- The paper introduces DDCL-Attention, a prototype-based competitive readout layer that avoids prototype collapse using a theoretically grounded loss decomposition.
- It stabilizes training dynamics via time-scale separation and reduces complexity to O(TK), outperforming traditional pooling methods.
- Empirical results across clustering, text representation, vector quantization, and hierarchical compression demonstrate robust, interpretable performance.
Introduction and Motivation
The work introduces DDCL-Attention, a prototype-based competitive readout layer for transformer encoders that replaces heuristic pooling (e.g., averaging or class token extraction) with a principled, theoretically grounded compression mechanism. By leveraging a global bank of learned prototype vectors and probabilistic token-to-prototype assignment, this layer outputs a weighted sum of these prototypes per token, maintaining O(TK) complexity relative to sequence length T and number of prototypes K, thus significantly reducing computational overhead compared to conventional O(T2) self-attention.
Several key deficiencies in existing prototype-based mechanisms such as Slot Attention and Perceiver architectures are specifically addressed:
- Prototype collapse (all prototypes degenerating to the same point) is avoided by an exact decomposition of the training loss, which enforces separation via a non-negative diversity term.
- Training dynamics stability is formally analyzed. The coupled encoder-prototype system is proven stable under a time-scale separation, leveraging Tikhonov's singular perturbation theory.
- Paradigm flexibility: The mechanism is validated as a readout layer, in differentiable vector quantization (VQ), and in hierarchical document compression, each with distinct theoretical motivation.
Distinctly, DDCL-Attention is mathematically characterized by an exact loss decomposition:
L=LOLS+V
where LOLS is the ortho-least-squares (reconstruction) term, and V≥0 is the prototype separation (diversity) term. The assignments of tokens to prototypes are soft (Boltzmann) and differentiable. The encoder receives a gradient that pushes embeddings toward their assigned soft centroids (∇θL=2(z−μ)), acting as a continuous compression signal.
Stability is rigorously treated under both local linearization and global Lyapunov analysis, leading to the explicit guideline that for stable joint training, the encoder's learning rate ηθ must be substantially smaller than the prototypes' learning rate ηP (T0). This time-scale separation is proven necessary; violation results in prototype collapse, as shown empirically.
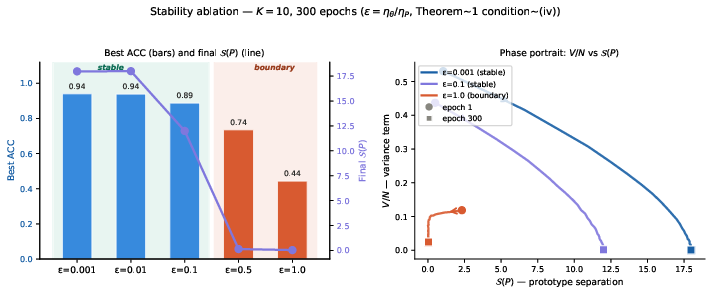
Figure 1: Clustering accuracy and prototype separation as a function of learning rate ratio T1. Stability and non-collapse are assured only when T2.
Compared to slot-based or cross-attention latent architectures, DDCL-Attention distinguishes itself by:
- Global, static prototypes versus dynamic, sequence-dependent keys (as in self-attention).
- No iterative inference at evaluation: a single pass suffices, removing a major computational bottleneck present in Slot Attention-based methods.
- Guaranteed prototype activity: All prototypes are always active in gradient flow due to the algebraic structure of the loss (zero dead codes, full codebook utilization).
- Training diagnostics (T3 for separation and T4 for assignment entropy) serve as reliable health indicators.
Empirical Validation
The methodology is validated across four classes of experiments:
Unsupervised Tabular Clustering
On an orbital debris classification benchmark with tabular features, the model achieves clustering accuracy superior to T5-means while perfectly adhering to the decomposition constraint and maintaining separated, interpretable prototypes in both 2D and higher-dimensional projections.
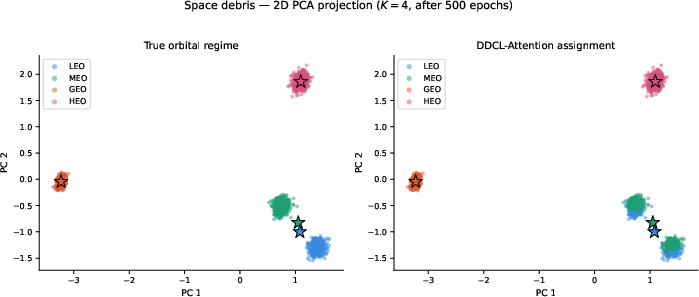
Figure 2: 2D PCA projection of space debris; true orbital regime (left), DDCL-Attention assignments (right). Stars denote prototype positions.
Text Representation (Transformer Readout)
Applied as a readout atop frozen BERT for sentiment (SST-2, IMDB) and unsupervised 20 Newsgroups clustering, DDCL-Attention matches or exceeds classical pooling in accuracy, with precise monitoring of prototype geometry and assignment entropy throughout training.
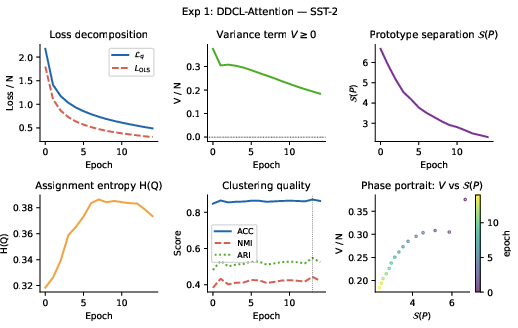
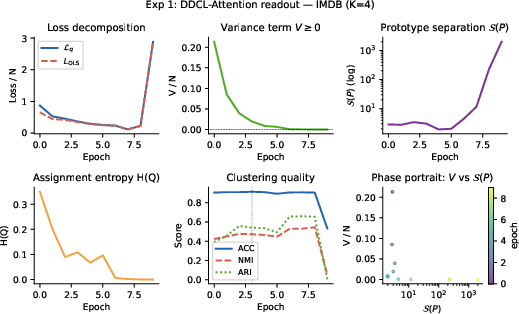
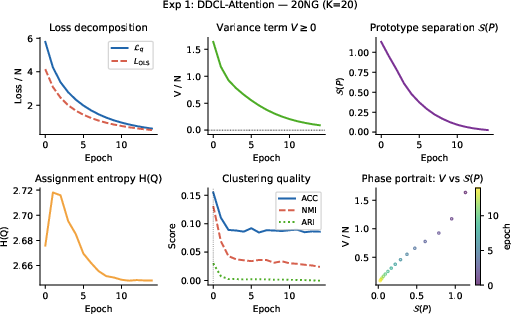
Figure 3: Training dynamics on SST-2, IMDB, and 20 Newsgroups, featuring loss decomposition, prototype separation, entropy, and clustering quality.
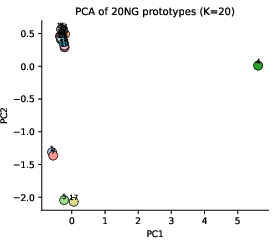
Figure 4: Prototypes learned on 20 Newsgroups visualized via PCA, displaying well-separated clusters.
Soft Vector Quantization (VQ)
When replacing the hard assignment of VQ-VAE on CIFAR-10, DDCL-Attention achieves 100% codebook utilization from epoch 1, in contrast to hard VQ that is slow to populate all codes. This demonstrates the efficacy of the anti-collapse force and the absence of dead codes.
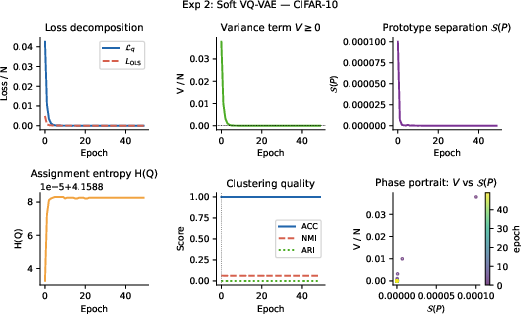
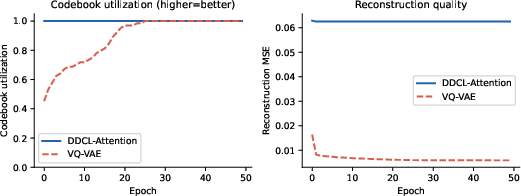
Figure 5: Left: Training dynamics and codebook utilization, DDCL-Attention vs. VQ-VAE. Right: DDCL-Attention reaches complete utilization immediately, unlike hard VQ.
Hierarchical Compression
In stacked configurations (two-level), each competitive layer maintains its own diversity constraint without interference, guaranteeing prototype activity at each level and confirming theoretical predictions of simultaneous, non-interfering separation forces.
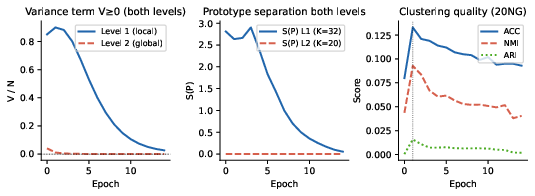
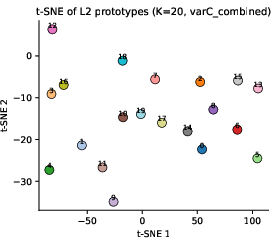
Figure 6: Hierarchical DDCL-Attention on 20 Newsgroups, verifying non-negativity of variance and prototype separation at two levels.
Implications and Extensions
Practically, DDCL-Attention allows for interpretable, structured representation at transformer output, with straightforward integration into NLP, vision, scientific, and multimodal pipelines. Architecturally, it enables plug-and-play readout or codebook layers with mathematically guaranteed non-collapse, eliminating common pathologies in discrete representation learning (e.g., dead codes in VQ-VAE). The framework is also ideally suited for XAI via instance-prototype decompositions and transparent scalar metrics throughout training.
From a theoretical standpoint, DDCL-Attention provides an algebraically exact, universally applicable mechanism for enforcing separation among prototypes, which may influence future designs of prototype-based or dictionary-learning architectures in deep learning. The modularity and stability analysis template (via Tikhonov's theorem) can be generalized beyond transformer encoders, to convolutive and recurrent backbones with similar competitive readout requirements.
Limitations and Future Directions
Several conditional aspects remain: global end-to-end stability for arbitrary finite learning rates and overparameterized networks is not settled. Automatic selection of prototype counts or dimension is open, and DDCL-Attention is not a tool for modeling token-wise sequential dependencies—its inductive bias is compressive, not contextual. Applications to encoder-decoder VQ bottlenecks and more sophisticated integration strategies (parallel layer-gating, per-head adaptation, or inter-layer sharing) are open for exploration.
Conclusion
DDCL-Attention delivers a formally guaranteed, modular readout alternative for transformers, with proven prototype separation and codebook utilization, validated across modalities. Its contributions are both theoretical (stability and decomposition theorems, Lyapunov analysis) and practical (plug-in scalability, interpretable monitoring, dead-code elimination). The theoretical machinery and paradigm flexibility position it as a reference mechanism for prototype-based competitive learning in deep encoder architectures, with meaningful future extensions anticipated in stability proof and automatic architecture selection.