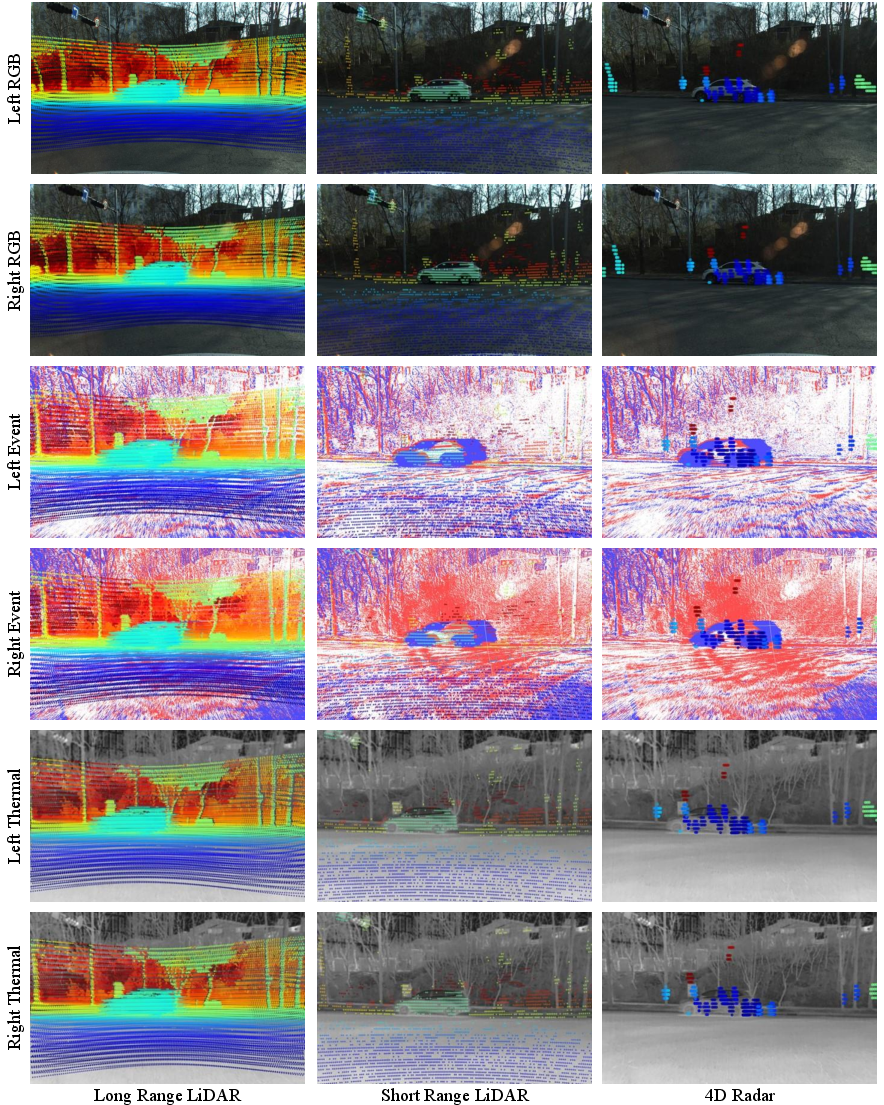
- The paper introduces DSERT-RoLL, a comprehensive dataset integrating stereo event, RGB, thermal cameras, 4D radar, and dual LiDAR to benchmark robust 3D detection in varied environmental conditions.
- It details a confidence-gated fusion architecture that adaptively merges multimodal data, achieving AP over 90 in clear weather and sustaining performance in adverse conditions.
- Results underscore sensor redundancy and calibration robustness, paving the way for reliable autonomous driving in extreme weather and lighting scenarios.
DSERT-RoLL: Robust Multi-Modal Perception for Diverse Driving Conditions
Motivation and Background
Autonomous driving demands highly robust perception systems capable of consistent operation across diverse and adverse environments. While extensive datasets exist for RGB and LiDAR modalities, current research confronts limitations in extreme conditions such as heavy rain, snow, fog, low illumination, and high dynamic range. These environments frequently degrade the reliability of conventional sensors, resulting in incomplete coverage or corrupted data, severely impacting detection performance.
Recent advances in emerging sensors—including event cameras, thermal imagers, and 4D Radar—offer unique physical signal properties that are promising for overcoming these environmental failures. However, systematic, direct comparison and fusion of these modalities with established sensors have remained largely unexplored due to the lack of a comprehensive, unified dataset and fair benchmarks.
DSERT-RoLL Dataset Design
The DSERT-RoLL dataset (“Driving with Stereo Event-RGB-Thermal cameras, 4D Radar, and Dual LiDAR”) is constructed to fill this critical gap. It incorporates:
- Stereo-based Event, RGB, and Thermal Cameras: All three modalities with stereo pairs, providing robust complementary visual information.
- 4D mmWave Radar: Provides range, azimuth, elevation, and Doppler measurements, remaining robust through strong precipitation and severe visual degradation.
- Dual LiDAR Systems: Short- and long-range LiDARs combined for high-density geometric coverage and distant object detection.
- Comprehensive Environmental Coverage: Data is collected in a wide range of weather (clear, fog, light/heavy rain and snow) and lighting (normal, low-light, overexposed, HDR) scenarios for urban, suburban, and highway driving scenes.
- Synchronized, High-Fidelity Annotations: High-quality 3D and 2D bounding box annotations, per-frame object tracking IDs, and ego vehicle odometry.
Through its structure, DSERT-RoLL enables direct, fair modality comparison and multi-modal fusion experiments, facilitating the analysis of individual sensor strengths, weaknesses, and complementary behaviors.

Figure 1: Complementary strengths of sensor modalities—LiDAR excels in clear conditions, 4D radar dominates in adverse weather, RGB in normal daylight, event cameras in dynamic motion or HDR, and thermal images in low-light or night.

Figure 2: Training and test splits are balanced in terms of weather, lighting, and object class distribution, ensuring benchmarking reliability.
Multi-Modal 3D Detection Framework
DSERT-RoLL enables principled fusion research, and the paper proposes a strong multi-modal fusion architecture for robust 3D object detection:
- Voxel-Based BEV Backbone: LiDAR and 4D Radar point clouds are voxelized and processed with a shared 3D backbone. BEV (Bird’s Eye View) features are generated and fused, exploiting geometric complementarity.
- Camera-Informed Voxel Features: RGB, event, and thermal images are processed by modality-specific 2D backbones, then projected into the 3D grid using calibrated transformations via a voxel-centric, deformable sampling scheme.
- Confidence-Gated Fusion: Voxel features from all modalities are adaptively reweighted based on data-driven confidence estimations, ensuring down-weighting of unreliable or noisy modality data under adverse conditions.
- Two-Stage Bounding Box Refinement: Initial proposals from range sensors are refined using fused camera-augmented features, increasing robustness to modality failures.
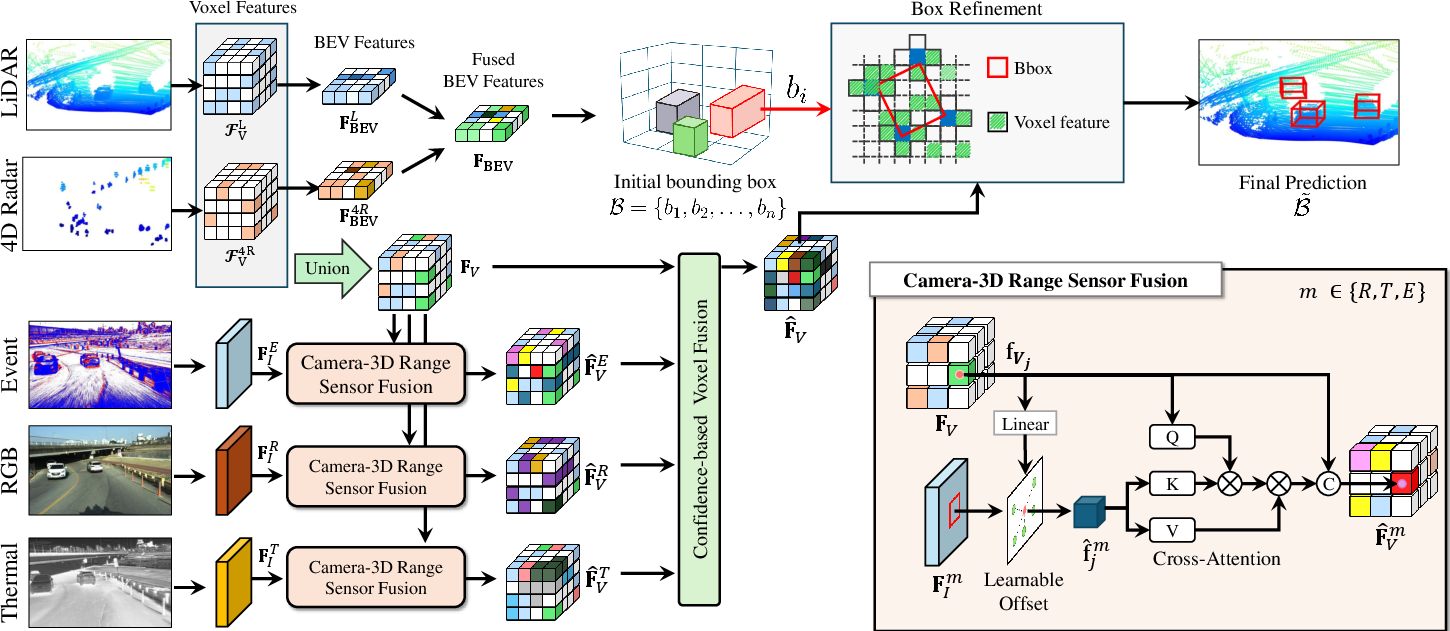
Figure 3: Overview of the fusion pipeline: LiDAR/4D Radar features are combined for initial proposals; image features (RGB, thermal, event) are projected into 3D space and fused; camera and range data are adaptively combined for final prediction.
Sensor Calibration and Annotation
Precise cross-modal calibration is critical. The methodology employs:
Benchmarking and Results
3D Object Detection
Detection performance is evaluated on a comprehensive protocol, with results demonstrating:
- LiDAR Vulnerability: LiDAR achieves high AP in clear conditions (82.90+) but degrades substantially in heavy fog (down to 54.14 AP).
- 4D Radar Resilience: 4D Radar shows consistent geometric reliability in adverse weather, compensating for LiDAR failures.
- Cameras: RGB dramatically degrades under night or HDR; event cameras excel in rapid motion/HDR; thermal excels in low-light.
- Multi-Modal Synergy: Progressive fusion (R+L, 4R+L, R+4R+L, R+E+T+4R+L) yields monotonically increasing AP, with full fusion (all five: R+E+T+4R+L) reaching the highest robustness in all conditions (AP exceeding 90 in clear and >70 in adverse weather), clearly exceeding all strong baselines.
Bold result: Integrating event and thermal modalities alongside conventional sensors provides non-trivial boosts in robustness and accuracy—these gains are especially marked in low-light, fog, and heavy precipitation.
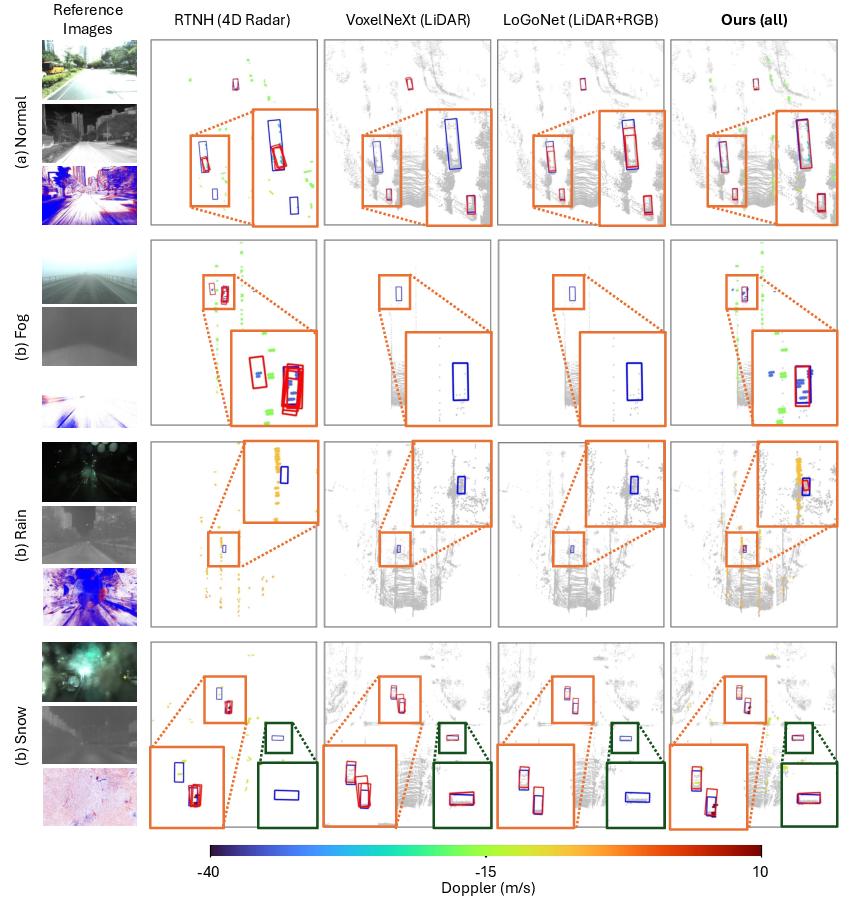
Figure 6: Qualitative comparison in BEV. The full fusion model outperforms Radar- and LiDAR-only models, maintaining object coverage and size precision in difficult settings.
2D Detection
The dataset supports multi-modal 2D detection with similarly strong findings—multi-modal architectures (e.g., GM-DETR on R+E+T) substantially outperform single-modality models under adverse lighting and weather.
Practical and Theoretical Implications
- Sensor Failure Redundancy: Direct evidence that complementary sensors cover one another’s failure modes, enabling reliable safety-critical perception in real-world conditions.
- Fusion Architecture Generality: The proposed confidence-based fusion model is extendable to any sensor set, supporting rapid prototyping for new platforms.
- Calibration Robustness: Evaluation reveals that detection performance is robust to moderate calibration errors (e.g., 5 cm/5° perturbations cause <2 AP drop), pointing to strong practical deployability.
- Future Extensions: DSERT-RoLL provides a foundation for domain adaptation, robust domain generalization, sensor selection, and cost-performance analysis for automotive ADAS and robotic platforms. It enables new research directions in self-supervised, adaptive, and redundancy-aware perception architectures.
Conclusion
DSERT-RoLL constitutes a comprehensive, rigorously benchmarked multi-modal perception dataset designed for the direct evaluation and development of robust 3D and 2D object detection systems under diverse and challenging driving conditions. Its design enables detailed ablation and fusion research, and the reported results demonstrate that the adaptive fusion of event, thermal, radar, LiDAR, and RGB systems yields superior resilience compared to prior approaches. This work will accelerate advances in robust all-weather, all-lighting scene understanding for real-world autonomous and assisted driving (2604.03685).