Dynamic Large Concept Models: Latent Reasoning in an Adaptive Semantic Space
Abstract: LLMs apply uniform computation to all tokens, despite language exhibiting highly non-uniform information density. This token-uniform regime wastes capacity on locally predictable spans while under-allocating computation to semantically critical transitions. We propose $\textbf{Dynamic Large Concept Models (DLCM)}$, a hierarchical language modeling framework that learns semantic boundaries from latent representations and shifts computation from tokens to a compressed concept space where reasoning is more efficient. DLCM discovers variable-length concepts end-to-end without relying on predefined linguistic units. Hierarchical compression fundamentally changes scaling behavior. We introduce the first $\textbf{compression-aware scaling law}$, which disentangles token-level capacity, concept-level reasoning capacity, and compression ratio, enabling principled compute allocation under fixed FLOPs. To stably train this heterogeneous architecture, we further develop a $\textbf{decoupled $μ$P parametrization}$ that supports zero-shot hyperparameter transfer across widths and compression regimes. At a practical setting ($R=4$, corresponding to an average of four tokens per concept), DLCM reallocates roughly one-third of inference compute into a higher-capacity reasoning backbone, achieving a $\textbf{+2.69$\%$ average improvement}$ across 12 zero-shot benchmarks under matched inference FLOPs.
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way for LLMs to “think” more efficiently. Instead of treating every word (token) equally, the model learns to group words into meaningful chunks called concepts, then does most of its deep thinking on these concepts. This saves effort on easy, predictable parts and focuses brainpower on the tricky, idea-changing parts.
Main Topic and Purpose
LLMs usually process text one token at a time and use the same amount of computation everywhere. But language isn’t uniform: some parts are repetitive or easy, and other parts introduce new ideas that need more thought. The paper proposes Dynamic Large Concept Models (DLCM), which:
- Automatically find boundaries where ideas change
- Compress sequences of tokens into variable-length concepts
- Spend more computation on reasoning about these concepts
- Then use that reasoning to guide the final word-by-word predictions
Key Questions
The paper explores three simple questions:
- Can a model learn where ideas begin and end without us telling it (not just sentences, but flexible concepts)?
- If we shift computation from tokens to concepts, can the model reason better without using more total compute?
- How do we build, train, and scale this kind of mixed system in a stable and efficient way?
How It Works (Methods and Analogies)
Think of reading a textbook:
- You skim predictable parts quickly (like “the,” “and,” “of”) and don’t think too hard.
- You slow down at new ideas, definitions, or surprising facts.
- You mentally group related words into chunks (like “The cat,” “sat on,” “the mat”) and reason over those chunks.
DLCM formalizes this with a four-stage pipeline.
Here’s a short list explaining the stages:
- Encoding: A small model reads raw tokens and makes a fine-grained “feature” for each word (like notes for each word).
- Dynamic Segmentation: The model looks for big changes between neighboring word features. When the change is large, that likely marks a new idea boundary. It then groups the tokens between boundaries into a concept.
- Concept-Level Reasoning: Tokens inside each concept are pooled into a single concept vector (like averaging notes for that chunk). A stronger “reasoning backbone” thinks deeply about the shorter list of concepts.
- Token-Level Decoding: Finally, a decoder uses the concept reasoning to help predict the next tokens, using a special attention mechanism that ensures the model only looks at concepts up to the current point in time (so it stays causal).
Key details explained simply:
- Boundary detection: The model measures how similar two adjacent token features are. If they’re very different, that suggests a new concept is starting. During training, it samples boundaries to explore; during inference, it uses a threshold rule (e.g., “if difference ≥ 0.5, make a boundary”).
- Pooling: Inside each concept, it averages the token features, then projects them into a “concept” space. This makes the sequence shorter (e.g., 4 tokens per concept on average if R=4), which cuts attention costs.
- Adaptive compression: The model is encouraged to hit a target average chunk size (like 4 tokens per concept) across the whole training batch but can make chunks longer or shorter depending on content. This lets it compress easy text more and spend more steps on dense, complex parts.
- Cross-attention for decoding: The decoder queries the concept sequence to help predict tokens. To make this fast on GPUs, the authors “replicate” concepts so keys and values line up with token positions, allowing standard high-speed attention kernels.
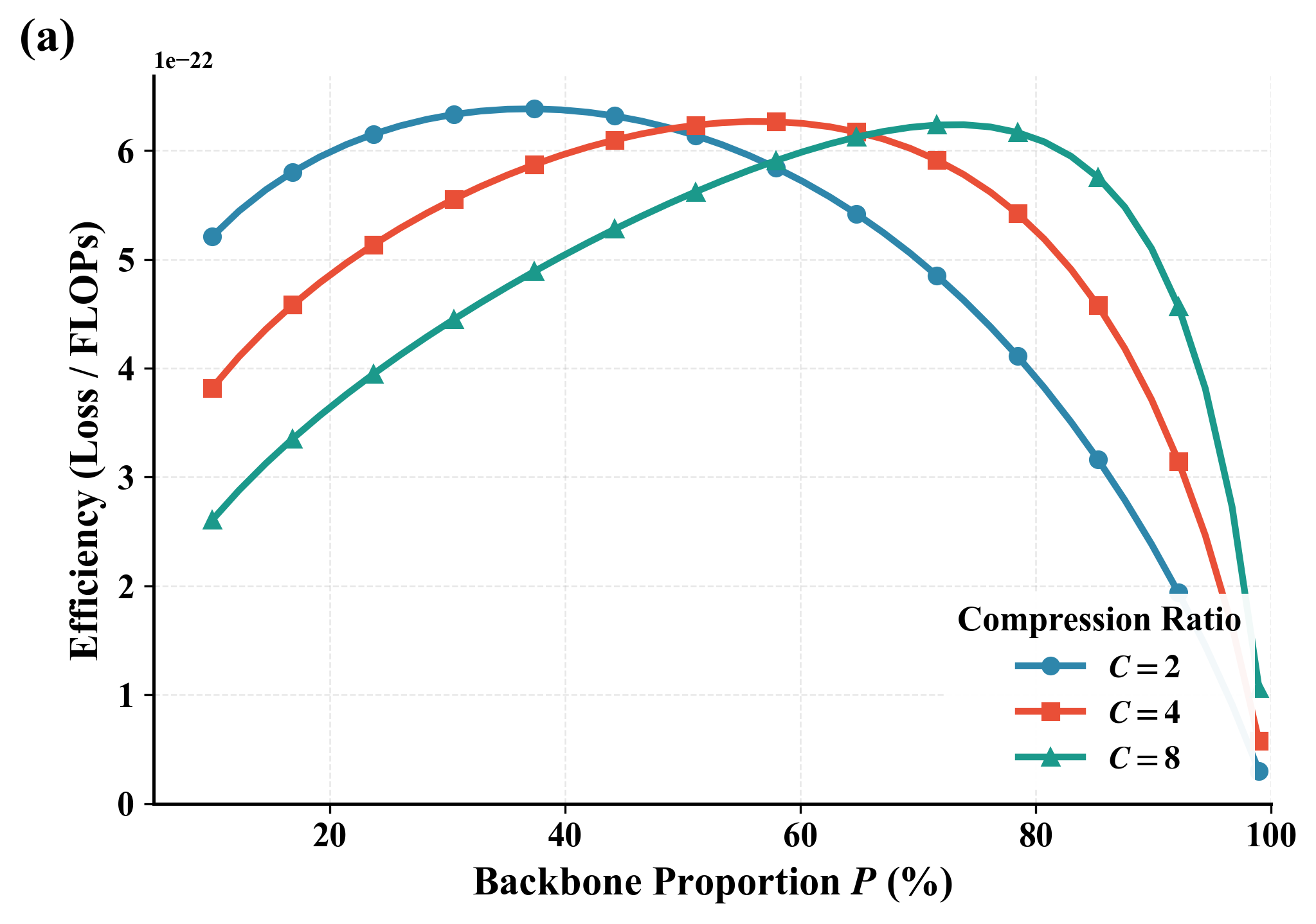
- Compression-aware scaling law: They introduce a new rule-of-thumb for designing these models under a fixed compute budget. It separates three ingredients: token-level capacity, concept-level capacity, and compression ratio R (tokens per concept). This helps decide how big each part should be to get the best performance for the compute you have.
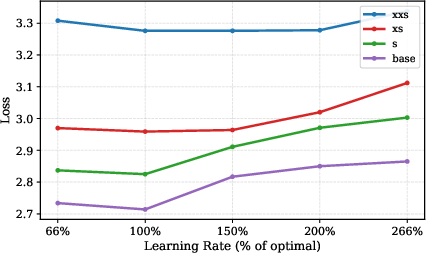
- Decoupled μP (Maximal Update Parametrization): Training very different parts together can be unstable. The authors adapt μP so each part has its own learning rate that scales with its width. In simple terms, wider parts get smaller learning rates. This makes training smoother and lets good settings transfer from small test models to bigger ones without re-tuning everything.
- Training objective: The model is trained both to predict the next token and to keep the overall compression close to the target R.
Main Findings and Why They Matter
Several important results:
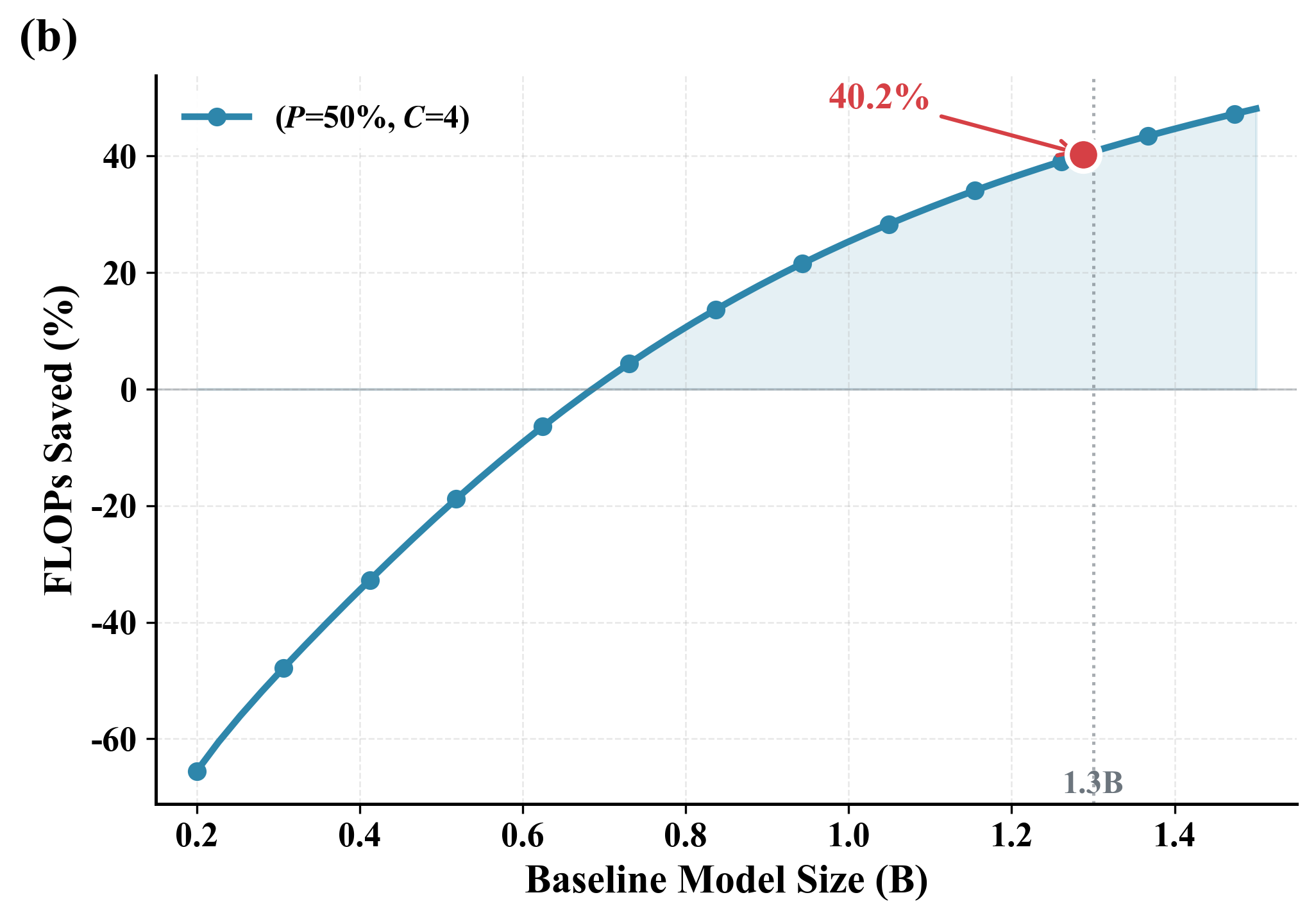
- Better reasoning under the same compute: With R=4 (about 4 tokens per concept), DLCM moves roughly one-third of inference compute into the concept reasoning backbone and improves accuracy by +2.69% on average across 12 zero-shot benchmarks, compared to a standard LLM using the same total FLOPs. Gains are biggest on reasoning-heavy tasks.
- Compute savings: DLCM reduces FLOPs by up to 34% while becoming better at reasoning, thanks to operating on fewer, smarter units (concepts) and cutting attention costs.
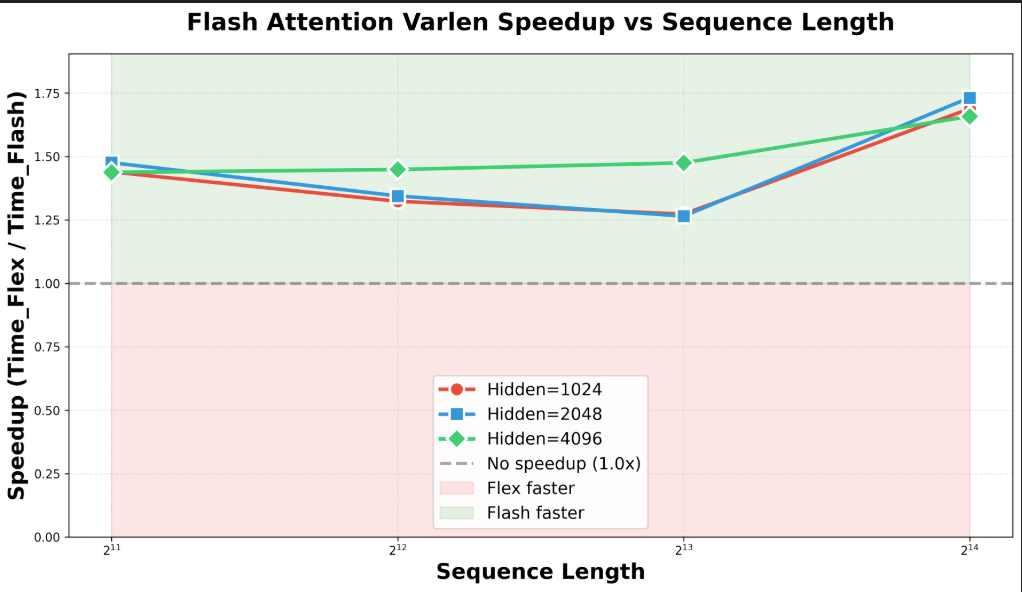
- Efficient attention implementation: Their concept-replication trick lets them use fast “Flash Attention” kernels. It’s 1.26–1.73× faster than a more flexible but slower approach, and the speed advantage grows with longer sequences. This means DLCM isn’t just clever conceptually—it’s practical on real hardware.
- Stable training across scales: The decoupled μP tuning lets hyperparameters transfer from small models to bigger ones with little extra work, making scaling up more reliable.
Implications and Potential Impact
This research shows a practical path to make LLMs think more like people: spend less time on easy stuff and more time on the parts where ideas change. The potential impacts include:
- Better reasoning quality without higher cost, especially on math, code, and complex reading comprehension
- Faster and cheaper inference by compressing sequences into concepts
- Models that adapt their “chunk size” to the content, which could help across languages and domains with different information density
- Clearer guidelines for building and scaling hybrid models (tokens + concepts) under fixed compute budgets
In short, DLCM is a promising step toward LLMs that are both smart and efficient: they learn what to think about (dynamic concepts) and how to think (deep reasoning in a compressed space), then use that thinking to produce better token-level predictions.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper proposes DLCM and reports promising results, but several concrete issues remain unclear or unexplored:
- Boundary detection validity: No quantitative evaluation of learned concept boundaries (e.g., alignment with clauses/phrases, code blocks) or boundary quality metrics across domains and languages.
- Locality of the boundary signal: The detector uses only adjacent-token cosine dissimilarity; the benefit of longer-context features, multi-head detectors, or structured predictors is not assessed.
- Thresholding and calibration: Inference uses a fixed 0.5 threshold; sensitivity to this choice, calibration under domain shift, and procedures for setting thresholds are not studied.
- Training discreteness vs. learning signal: Segmentation is decoupled from the LM loss and uses discrete sampling without a differentiable surrogate; the impact on gradient quality, variance, and convergence is unquantified (e.g., vs. straight-through or Gumbel-Softmax).
- Degenerate segmentations: Conditions under which the model avoids trivial solutions (e.g., every token is its own concept or ultra-long concepts) are not analyzed; no ablations on regularization strength or failure modes.
- Global load balancing side effects: Batch-level compression control may produce per-sequence extremes; effects on fairness, stability, and per-sample latency/quality are not reported.
- Minimum/maximum segment lengths: Constraints on concept size (e.g., to prevent very short/long segments) are not specified or evaluated.
- Concept pooling choice: Mean pooling may discard order/structure; alternatives (attention pooling, gated pooling, convolutional pooling) and their impact on tasks (especially code/math) are not explored.
- Concept smoothing details: The smoothing module is not specified; risk of information leakage across causal boundaries and its effect on token-level causality are not examined.
- Causality guarantees under replication: Formal verification that concept replication preserves the intended causal mask and prevents future-concept leakage is missing.
- Memory overhead of concept replication: K/V replication inflates cache from length M to L; no quantification of memory footprint, especially for long-context (32–128k) inference.
- Throughput/latency in autoregressive decoding: Online segmentation and K/V updates may introduce jitter; end-to-end latency and token/sec impacts in streaming generation are not measured.
- Attention behavior with replicated K/V: Repeating identical keys/values within a segment may reduce attention diversity; analysis of attention entropy, gradient flow, or training stability is absent.
- Capacity allocation strategy: How to optimally split depth/width across encoder, concept backbone, and decoder under fixed FLOPs is not empirically mapped (beyond a high-level claim).
- Compression-aware scaling law: The explicit form of is not provided; no systematic empirical validation across scales, datasets, and a sweep of compression ratios.
- μP for heterogeneous widths: Theoretical justification for independent learning-rate/variance scaling across coupled modules (encoder/decoder/backbone with cross-attention) is limited; robustness across different and model sizes is not established.
- Changing compression at fine-tune/inference time: Behavior when is altered post-pretraining (e.g., to meet latency budgets) is unknown.
- Generalization beyond English/Chinese: Boundary learning and performance on typologically diverse languages (e.g., morphologically rich or non-segmented scripts) are not evaluated.
- Domain sensitivity of segmentation: No per-domain analysis of learned boundaries (web vs. code vs. math), and how domain shifts impact segmentation and performance.
- Long-context and retrieval settings: Effectiveness and efficiency of DLCM under retrieval-augmented contexts or very long inputs are not investigated.
- Robustness and safety: Impact on hallucination, calibration, and adversarial robustness is not discussed; whether concept segmentation mitigates or exacerbates failure modes is unknown.
- Benchmark transparency: The “+2.69% over 12 zero-shot benchmarks” lacks task list, baselines, and per-task breakdowns; statistical significance and variance across seeds are not reported.
- Comparative baselines: No head-to-head comparisons with adaptive compute baselines (e.g., MoE, ACT/halting, skip layers) or chunked/hierarchical architectures under matched FLOPs/params.
- Ablations on segmentation: Missing comparisons to fixed sentence/paragraph chunking, random chunking, or oracle boundaries to isolate gains from learned boundaries.
- Training efficiency and scalability: Wall-clock training cost, memory usage, and distributed overhead of the global parser (AllReduce stats) relative to standard LLMs are not quantified.
- Reproducibility: Full hyperparameters, training schedules, and code for boundary detection, smoothing, and cross-attention masks are not provided; sensitivity to seeds and implementation details is unknown.
- Interpretability: Whether learned concepts are human-interpretable and how they evolve across layers/tasks is not analyzed.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that can be built now by leveraging DLCM’s dynamic segmentation, concept-level reasoning, compression-aware scaling, decoupled μP hyperparameter transfer, and cross-attention optimization.
- Cloud LLM cost and latency reduction
- Sectors: software, cloud/energy
- What: Train and serve DLCM variants (e.g., R≈4) to reallocate ~30% of inference FLOPs from tokens to a higher-capacity concept backbone; realize 1.26–1.73× kernel-level speedups via Flash Attention VarLen + concept replication; gain ~+2.7% zero-shot accuracy at matched FLOPs.
- Tools/products/workflows: “Concept-mode” inference profile in serving stacks (vLLM/TensorRT-LLM), KV-cache aware concept replication, autoscaling tuned to compression ratio R.
- Assumptions/dependencies: Requires training DLCM from scratch or substantial finetuning; serving stack must support FlashAttention VarLen; concept replication increases KV memory footprint; operational monitoring of global compression statistics.
- Long-document analytics (summarization, Q&A, compliance review)
- Sectors: legal, finance, insurance, enterprise search
- What: Use dynamic segmentation to form semantically coherent concepts for long-context reasoning at lower cost; provide “concept boundary views” in UIs for faster navigation and audits.
- Tools/products/workflows: Concept-aware reader (concept overlays on documents), RAG pipelines that index concept embeddings rather than fixed-length chunks.
- Assumptions/dependencies: Domain adaptation for boundary detector; mapping concept spans to original text must be preserved; evaluation for compliance workflows.
- Concept-aware retrieval-augmented generation (RAG)
- Sectors: enterprise knowledge management, devops
- What: Replace fixed-size chunking with learned concept segments to build vector indices at the conceptual granularity; improve retrieval precision and reduce redundancy.
- Tools/products/workflows: Concept indexer and reranker (stores concept embeddings), retrieval nodes aligned to dynamic boundaries, concept-level cache reuse across turns.
- Assumptions/dependencies: Stable segmentation across corpora; requires instrumentation to persist and query concept spans and offsets.
- Faster, cheaper coding assistants
- Sectors: software engineering
- What: Exploit non-uniform information density in code (e.g., boilerplate vs. logic transitions) to speed inference and improve reasoning over functions/blocks with DLCM.
- Tools/products/workflows: IDE plugins with concept-level prefill, server-side DLCM for completion and repair, diff-aware segmentation.
- Assumptions/dependencies: Pretraining on code-heavy corpora; correctness/latency SLAs must be validated.
- Customer support and sales chatbots with adaptive compute
- Sectors: CX/CRM
- What: Reduce per-session cost and tail latencies by concentrating compute on high-entropy turns (new intents, task pivots).
- Tools/products/workflows: “Adaptive compute engine” that tunes global compression R by traffic profile; boundary-triggered escalation or tool-use.
- Assumptions/dependencies: Needs real-time monitoring of boundary rates; careful guardrails for safety and consistency.
- On-device and edge assistants
- Sectors: mobile, IoT
- What: Deploy smaller DLCM variants to deliver offline summarization, note cleanup, and smart keyboard suggestions with lower power draw.
- Tools/products/workflows: Mobile runtime support for FlashAttention-like kernels (or vendor NPU analogues), concept-level KV cache management.
- Assumptions/dependencies: Device acceleration support; concept replication may stress memory; privacy and safety constraints for local inference.
- Meeting and call intelligence
- Sectors: productivity, enterprise SaaS
- What: DLCM-driven segmentation to detect topic shifts and action-item boundaries; cheaper real-time transcription-to-summary pipelines.
- Tools/products/workflows: Live “concept boundary” markers, concept-conditioned summarization passes, post-call concept index.
- Assumptions/dependencies: Integration with ASR; synchronization of concept spans with timestamps.
- Training efficiency and hyperparameter transfer
- Sectors: academia, AI labs
- What: Use decoupled μP to stabilize heterogeneous modules and transfer learning rates/initialization across widths and compression regimes with minimal retuning.
- Tools/products/workflows: μP-backed training recipes, proxy-to-target transfer sweeps, automated “width-aware” LR schedulers.
- Assumptions/dependencies: Adherence to μP initialization and optimizer scaling; proxies must match module heterogeneity (token vs. concept widths).
- Compute planning with compression-aware scaling laws
- Sectors: AI platform engineering, procurement
- What: Use L(N, D, R, P) to choose parameter/data allocation and backbone sizing given fixed FLOPs and target compression ratios.
- Tools/products/workflows: Scaling-law calculator (spreadsheet/notebook), internal RFCs for model family roadmaps and budget trades.
- Assumptions/dependencies: Extrapolation from internal pilots; calibration to domain/task distributions.
- Interpretability and content analysis via learned boundaries
- Sectors: policy, safety, UX research
- What: Visualize semantic boundaries to identify where the model “spends” compute and to audit failure points at concept transitions.
- Tools/products/workflows: Boundary heatmaps, concept saliency overlays, “reasoning hotspots” diagnostics.
- Assumptions/dependencies: Boundaries are learned, not linguistic; interpretability must be validated per domain and language.
- Serving-stack optimization
- Sectors: inference infrastructure
- What: Adopt concept replication and VarLen Flash kernels to remove irregular attention masks; realize immediate speedups independent of hidden size.
- Tools/products/workflows: PRs/patches to inference frameworks, KV layout tuned for concept-level locality, prefill/decoding pipeline changes.
- Assumptions/dependencies: Kernel availability and compatibility; increased memory traffic for replicated K/V.
- Budget-aware product controls
- Sectors: SaaS, API providers
- What: Expose R (average tokens per concept) as a service-level knob to trade accuracy vs. cost per request; enforce global load balancing during peak hours.
- Tools/products/workflows: “Compression governor” tied to quotas, SLO dashboards for F_global vs. target 1/R, A/B infra.
- Assumptions/dependencies: User education on trade-offs; guard against QoS regressions on boundary-heavy inputs.
Long-Term Applications
The following opportunities require additional research, scaling, or ecosystem development before broad deployment.
- Healthcare documentation and decision support
- Sectors: healthcare
- What: Concept-level summarization of EHR notes and clinical correspondence with lower compute; boundary-triggered reasoning on differentials and orders.
- Potential tools/products/workflows: EHR-integrated concept summarizers, topic-shift detection for handoffs, audit logs at concept granularity.
- Assumptions/dependencies: Clinical validation, bias/safety audits, regulatory approval (FDA/CE), multilingual/clinical-domain segmentation robustness.
- High-stakes financial analysis and real-time risk
- Sectors: finance
- What: Low-latency, concept-focused analysis of filings, transcripts, and news streams; compute concentration on regime shifts.
- Potential tools/products/workflows: Concept-aware market monitors, alerting on boundary-detected pivots, compliance-ready reasoning logs.
- Assumptions/dependencies: Strict correctness/latency SLAs; governance and model risk management.
- Robotics and embedded planning
- Sectors: robotics, autonomous systems
- What: Use concept-level latent plans (macro-actions) for language-conditioned control under tight compute budgets onboard.
- Potential tools/products/workflows: Concept planners interfacing with motion stacks; boundary-triggered replanning.
- Assumptions/dependencies: Multimodal grounding and safety; real-time guarantees; co-training with control data.
- Multimodal DLCM (text–audio–video)
- Sectors: media, surveillance, education
- What: Extend dynamic segmentation to frames/phonemes/visual events; reason over compressed multimodal concepts.
- Potential tools/products/workflows: Topic-aware video summarizers, lecture indexing by conceptual units, event boundary analytics.
- Assumptions/dependencies: Multimodal encoders/decoders; cross-modal boundary alignment; large-scale training.
- Concept-level RAG and memory for agents
- Sectors: agent platforms
- What: Agent memory addressed at concept granularity, enabling durable, low-cost retrieval and reuse across sessions.
- Potential tools/products/workflows: Concept memory stores, boundary-aware tool routing, long-horizon planning via concept chains.
- Assumptions/dependencies: Robust mapping from concepts to actions/tools; memory safety and privacy controls.
- Hardware–software co-design for adaptive attention
- Sectors: semiconductor, systems
- What: Architectures that natively cache/reuse concept K/V blocks and accelerate replication/smoothing without large memory penalties.
- Potential tools/products/workflows: Concept-cache primitives, R-aware schedulers, NIC/GPU pipelines tuned for concept locality.
- Assumptions/dependencies: Vendor adoption; standardized kernels; workload characterization.
- Governance and sustainability standards
- Sectors: policy, sustainability
- What: Compression-aware reporting of energy per token/concept; procurement standards favoring adaptive computation for AI services.
- Potential tools/products/workflows: Audit templates for L(N, D, R, P) disclosures, carbon accounting tied to effective compression.
- Assumptions/dependencies: Third-party validation; sector-wide benchmarks; regulatory uptake.
- Curriculum/data design based on information density
- Sectors: edtech, pretraining pipelines
- What: Use learned boundary statistics to remix corpora (upsample high-entropy segments, de-emphasize redundant spans) to improve data efficiency.
- Potential tools/products/workflows: “Info-density” data curation toolchains; boundary-informed sampling schedules.
- Assumptions/dependencies: Stable correlation between boundary rates and learning utility; avoidance of bias amplification.
- Knowledge distillation and interoperability
- Sectors: model tooling
- What: Distill between token-uniform and DLCM models; export/import concept-level traces to standard LLMs for interpretability or cost control.
- Potential tools/products/workflows: Teacher–student pipelines with concept supervision; adapters translating between token and concept spaces.
- Assumptions/dependencies: Effective supervision signals; preservation of reasoning gains during distillation.
- Multi-agent communication protocols at the concept level
- Sectors: distributed AI
- What: Agents exchange compressed conceptual messages instead of long token streams, improving bandwidth and coordination.
- Potential tools/products/workflows: Concept-message schemas, boundary-triggered negotiation protocols.
- Assumptions/dependencies: Shared semantic spaces; robustness to concept drift; security and auditability.
Common assumptions and dependencies across applications
- Retraining or substantial finetuning is needed; DLCM is not a drop-in architectural swap for existing LLM weights.
- The quality and stability of boundary detection depend on diverse training data and calibrated thresholds; domain-specific finetuning may be required.
- Concept replication improves speed but increases K/V memory; extremely long contexts may need memory engineering (paging, recomputation).
- Compression ratio R introduces explicit accuracy–cost trade-offs; production systems must monitor and govern global boundary rates (Global Parser).
- Safety-critical deployments require extensive validation, interpretability studies at concept boundaries, and compliance with sector regulations.
Glossary
- AdamW ε parameter: A small constant in the AdamW optimizer to improve numerical stability; here, scaled with module width in heterogeneous architectures. "The AdamW parameter for each layer is scaled by , matching the respective component width."
- Adaptive Compression via Global Load Balancing: A globally regularized mechanism to maintain a target compression ratio while allowing local segmentation variability. "Adaptive Compression via Global Load Balancing"
- AllReduce: A distributed operation that aggregates values (e.g., statistics) across multiple processes or devices. "These statistics are synchronized across ranks via AllReduce."
- Autoregressive: A modeling paradigm where each token is predicted conditioned on previously generated tokens. "autoregressive prediction"
- Bernoulli: A binary-valued probability distribution used to sample discrete boundary decisions. "b_t \sim \text{Bernoulli}(p_t{\text{sharp})"
- Causal cross-attention: An attention mechanism that enforces temporal causality when tokens attend to concept representations. "via a causal cross-attention mechanism."
- Causal Mask: An attention mask that prevents positions from attending to future (unseen) tokens or concepts. "Causal Mask"
- Chain-of-Thought prompting: A technique that elicits explicit intermediate reasoning steps by generating many tokens. "Chain-of-Thought prompting"
- COCONUT framework: A latent reasoning approach that iterates directly on hidden states without generating intermediate tokens. "In the COCONUT framework, the model's hidden state from one reasoning step feeds directly into subsequent steps without generating intermediate tokens"
- Concept replication: Replicating concept key/value features to align with token positions for efficient, regular attention kernels. "we adopt a concept replication strategy"
- Concept Smoothing: A lightweight module that mitigates discretization artifacts by integrating information from adjacent concepts. "Concept Smoothing"
- Cross-entropy: The standard loss function used for next-token prediction in LLMs. "cross-entropy on output tokens"
- Dynamic Segmentation: A learned process that detects semantic boundaries and pools tokens into variable-length concepts. "Dynamic Segmentation identifies semantic boundaries and pools tokens into concepts"
- Flash Attention Varlen: Highly optimized attention kernels for variable-length sequences that enable faster causal attention. "Flash Attention Varlen with concept replication significantly outperforms Flex Attention."
- Flex Attention: An attention implementation that supports irregular masks but can incur overhead from dynamic masking and memory access. "Implementing this directly with Flex Attention incurs significant overhead"
- FLOPs: Floating-point operations, a measure of computational cost or budget in model training/inference. "under equal-FLOPs constraints"
- Global Parser: The globally regularized segmentation mechanism that enforces a target compression rate while allowing content-adaptive chunking. "We refer to this globally regularized segmentation mechanism as the Global Parser"
- Grouped Query Attention (GQA): An attention variant that groups queries; used here as an analogy for concept replication. "Analogous to Grouped Query Attention (GQA)"
- H-NET: A hierarchical model with learned boundary detection and adaptive chunking demonstrating compression and compute savings. "H-NET~\cite{hwang2025dynamicchunkingendtoendhierarchical} directly addresses adaptive allocation through learned boundary detection."
- K/V cache: The stored keys and values used across attention layers; increasing their size raises memory footprint. "for the K/V cache"
- Latent reasoning: Performing inference in continuous hidden spaces instead of generating explicit intermediate tokens. "Latent reasoning frameworks perform reasoning entirely within continuous hidden state spaces rather than through explicit token generation"
- Load-balancing loss: An auxiliary objective that aligns the global boundary rate with the target compression ratio. "load-balancing loss"
- Maximal Update Parametrization (μP): A parameterization scheme that scales initialization and learning rates with width to stabilize training across scales. "the Maximal Update Parametrization (P)"
- Mean pooling: Averaging token representations within a segment to form a single concept embedding. "via mean pooling"
- Mixture of Experts (MoE): A conditional computation architecture that routes tokens to a subset of expert networks. "Mixture of Experts (MoE) models"
- Next Token Prediction (NTP): The standard autoregressive objective of predicting the next token given previous context. "Next Token Prediction (NTP) baselines"
- Query-key space: The projection space used to compute similarity/dissimilarity for boundary detection. "project each token into a query-key space"
- repeat_interleave: An operation that repeats elements along a dimension, used to replicate concepts to token length. "repeat_interleave"
- RMSNorm: Root Mean Square Layer Normalization applied to stabilize attention across heterogeneous representations. "we apply RMSNorm to queries and keys before attention:"
- Scaling law L(N,D,R,P): A compression-aware scaling relation disentangling parameters, data, compression ratio, and backbone allocation. "We derive a scaling law "
- SONAR: A multilingual semantic embedding space used by prior concept-level models for sentence representations. "SONAR, supporting 200 languages"
- Superposition: The overlapping encoding of multiple potential reasoning paths within continuous representations. "encode multiple potential reasoning paths in superposition"
- Temperature α: A parameter used to sharpen probabilities during training-time sampling of boundaries. "We sharpen probabilities by temperature "
- Universal Transformer: A transformer variant with recurrent depth and learned halting for adaptive computation per position. "The Universal Transformer~\cite{dehghani2018universal} introduced recurrence in depth"
- Variable Length (VarLen): A training/attention approach that handles sequences of varying lengths efficiently. "Variable Length (VarLen) approach from FlashAttention"
- Zero-shot: Evaluation or transfer without task-specific training on the target domain. "zero-shot benchmarks"
Collections
Sign up for free to add this paper to one or more collections.

