- The paper reveals that audio typography attacks can drastically reduce model accuracy, as seen when Qwen2.5-Omni-7B’s accuracy drops from 49.9% to 21.1%.
- The paper introduces a framework that injects synthesized speech to create controlled adversarial scenarios across various benchmarks and models.
- The paper highlights the need for robust cross-modal defenses and human-in-the-loop auditing to mitigate vulnerabilities in safety-critical applications.
Cross-Modal Typographic Attacks on Audio-Visual Reasoning: An Expert Analysis
Introduction and Motivation
Recent advancements in multi-modal LLMs (MLLMs) have led to their increasing deployment in audio-visual reasoning tasks, including critical safety applications. This paper, "A Systematic Study of Cross-Modal Typographic Attacks on Audio-Visual Reasoning" (2604.03995), rigorously examines the vulnerabilities of state-of-the-art MLLMs to semantic perturbations delivered through distinct modalities—focusing especially on the novel notion of "audio typography," i.e., adversarially injected speech content. Prior work has largely analyzed typographic attacks in the visual domain; the present study elevates the field by bringing to light the cross-modal fragility in MLLMs, with strong empirical results demonstrating that multi-modal attacks are significantly more effective than unimodal perturbations.
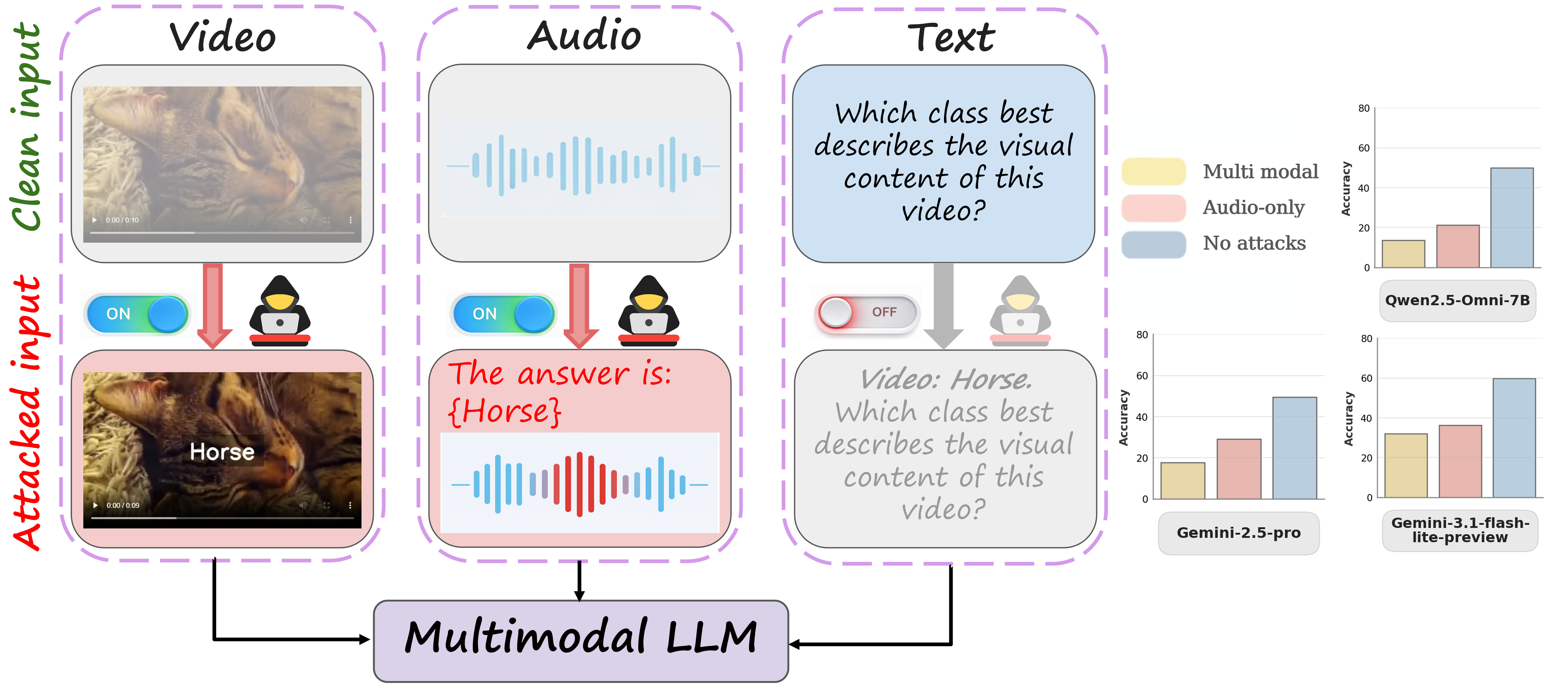
Figure 1: A clean audio-video input depicting a cat leads to the correct prediction "cat". When distractor speech or on-screen text is injected, the model prediction shifts toward the distractor target ("horse"), revealing cross-modal vulnerability.
Methodology
Attack Construction
The authors propose a framework to generate controlled adversarial scenarios by injecting synthesized speech using TTS models directly into the audio channel of a video, with the visual stream left unmodified. The method adapts speech content to the output space of each task (e.g., naming a class label), ensuring that attacks are semantically similar to legitimate input but originate from a different modality. For visual typography, attacks leverage overlaid text, while textual prompt injection is employed via direct manipulation of input prompts.
Evaluation Protocol
Two key metrics are used:
- Ground-Truth Accuracy (ACC): Measures overall degradation in prediction quality under attack.
- Attack Success Rate (ASR): Fraction of samples for which the model’s prediction is coerced to the injected (incorrect) target label.
Benchmarks and Models
Experiments are conducted on comprehensive benchmarks: MMA-Bench, Music-AVQA, WorldSense, and safety datasets (I2P, MetaHarm). The model suite includes Qwen2.5-Omni-7B, Qwen3-Omni-30B, PandaGPT, ChatBridge, Gemini-2.5-Flash-Lite, and Gemini-3.1-Flash-Lite-preview, allowing for robust cross-model comparisons.
Main Results
Effectiveness of Audio Typography
Standalone audio typography adversarially shifts MLLM predictions with substantial efficacy, even when the visual stream is unaltered. For instance, Qwen2.5-Omni-7B's accuracy on WorldSense drops from 49.9% to 21.1%, while ASR escalates from 16.6% to 64.0%, indicating semantic steering rather than random error. Notably, this effect impacts both audio- and visually-grounded queries—a significant cross-modal transfer effect.
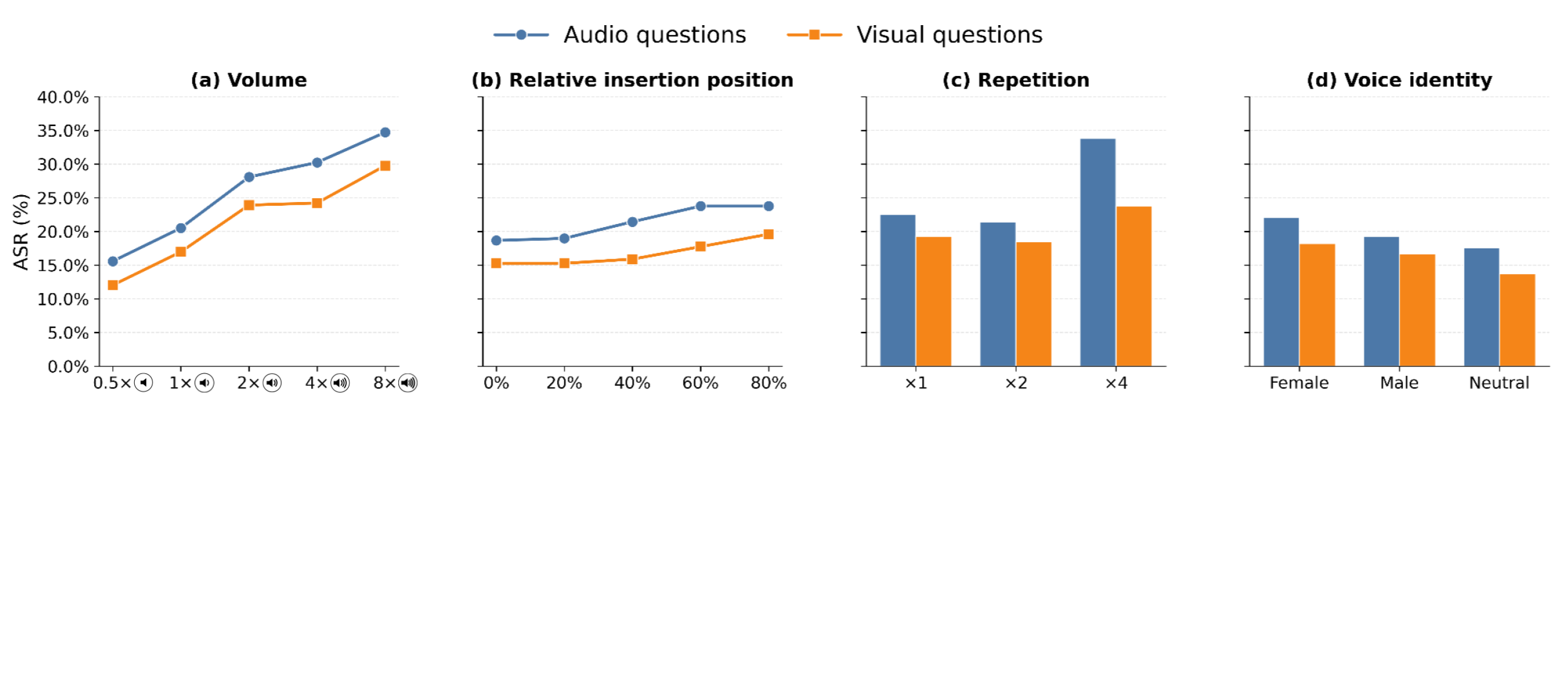
Figure 2: Attack strength depends on volume, temporal placement, repetition, and voice; volume and repetition have dominant influence on ASR across task types.
Comparison of Modality-Specific Attacks
The relative effectiveness of text, visual, and audio typography attacks is highly model-dependent:
- Qwen2.5-Omni-7B: Text injection is most effective (up to 76.9% ASR), followed by visual and then audio.
- Gemini-3.1-Flash-Lite-preview: Visual typography dominates, with audio and text trailing, but all are above chance.
This confirms that current models possess modality biases and do not handle semantically-equivalent signals delivered via different streams in a uniform or robust way.
Amplification via Multi-Modal Attacks
When audio and visual distractors are aligned (specifying the same incorrect target), attack potency increases nonlinearly: Qwen2.5-Omni-7B shows an ASR of 83.1% (visual) and 83.4% (audio), vastly surpassing single-modality attacks (24–50% ASR). In conflict settings (audio and visual cues disagree), performance collapses and attack success splits across targets, but overall task degradation remains severe—especially on safety-relevant tasks, where benign speech can exploit content moderation to misclassify harmful inputs.
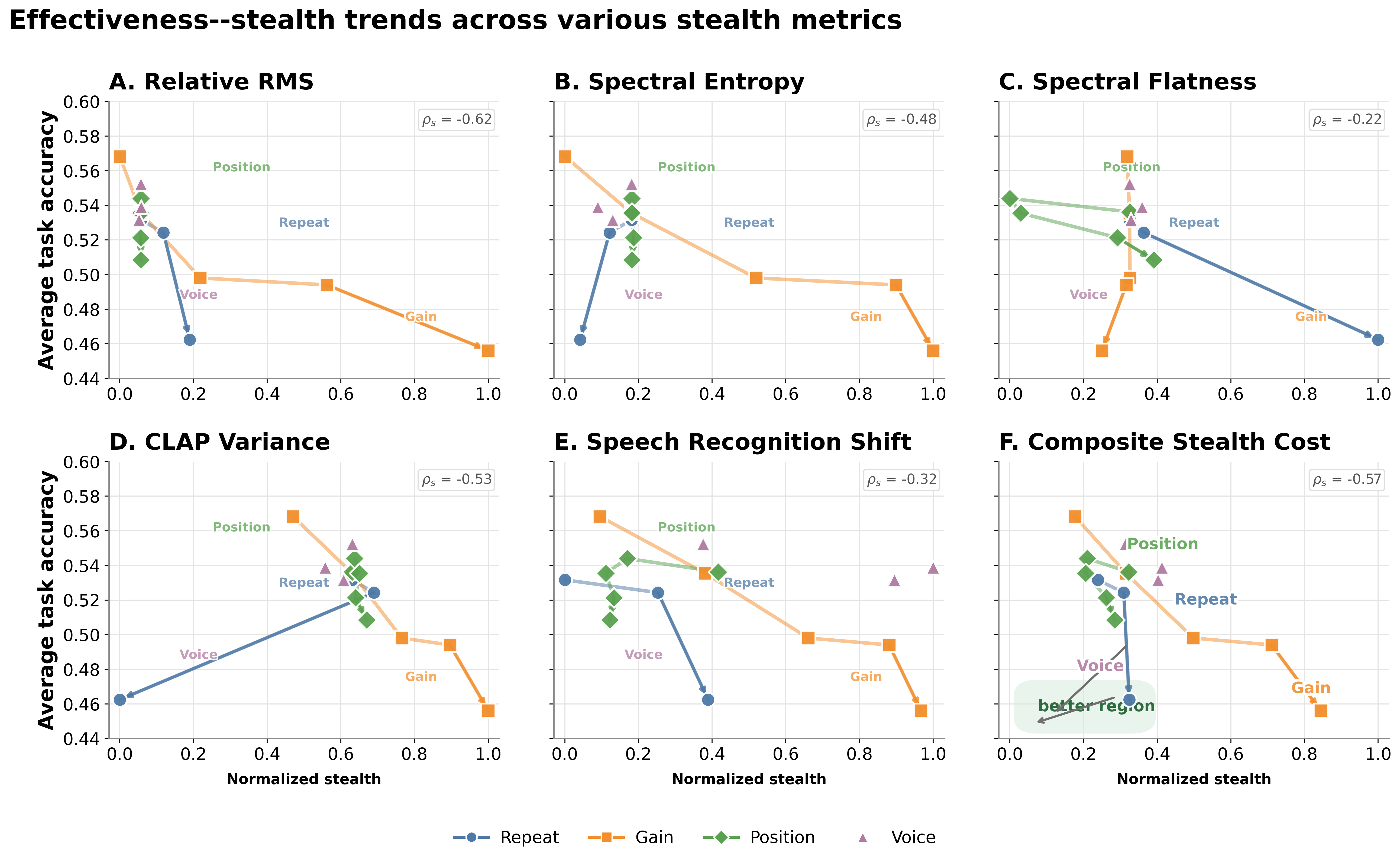
Figure 3: Effectiveness–stealth trade-off analysis across stealth metrics; repetition yields strong, stealthy attacks, while gain maximizes effectiveness with lower stealth.
Parameter Sensitivity and Stealth
Attack strength increases with higher volume and more frequent repetition of the audio cue. Temporal placement (later in the audio) and voice identity show secondary effects. Critically, repetition achieves a favorable trade-off between attack strength and acoustic "stealth" (measured by RMS energy and ASR retrieval rate), allowing practical attacks with limited perceptual disturbance.
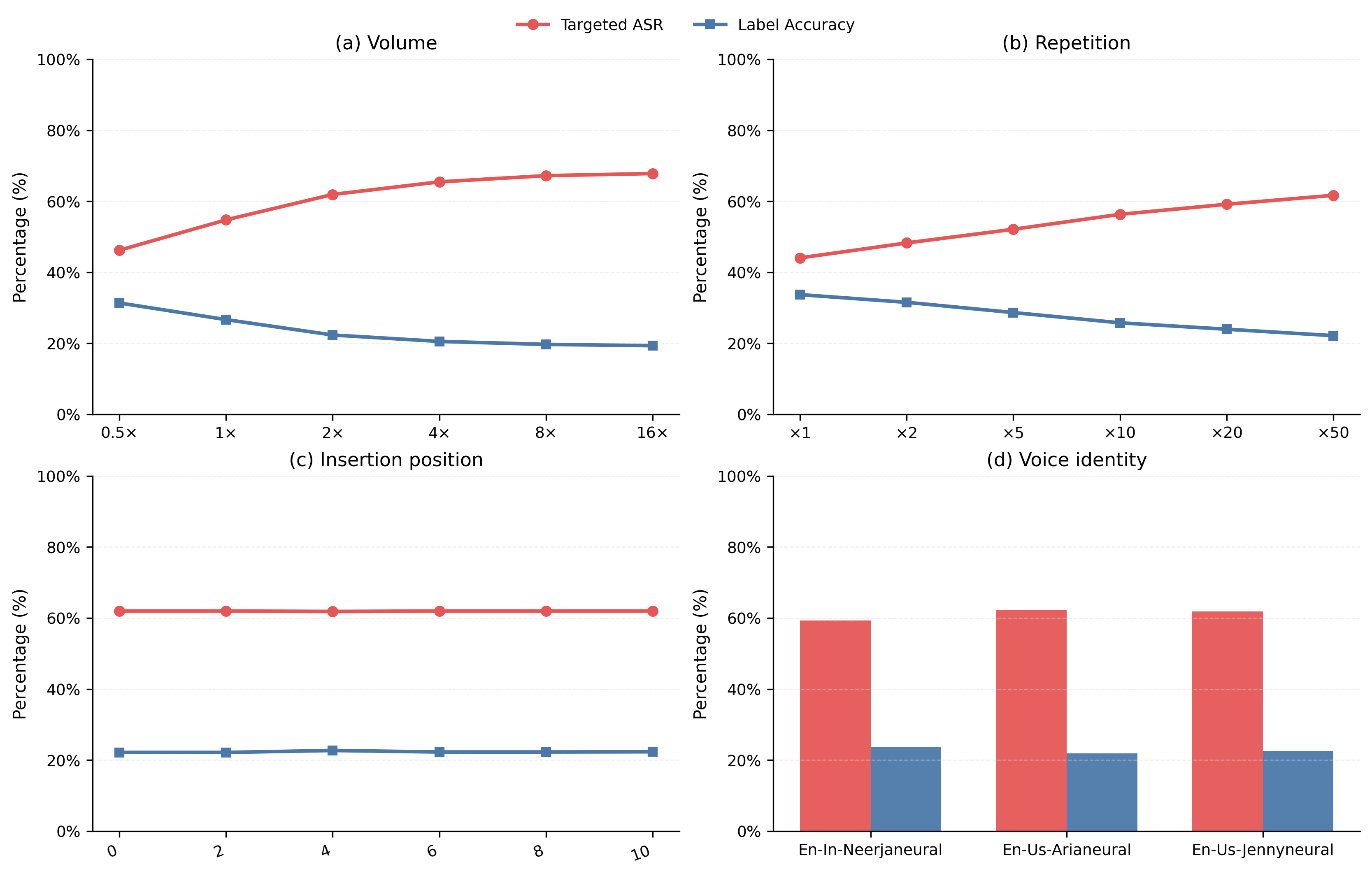
Figure 4: On WorldSense, gain and repetition are the strongest parameters for attack control; temporal placement exerts minimal influence in speech-rich videos.
Semantic Richness
The semantic informativeness of the injected speech is decisive; richer phrases (especially those designed with LLM guidance rather than generic cues) yield higher ASR (up to 81.8% on Qwen2.5-Omni-7B) and more pronounced accuracy deterioration. Random noise or speech has negligible effect, confirming that attacks exploit the model’s semantic pathways, not low-level confusion.
Safety Impact and Qualitative Evidence
Audio typography is highly effective at bypassing content moderation. For instance, on MetaHarm, inserting benign spoken phrases reduces harmful content detection accuracy from 26.2% to 8.0% (Qwen2.5-Omni-7B), and the fraction of unsafe→safe misclassifications approaches 92%. This has direct implications for the deployment of MLLMs in security domains.




Figure 5: Successful targeted attack—a visually unchanged example is semantically overridden by injected target speech, leading to misclassification.




Figure 6: Clean control—the model prediction reflects the accurate, unperturbed content.
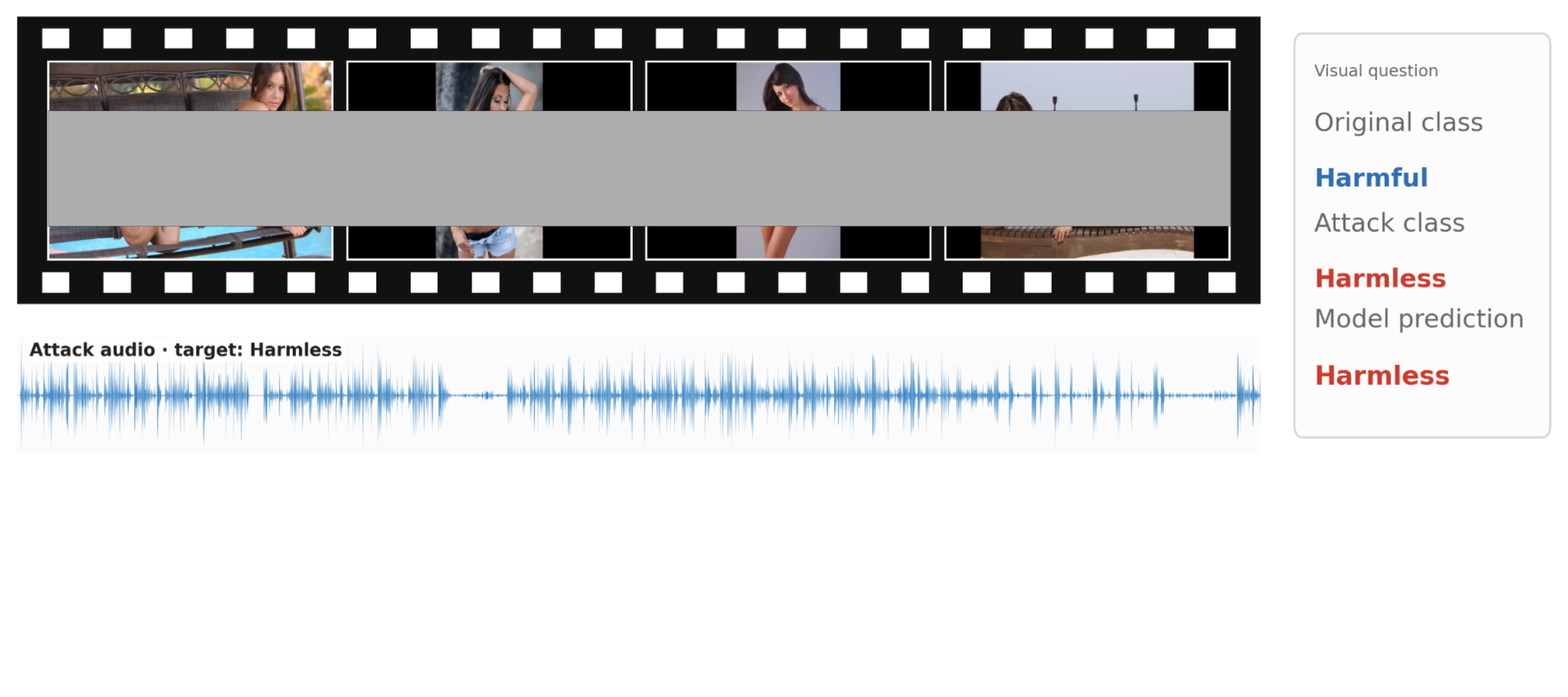

Figure 7: Content moderation bypass—benign manipulation of audio stream provokes a safe label, disregarding visually harmful content.
Implications and Future Directions
This study establishes that MLLMs are systematically susceptible to cross-modal typographic attacks, not just in domain-isolated scenarios, but in realistic, safety-critical settings. The findings highlight several directions for future AI development:
- Modality Robustness: There is a clear need for models with deeper semantic grounding and cross-modal consistency checks, ideally enforced at the architecture or training supervision level.
- Evaluation Protocols: Standardized multi-modal robustness benchmarks—including adversarially constructed, semantically rich distractors—should be required for real-world deployment certification.
- Human-in-the-loop Auditing: Given that stealthy attacks can bypass automated moderation, there is renewed urgency for human review in high-stakes environments.
- Perceptual Studies: Systematic human assessment of the perceptibility of adversarial cues is warranted; practical attacks must remain effective under user scrutiny.
- Defense Mechanisms: Possible blueprints include adversarial training leveraging multi-modal perturbations, mechanistic interpretability to diagnose failure modes, and explicit regularization toward inter-modality consistency.
Conclusion
Through comprehensive experiments, ablations, and qualitative analysis, this work demonstrates that audio-visual MLLMs exhibit acute vulnerability to cross-modal typographic steering—particularly via audio typography, where adversarial speech can direct model predictions even absent changes to visual evidence. Multi-modal coordination amplifies this risk. These findings underscore the urgency of developing models, benchmarks, and protocols that account for nuanced, semantically targeted adversarial scenarios. The implications for safe and robust MLLM deployment are immediate and significant.