Affective and Perceptual Space Analysis
Affective Space
The embedding of discrete emotions in the continuous VAD space reveals distributional overlaps and distinctive clustering consistent with the psychological circumplex model. Categories such as "fear" and "anger" map to low-valence, high-arousal; "contentment" and "amusement" cluster in high-valence regions, with substantial intra-class VAD spread supporting intensity modulation.
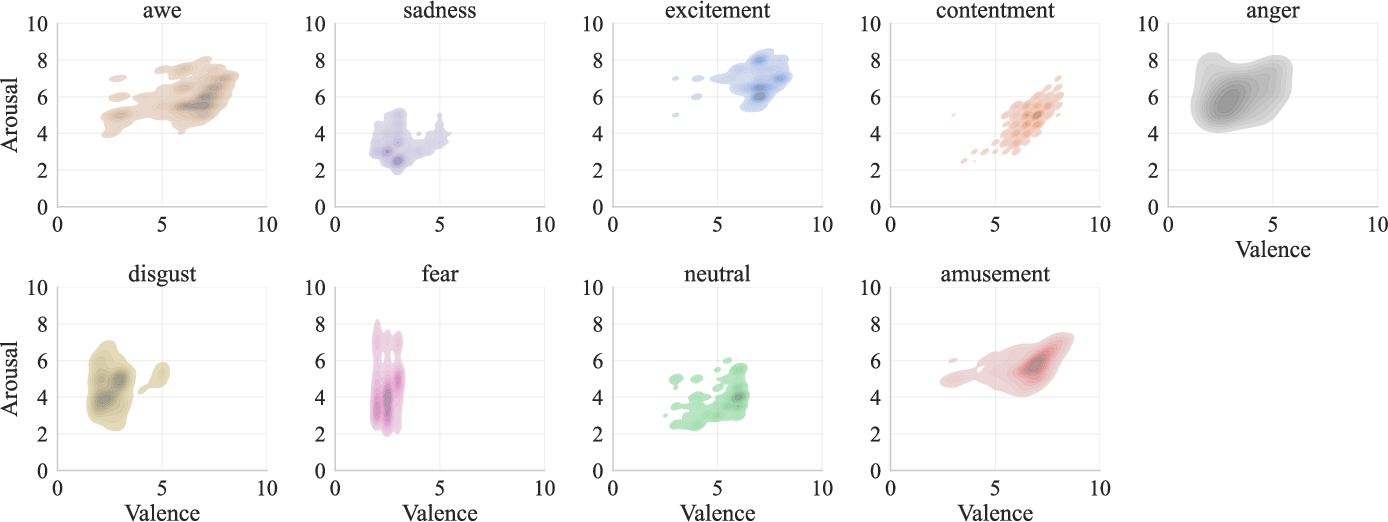
Figure 4: Structure of the affective space in the Valence–Arousal plane, visualizing the continuous distribution of emotions.
Perceptual Space
Emotion classes are associated with distinct color statistics: low-valence classes are predominantly darker, high-arousal with greater chromatic contrast, and distinct hue distributions for specific affects. These patterns provide direct alignment between affective intent and perceptual rendering.
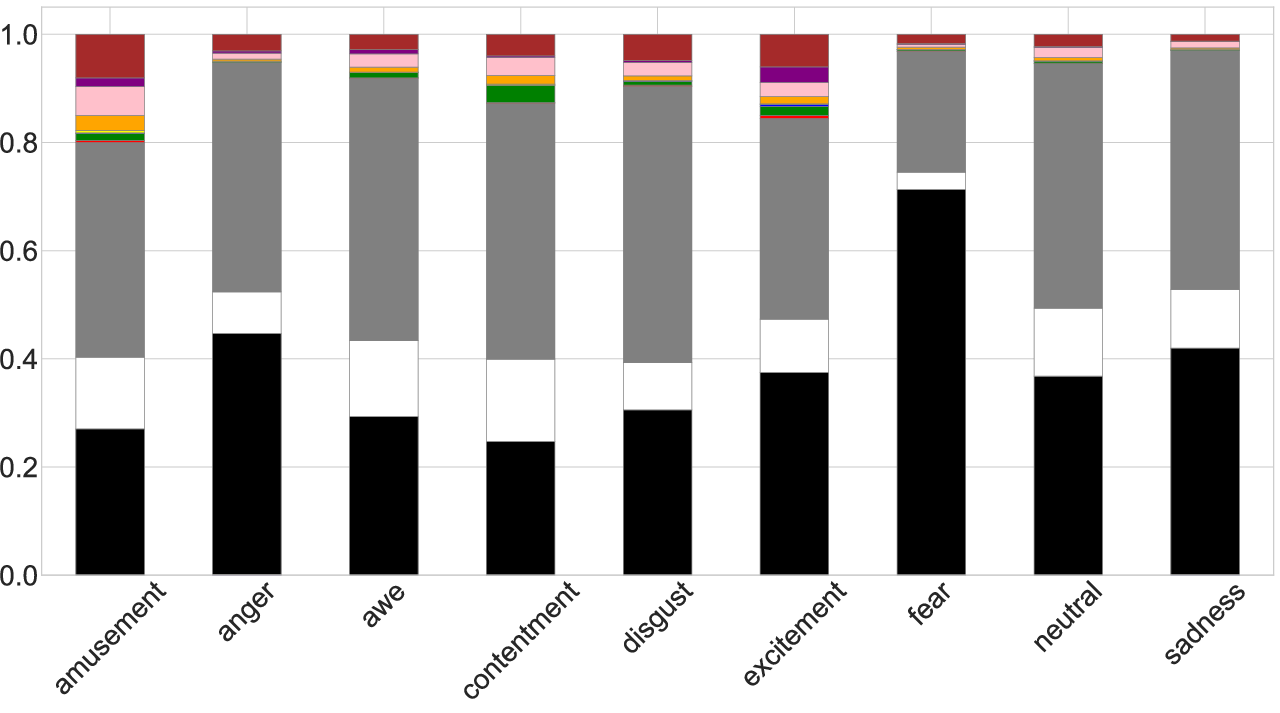
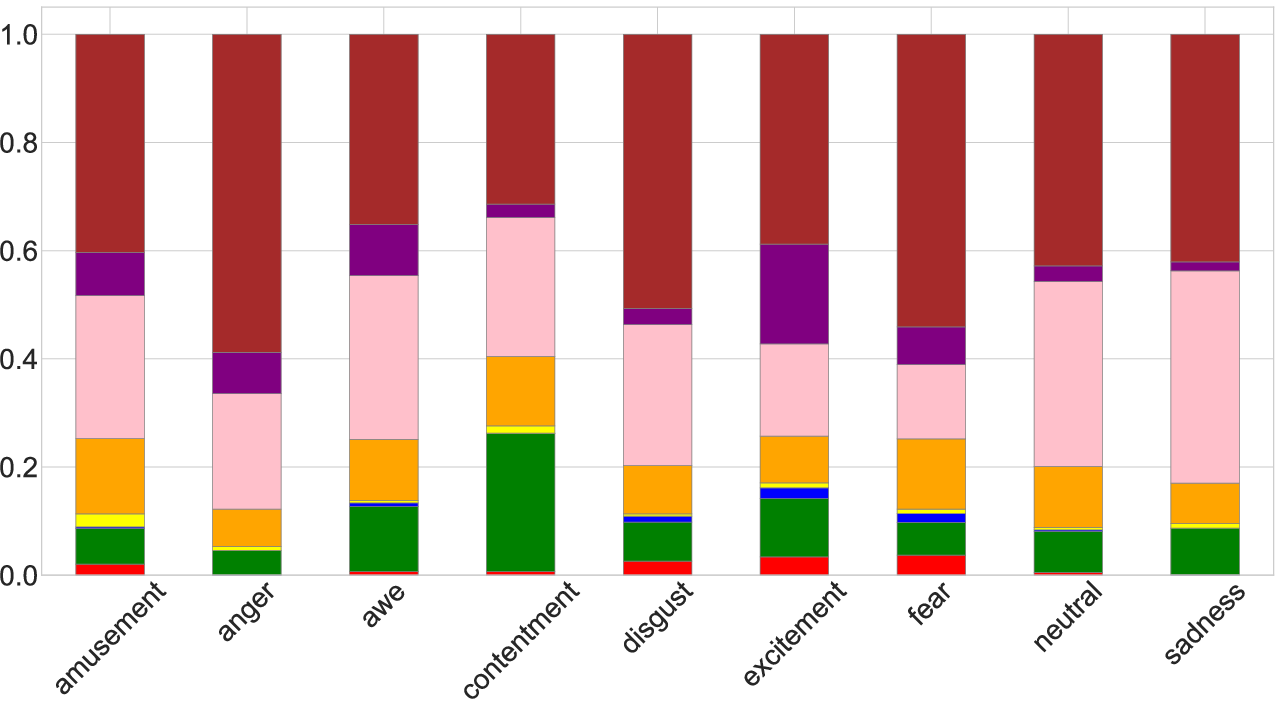
Figure 5: Perceptual color composition across emotion categories; top, achromatic/chromatic ratios; bottom, chromatic hue distributions per emotion.
Quantitative correlation analysis reveals moderate coupling between valence and brightness/complexity, weak to arousal and curvilinearity, and negligible correlation between dominance and low-level features—supporting the necessity of dual-space modeling for controllable affect.
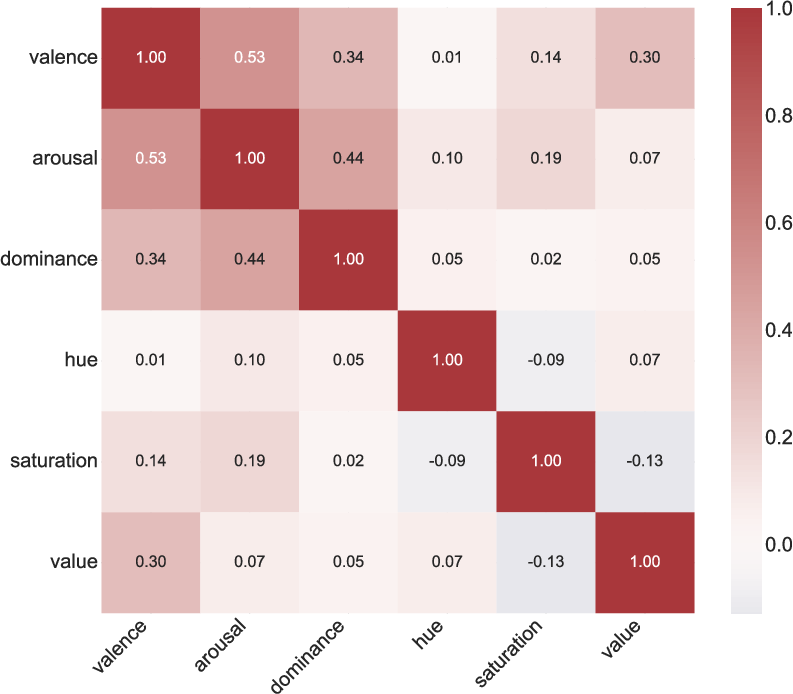
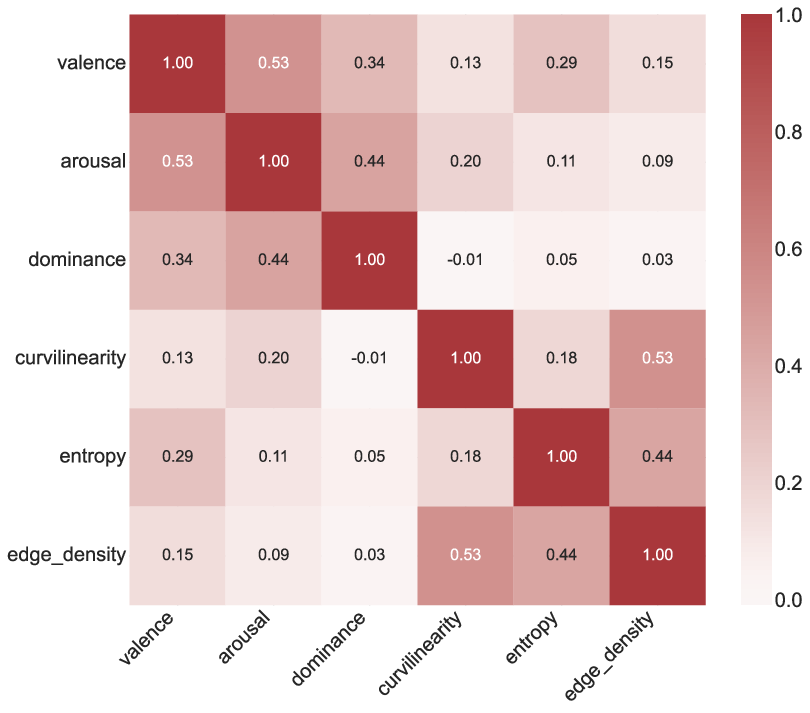
Figure 6: Interplay between affective and perceptual spaces, showing correlations between VAD and HSV/structural statistics.
Annotation Reliability and Bias Mitigation
HITL verification demonstrates high reliability; 91.2% accuracy for discrete emotions, low MSE for VAD triplets, and κ=0.85 multi-rater agreement. Stress-tests against counterintuitive samples (e.g., fireworks—dark but positive, static sports moments—bright but negative) confirm annotations are not reducible to shallow visual heuristics.

Figure 7: Visual proofs of bias mitigation in EmoScene, illustrating counterintuitive affective labels justified by deep contextual understanding.
Dual-Space Modulation for Controllable Generation
The reference baseline leverages EmoScene by conditioning a frozen PixArt-α text-to-image diffusion backbone via shallow Affective–Perceptual Modulation (APMV). Text prompts, VAD values, and HSV descriptors are fused into a control vector that perturbs only the cross-attention layers of the generator. This method eschews architectural novelty in favor of exposing the dataset's diagnostic value for affect–perceptual controllability.
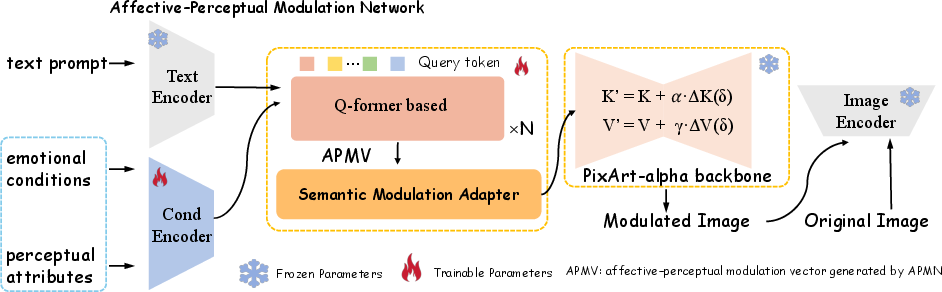
Figure 8: Overview of the dual-space modulation baseline, integrating affective–perceptual signals into a frozen diffusion model via lightweight adapters.
Quantitative metrics show the modulated backbone improves VAD MAE (e.g., valence error drops from 2.54 to 1.48) and color MAE with minimal degradation in CLIPScore. Samples reveal that, under identical prompts and seeds, APMV yields more systematic and monotonic shifts in mood—colder, heavier atmospheres for negative affect; brighter for positive—while maintaining semantic content.

Figure 9: Effect of APMV modulation: The modulated model produces more negative affect aligned with the target, contrasted with baseline neutrality.

Figure 10: Continuous control along valence and arousal: smooth, consistent affective transitions along the V–A space.
Extended evaluations show that APMV genuinely affords intuitive, fine-grained navigation in affective space, as opposed to brittle, non-monotonic effects under discrete prompt editing.

Figure 11: Motivation for dataset-grounded continuous affect control: smooth and reliable modulation via EmoScene’s VAD and perceptual controls, contrasting with failed prompt-only approaches.
Limitations and Future Directions
While the baseline achieves notable improvements, HSV-driven perceptual modulation remains weak—color sliders yield subtle changes, indicating that richer color–affect coupling mechanisms are needed. The groundwork is laid for future studies on integrating deeper perceptual control branches, and expanding to cross-modal tasks (e.g., VQA, narrative generation, interactive demos).
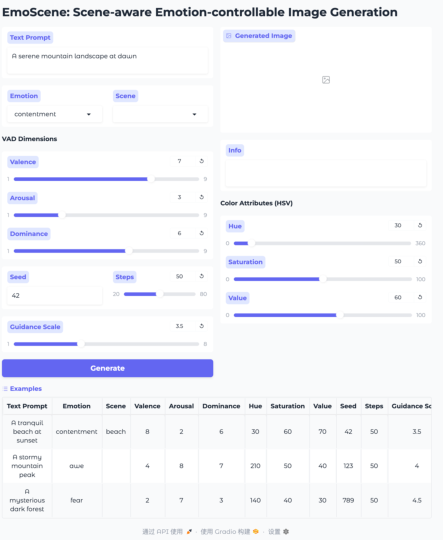
Figure 12: Interactive demo, with Emotion, VAD, and HSV controls for real-time, continuous affect–perception navigation.
Conclusions
"EmoScene: A Dual-space Dataset for Controllable Affective Image Generation" establishes an empirically robust foundation for research at the intersection of affective computation and image synthesis. By jointly annotating 1.2M images across affective and perceptual dimensions, EmoScene enables the development and benchmarking of generative models with precise, dataset-grounded emotional control. The lightweight modulation baseline demonstrates the utility of dual-space conditioning on a state-of-the-art frozen generator. Implications include advancing affect-controllable editing, facilitating fine-grained VAD-aligned synthesis, and inspiring future architectures that more deeply intertwine affective intent with perceptual realization. EmojiScene is positioned as a benchmark for the next generation of affect-aware visual synthesis and analysis systems.

