- The paper introduces a leader–follower teleoperation framework using static and wrist-mounted RGB-D sensors for real-time, semantically filtered 3D reconstruction.
- The paper evaluates four visualization modalities, showing that the augmented point cloud with high-resolution RGB (PC+RGB) significantly lowers task completion time and subjective workload.
- The paper’s experimental results demonstrate that combining explicit 3D structure with local foveated detail optimizes telemanipulation performance in XR environments.
Multi-View 3D Telepresence for XR Robot Teleoperation: A Technical Analysis
System Architecture and Visualization Pipeline
The presented system establishes a leader–follower teleoperation architecture using dual Franka Emika Panda arms, with the leader arm operated via direct kinesthetic teaching. The manipulation workspace is observed by three extrinsically calibrated static RGB-D cameras and a wrist-mounted RGB-D camera, all providing synchronized and semantically filtered data for real-time 3D reconstruction (Figure 1).

Figure 1: Leader–follower teleoperation system integrating static and wrist-mounted RGB-D sensors for multi-view perception, with VR-based visualization.
Point cloud generation fuses global geometric information by back-projecting depth data from the three static cameras after YOLOv11-based masking of the robot, gripper, table, and other scene clutter, achieving a ~75k point cloud at 10 Hz. This cloud is further downsampled and cleaned for transmission and in situ GPU rendering on the standalone Meta Quest 3—overcoming previous constraints on point density encountered in legacy systems. The pipeline also incorporates a high-resolution wrist-mounted RGB stream, rigidly registered in VR space, enabling localized semantic detail unavailable in the fused point cloud—directly addressing edge cases in contact-rich manipulation.
Visualization Modalities
Four visualization schemes were formally compared, each emphasizing differential access to spatial and local cues (Figure 2):
- RGBs: Four rectified RGB streams (left, right, top, wrist) are displayed as virtual monitors. This provides high spatial frequency information but relies exclusively on monocular cues and user integration across viewpoints.
- PC: Only the semantically filtered, fused point cloud of the manipulation workspace is rendered. The explicit 3D structure enhances metric depth perception but lacks fine local detail.
- PC+RGB: The fused point cloud is augmented by a geometrically aligned, high-resolution wrist-mounted RGB inset, yielding combined global spatial mapping and foveated detail.
- OT (OpenTeleVision): Ego-centric stereo RGB is streamed from a head-mounted camera on the follower robot, providing immersive viewpoint correspondence but lacking explicit global scene structure and direct proprioceptive feedback.

Figure 2: Visualization modalities tested: (a) RGBs, (b) fused PC, (c) PC+RGB, (d) OT (stereoscopic ego-view).
Experimental Design
A within-subjects user study (n=31, STEM-oriented, VR-novice) assessed interface effects on teleoperated manipulation. Participants performed three functionally differentiated tasks: sequential cup insertion with occlusions, T-shaped stacking/assembly, and precision wire-loop placement (Figure 3). Each participant completed four repetitions of each task per visualization modality, randomizing task/modality order.

Figure 3: Representative teleoperated manipulation tasks: (a) cup insertions, (b) T-assembling, (c) wire-loop placement.
Objective metrics included task completion time and binary success. Subjective assessments captured perceived NASA-TLX workload (mental, physical, temporal demand, effort, frustration, performance), VR usability (effectiveness, efficiency, satisfaction), and post hoc preference rankings.
Results
Workload and Usability
Statistical analysis (Friedman tests with Holm correction) demonstrates that point cloud-based modalities induce lower subjective workload across all NASA-TLX dimensions compared to RGBs and OT, with PC+RGB eliciting the lowest effort, frustration, and temporal demand scores (Figure 4).
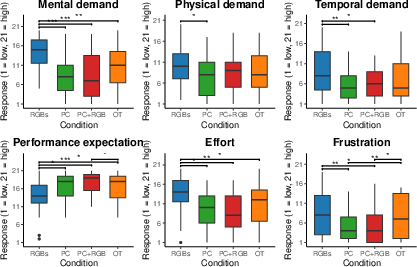
Figure 4: NASA-TLX workload ratings across visualization conditions; lower is better. Significant differences between all pairs are denoted.
Regarding VR usability (effectiveness, efficiency, satisfaction), PC and PC+RGB significantly exceeded RGBs and OT in both efficiency and satisfaction, albeit effectiveness differences were non-significant (Figure 5). Participants overwhelmingly ranked PC+RGB as their preferred modality, followed by PC; RGBs and OT were less favored (Figure 6).
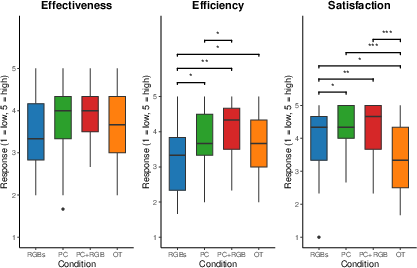
Figure 5: Usability ratings for each modality; boxplots highlight higher satisfaction and efficiency for point cloud-based views.
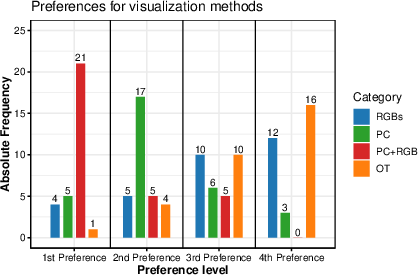
Figure 6: Distribution of subjective modality preferences, indicating strong operator preference for PC+RGB.
PC+RGB yielded the fastest task completion times and highest success rates across all tasks (Figure 7). Notably, even unaugmented PC outperformed RGBs and OT in both metrics. Statistical comparisons confirmed significant advantages (p<0.001) for the augmented point cloud over alternatives, emphasizing the role of explicit 3D structure and foveated detail.
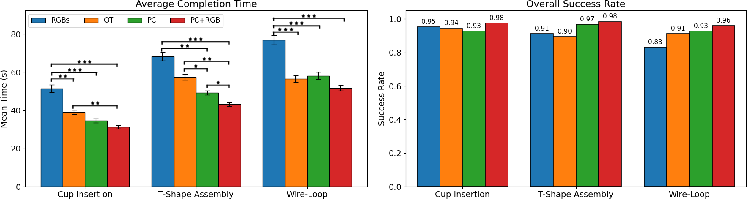
Figure 7: Manipulation performance: Left—mean completion time; Right—success rate per condition. PC+RGB leads, followed by PC.
Mechanisms and Implications
The observed superiority of point cloud-based conditions, especially PC+RGB, can be attributed to two primary mechanisms:
- Visuomotor co-location: Rendering the manipulated workspace and kinematically congruent leader arm in VR establishes direct correspondence between operator action and visual feedback, optimizing sensorimotor integration critical for teleoperation.
- Explicit 3D structure with local foveation: The fused global scene supports metric depth judgements and collision avoidance, while the wrist-mounted RGB feed resolves geometric ambiguity when fine-grained alignment or contact is required.
Conversely, RGBs and OT fail to provide one or both of these affordances, resulting in increased cognitive integration load, visual-proprioceptive conflict, and elevated task difficulty. The findings empirically corroborate the hypothesis that hybrid visualizations integrating depth representations with selective high-resolution patches are optimal for telemanipulation.
Limitations and Future Directions
Constraints stem from camera quality (RealSense RGB-D), YOLOv11 scene segmentation, and fixed point budgets for rendering on the headset. Enhancement may be achievable via denser/tof depth sensors, radiance field fusion, or learning-based reconstruction pipelines. Generalizability is limited by the homogeneous, VR-novice participant pool and the specific manipulation tasks employed; subsequent work should extend to industrial practitioners, longer operational sessions, and adaptive, context-aware visualization (e.g., bandwidth allocation, automatic foveation).
Conclusion
This work implements and systematically evaluates a GPU-accelerated, multi-view 3D telepresence system for XR robot teleoperation, integrating fused point cloud rendering and dynamic high-resolution RGB augmentation. Empirical results unambiguously support the deployment of hybrid point cloud + foveated detail interfaces for advanced manipulation. These findings are directly actionable for the design of next-generation XR teleoperation frameworks, suggesting that systems should prioritize real-time, semantically structured 3D visualizations with task-sensitive high-resolution detail for optimum operator performance and usability.