- The paper introduces EmoNet-Voice, offering two datasets—EmoNet-Voice Big with 4500+ hours of synthetic speech and EmoNet-Voice Bench with expert annotations.
- The methodology leverages state-of-the-art TTS synthesis and refined Whisper encoders with regression heads to capture detailed emotion intensity.
- Empirical evaluations show superior recognition of high-arousal emotions while revealing challenges in accurately detecting lower-arousal, cognitive states.
EmoNet-Voice: A Fine-Grained, Expert-Verified Benchmark for Speech Emotion Detection
Introduction
This paper introduces EmoNet-Voice, a novel multi-faceted resource for Speech Emotion Recognition (SER) aimed at addressing core limitations present in existing datasets such as insufficient emotional granularity, lack of representativeness, and restricted scalability. Two complementary datasets are provided: EmoNet-Voice Big, a synthetic corpus for pretraining models on a broad spectrum of 40 emotion categories and multiple languages, and EmoNet-Voice Bench, a tightly curated benchmark with psychology expert annotations assessing both emotional presence and intensity.
EmoNet-Voice Big provides over 4,500 hours of emotion-labeled synthetic speech data across diverse voices and languages (English, German, Spanish, French), generated via state-of-the-art text-to-speech models. This synthetic approach allows privacy-conscious inclusion of sensitive emotions typically absent in SER datasets. EmoNet-Voice Bench comprises 12,600 audio samples annotated by experts to ensure heightened taxonomy fidelity.
Building upon these datasets, EmpathicInsight-Voice models achieve remarkable agreement with human experts, particularly proficient in recognizing high-arousal emotions like anger, outperforming existing methods. Evaluations reveal critical insights into the capabilities of modern SER paradigms, emphasizing an evident performance gap with lower arousal states like concentration.
Dataset Construction
Emotion Taxonomy
EmoNet-Voice leverages a 40-category taxonomy capturing a diverse emotional palette, enabling nuanced distinction beyond basic emotions. This taxonomy includes positive, negative, cognitive, and socially-mediated emotions, aligning with constructionist theories in affective science.
EmoNet-Voice Big
Using the powerful GPT-4 OmniAudio model, EmoNet-Voice Big synthesizes a large collection of emotionally expressive voice samples to simulate authentic prosody and timbre. Audio snippets range from 3 to 30 seconds, exploring diverse linguistic and gender identities. This dataset, massively scalable and multilingual, serves as an open-resource for extensive SER and TTS research.
EmoNet-Voice Bench
EmoNet-Voice Bench is a benchmark annotated by human experts, providing nuanced multi-label emotion ratings. This annotation framework is structured with a rigorous consensus protocol to establish reliable intensity markers across its 40-category taxonomy. The detailed agreement distribution is visually depicted (Figure 1).
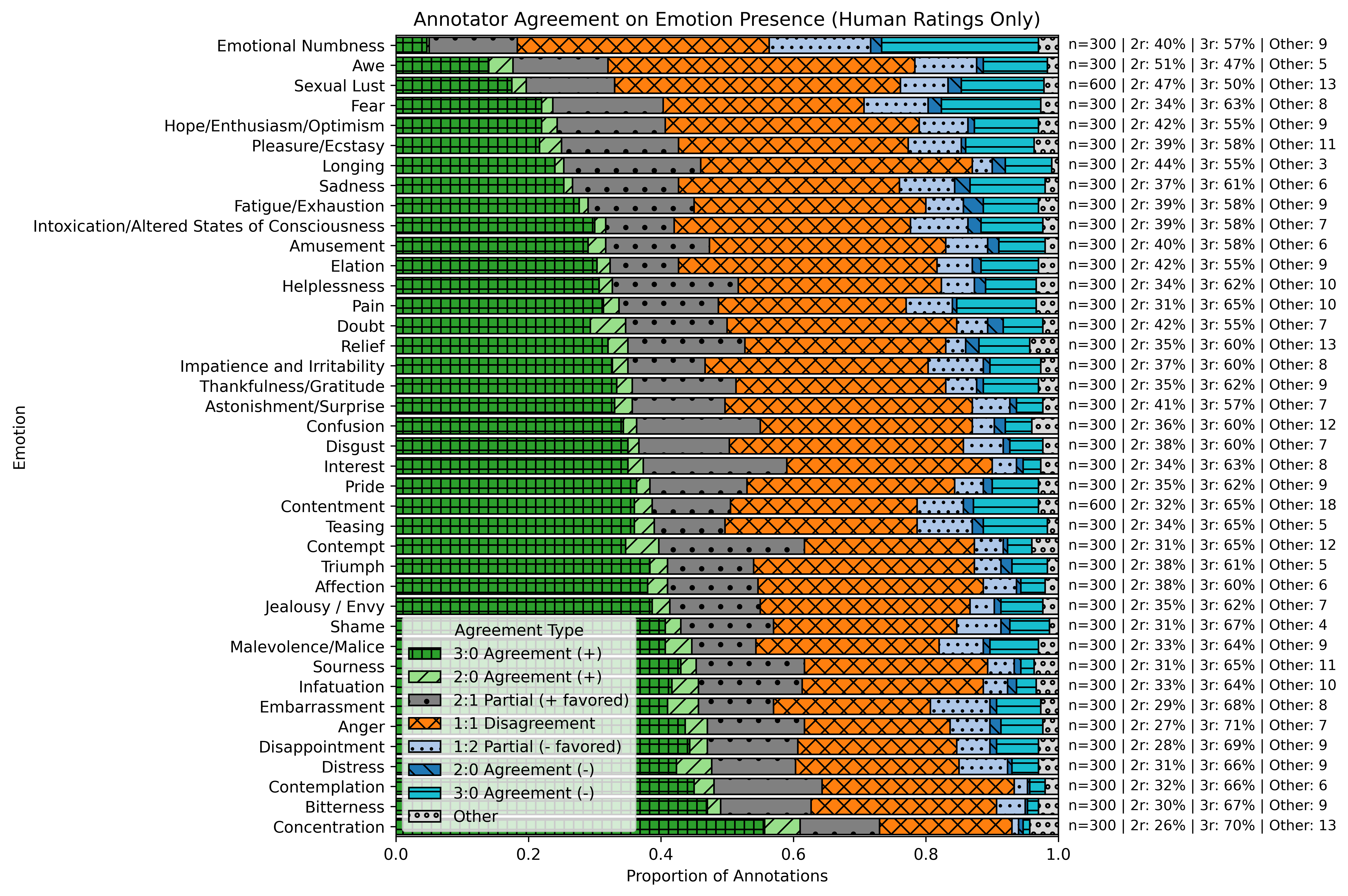
Figure 1: Annotator agreement for human ratings on perceived emotions in audio samples, highlighting the distribution of agreement types.
EmpathicInsight-Voice: State-of-the-art SER Models
EmpathicInsight-Voice models represent a pivotal enhancement in SER capabilities, overcoming limitations of existing architectures. Designed using continuously trained Whisper encoders with specialized MLP regression heads, these models leverage the comprehensive EmoNet-Voice Big dataset in two stages. Initially, generalized emotional representations are built, followed by training focused regression heads to optimize emotion intensity prediction based on multi-dimensional audio embeddings.
Our evaluations on EmoNet-Voice Bench indicate EmpathicInsight-Voice's superiority over existing SER models (Gemini, GPT-4o, Hume Voice), particularly in low-refusal and high correlation metrics (Table 1). Significantly, performance on high-arousal emotions is consistently stronger compared to low-arousal or cognitive emotional states which remain challenging.

Figure 2: Instructions given to the human annotator for the expert annotation of EmoNet-Voice Bench.
Discussion
The relationship between annotator agreement and model performance underscores the inherent complexity in subjective emotional recognition tasks. Notably, high-arousal emotions tend to produce distinctive acoustic cues that are captured adeptly by current models. Contrarily, cognitive emotions, reliant on nuanced context not immediate prosodic features, warrant advancements in context-aware modeling frameworks. Recognizing these biases is crucial for real-world applications.
Conclusion
EmoNet-Voice provides a rigorous foundation for SER advancement through its expansive synthetic dataset and expert-validated benchmark. It holds potential for evolving next-generation SER systems and facilitating expressive virtual interactions. Future research should aim to integrate contextual attributes and explore robust multimodal processing, ultimately bridging cognitive recognition gaps in AI-assisted human communication.
References
- Schuhmann et al., "EmoNet-Face," 2025.
- Radford et al., "Whisper," 2023.
- Barrett, L. F., "Theory of Constructed Emotion," 2017.

