- The paper presents MASC-Pose, which integrates adaptive multi-scale temporal modeling with skeleton-constrained spatial graphs to improve accuracy and reduce computational cost.
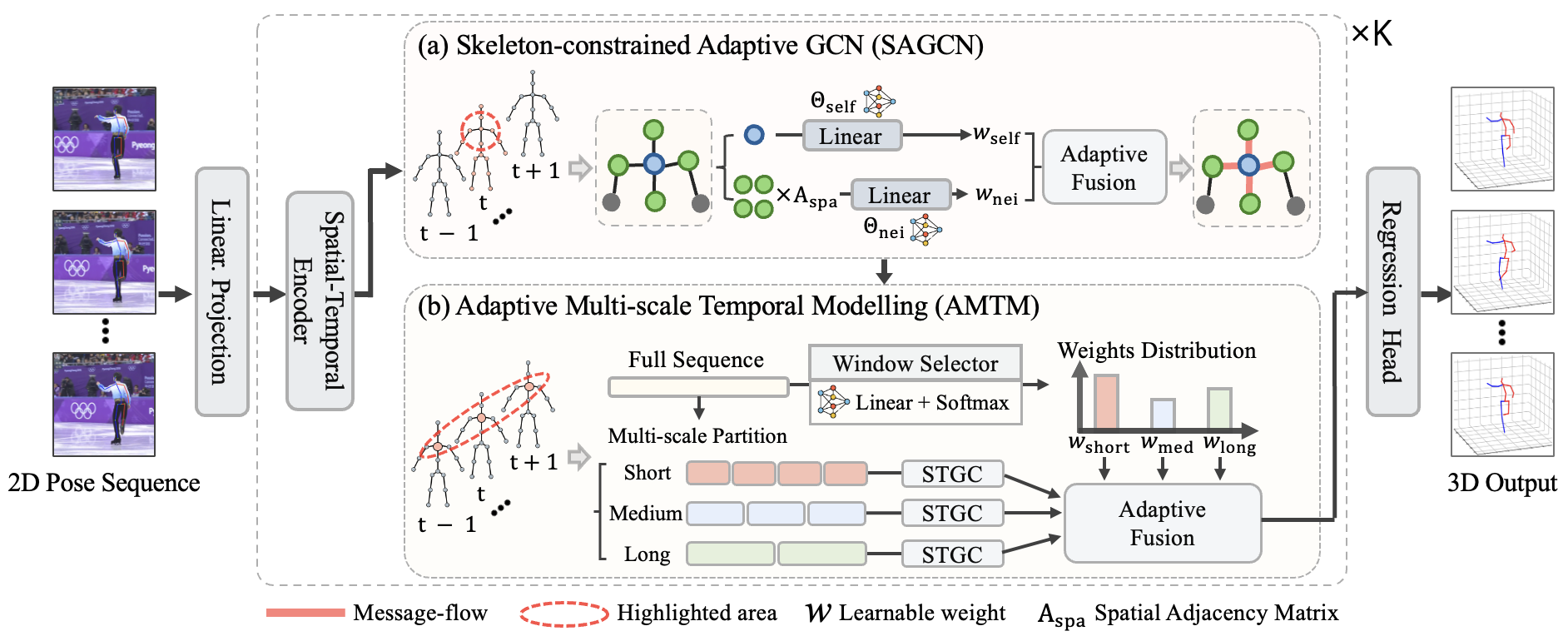
- It leverages an AMTM module for capturing variable temporal dependencies and a SAGCN for joint-specific spatial message passing, enhancing model adaptivity.
- Experimental results on benchmarks like Human3.6M and MPI-INF-3DHP demonstrate superior performance in MPJPE and efficiency compared to prior methods.
Motion-Adaptive Multi-Scale Temporal Modelling with Skeleton-Constrained Spatial Graphs for Efficient 3D Human Pose Estimation
Introduction
This work introduces MASC-Pose, an efficient framework for 3D human pose estimation from monocular 2D pose sequences, combining adaptive multi-scale temporal modeling with skeleton-constrained spatial graphs. The method directly addresses key limitations of prior Transformer-based and graph-based approaches in spatial and temporal dependency modeling—specifically, the inefficiency and lack of adaptability in handling diverse and heterogeneous motion dynamics across both long- and short-term temporal contexts, as well as the limited flexibility in modeling joint-specific spatial interactions. The hybrid architecture leverages an Adaptive Multi-scale Temporal Modelling (AMTM) module to capture variable temporal dependencies and a Skeleton-constrained Adaptive GCN (SAGCN) to enable joint-specific spatial message passing.
Previous methods for 3D human pose estimation, such as PoseFormer, MixSTE, and TCPFormer, have primarily used full-sequence or fixed-scale temporal attention, often employing dense Transformer-based architectures with limited inductive bias and high computational complexity. Meanwhile, graph-based methods utilizing skeletal priors have shown improvements in spatial structure modeling but typically rely on fixed aggregation schemes that do not optimally balance self-information and neighboring features for all joints.
The central insight motivating MASC-Pose is that human motions possess inherently multi-scale and heterogeneous characteristics: actions like walking and running require long-term context for periodicity, whereas hand gestures and transitions demand short, fine-grained modeling. Similarly, different joints demonstrate variegated spatial relationships depending on the action and pose.
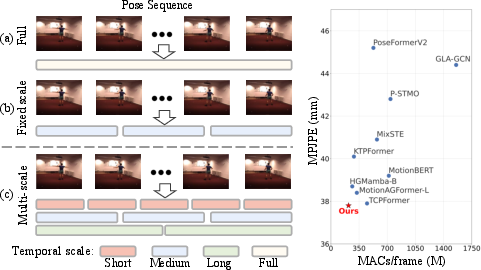
Figure 1: Comparison of temporal dependency modeling strategies and efficiency–accuracy trade-offs, with the proposed multi-scale method (c) providing improved accuracy at reduced computational cost.
Methodology
Skeleton-Constrained Adaptive GCN (SAGCN)
SAGCN constitutes the backbone for spatial feature encoding. This component replaces uniform aggregation by decoupling self-feature transformation and neighbor aggregation via skeleton-derived adjacency, enabling adaptivity in the propagation of information for each joint:
Adaptive Multi-scale Temporal Modelling (AMTM)
AMTM addresses temporal modeling via the following mechanisms:
- Multi-scale Temporal Windows: Three temporal branches process short (9 frames), medium (27 frames), and long (81 frames) temporal windows in parallel, capturing both rapid transitions and long-range dependencies.
- Soft Routing via Mixture-of-Experts Paradigm: A lightweight global average pool + MLP predicts a softmax-weighted combination of the different temporal branches for each instance, leading to adaptive focus on relevant window sizes.
- Sparse Temporal Graph Convolution (STGC): Efficient temporal dependencies are modeled using sparse temporal adjacency matrices computed via top-k similarity, supporting scalable complexity.
- Progressive Layer Fusion: A softmax-based fusion module combines multi-scale and original features and aggregates across multiple layers, improving representational granularity and gradient propagation.
Experimental Results and Analysis
Extensive experiments conducted on Human3.6M and MPI-INF-3DHP validate the approach. MASC-Pose attains state-of-the-art performance in terms of MPJPE (Mean Per Joint Position Error), while requiring fewer parameters and lower computational cost (MACs/frame) compared to contemporary Transformer-based and hybrid models, including TCPFormer, KTPFormer, and MotionAGFormer. On Human3.6M, the method achieves an MPJPE of 37.8 mm, outperforming other methods at significantly reduced MACs/frame.
Figure 1: Efficiency–accuracy plot indicating superiority of MASC-Pose in the efficiency regime.
In the MPI-INF-3DHP benchmark, MASC-Pose matches or exceeds best-in-class scores for PCK and AUC, maintaining robust generalization across diverse motion types.
Ablations and Adaptivity
Ablation studies substantiate the importance of both the AMTM and SAGCN modules, with adaptive multi-scale temporal aggregation contributing the largest accuracy gain. Notably, adaptive weight learning within AMTM surpasses fixed-weights or non-adaptive configurations. The optimal temporal scale configuration ([9,27,81]) balances the capture of both short- and long-term dynamics. Reducing the spatial propagation range to direct neighbors (K=1) within SAGCN avoids performance loss due to over-smoothing.
Qualitative Comparisons
Visual analysis on in-the-wild and Human3.6M sequences reveals increased stability and anatomical plausibility of MASC-Pose output relative to TCPFormer and MotionAGFormer in challenging frames affected by ambiguous or noisy 2D detections.
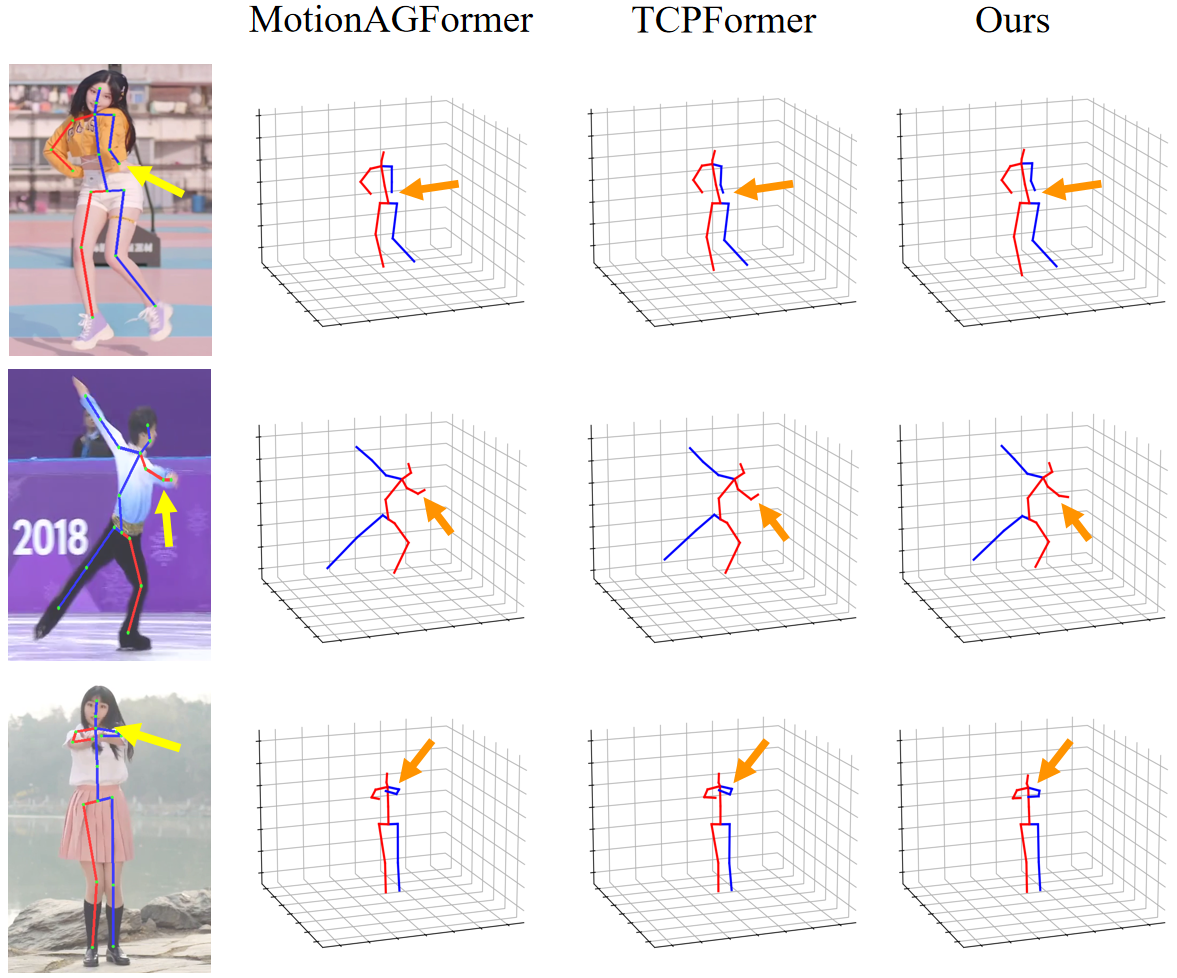
Figure 3: Output comparison shows superior robustness to input errors and ambiguity for MASC-Pose compared to prior methods in unconstrained videos.
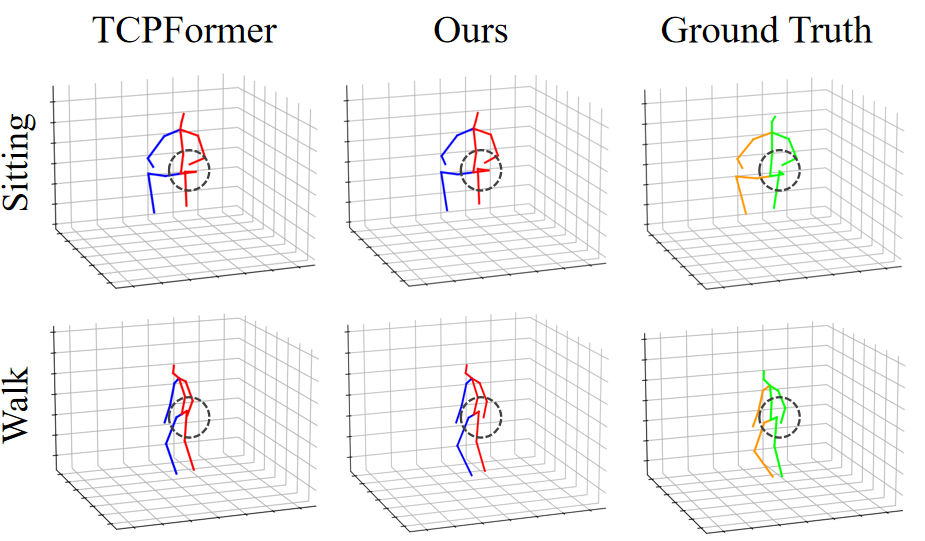
Figure 4: On canonical Human3.6M actions, predicted joint locations by MASC-Pose better match ground-truth especially in difficult poses.
Temporal Scale Adaptivity
Analysis of learned temporal scale weights demonstrates action- and joint-specific specialization. For example, repetitive actions (Walk) afford higher weights on long-term branches for lower body, while transitional actions (SittingDown) emphasize short/medium-term information across all groups.
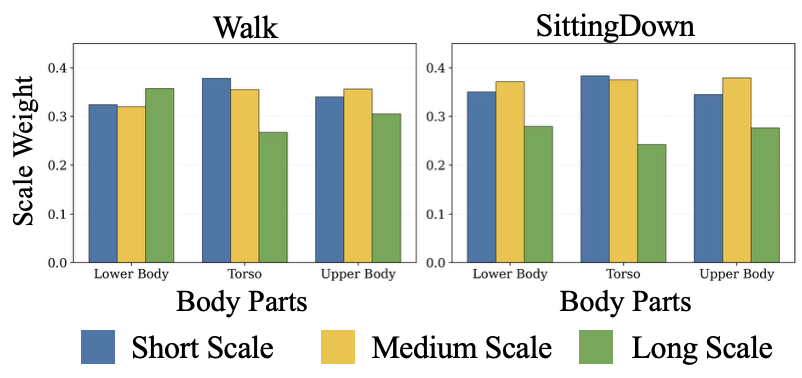
Figure 5: Learned scale weights (short/medium/long) over joint groups for different actions demonstrate dynamic adaptation at both motion and anatomical granularity.
Practical and Theoretical Implications
MASC-Pose demonstrates that joint adaptivity in both spatial and temporal domains can be realized efficiently with a hybrid network that leverages domain priors (skeleton graphs) and context-aware soft-routing (multi-scale temporal branches). The architecture provides a blueprint for future work aiming to model dynamic structure in vision tasks involving articulated objects or multi-scale dependencies.
Potential practical extensions include application to real-time 3D pose estimation in human–computer interaction and virtual reality, as well as further generalization to out-of-distribution motion and cross-dataset settings. The modular, lightweight design supports deployment in resource-constrained environments.
Conclusion
MASC-Pose yields a compelling architectural innovation for accurate and efficient 3D human pose estimation. By integrating adaptive, context-sensitive multi-scale temporal modeling with skeleton-constrained spatial graph convolutions, the approach outperforms previous methods in both accuracy and resource efficiency. Future research can extend this framework toward more flexible window partitioning, overlapping temporal scales, and real-world, cross-dataset generalization.