- The paper introduces a novel gated cross-modal architecture that adaptively fuses unimodal and cross-modal signals to enhance sentiment classification.
- It employs explicit temporal sequencing to capture dialogue context, achieving improved accuracy over conventional concatenation methods.
- The model reaches state-of-the-art metrics on benchmarks like CMU-MOSI and CMU-MOSEI with fewer parameters and reduced computational cost.
CAGMamba: Context-Aware Gated Cross-Modal Mamba Network for Multimodal Sentiment Analysis
Introduction
CAGMamba introduces a novel framework for multimodal sentiment analysis (MSA) that addresses two pervasive bottlenecks: (1) the inefficiency of Transformer-based cross-modal attention for long contexts due to quadratic complexity, and (2) the insufficient exploitation of contextual dependencies in dialogue-based sentiment, where the current utterance’s sentiment is often informed by preceding turns. The method leverages the Mamba architecture for linear-time sequence modeling and proposes explicit temporal ordering of context and main utterance features. It further advanced a Gated Cross-Modal Mamba Network (GCMN) that enables fine-grained, learnable gating control for fusion of cross-modal and unimodal signals.
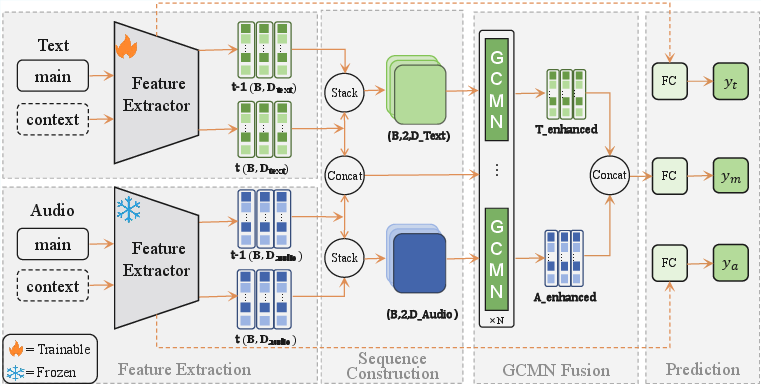
Figure 1: The high-level structure of the CAGMamba model integrates feature extraction, context-aware sequence construction, GCMN fusion, and multi-task sentiment prediction.
CAGMamba achieves new state-of-the-art results across multiple metrics and datasets with improved efficiency, outperforming high-capacity Transformer-based models with fewer parameters and computational cost.
Context-Aware Sequence Construction
To explicitly model temporal sentiment flows in dialogues, CAGMamba organizes contextual and current utterance features as a temporally ordered binary sequence. Text and audio representations are projectively aligned into a fusion space; the context-to-main sequencing is designed such that the input to Mamba models not only static relationships but also directional transitions of sentiment states across dialogue turns. Parameter sharing and adaptive absorption matrices in Mamba’s selective state space facilitate dynamic integration of context into interpretation of the current utterance.
Gated Cross-Modal Mamba Network (GCMN)
CAGMamba’s GCMN fusion module is built around two core innovations: bidirectional state scanning for robust context encoding, and learnable, sample-dependent modulation of cross-modal information flows.
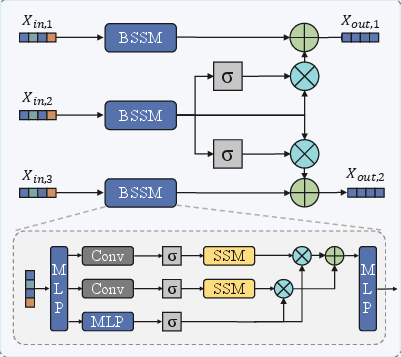
Figure 2: The GCMN module’s architecture, showcasing the three-stream gated fusion (upper) and internal bidirectional selective scanning module (lower) for context-sensitive sequence modeling.
Bi-directional Selective Scanning Module (BSSM)
The BSSM combines forward and backward selective state space models with deep convolutional projections. Dual scan branches (forward and backward) capture global dependencies, which are multiplicatively merged to yield a rich, bidirectional representation of temporal sentiment evolution. A parallel gating branch modulates the output, controlling information passing at each timestep based on input-derived confidence.
Three-Stream Gated Fusion
Unlike models that forcibly conflate all modal information, GCMN retains parallel subspaces for unimodal and cross-modal streams. For each modality, a learnable gating vector selects the optimal fusion ratio between the modality’s unimodal sequence and its cross-modal counterpart. The gating mechanism operates at the instance level, granting adaptive fusion contingent on sample-specific content, thereby preventing modal interference and supporting robust generalization under ambiguous or noisy multimodal signals.
Multi-Task Prediction and Training
CAGMamba employs three prediction heads: two unimodal (text, audio) and one multimodal (fused). All branches are supervised with mean-squared error loss; task balances are calibrated via tunable coefficients. The fusion head’s prediction is employed for inference, but the inclusion of unimodal branches enforces preservation and orthogonality of representation spaces, avoiding destructive overfitting to fusion parameters.
Experimental Results
Benchmark Results
On three diverse datasets—CMU-MOSI, CMU-MOSEI, and CH-SIMS—CAGMamba robustly outperforms all Transformer-based and state space model baselines. On CMU-MOSI, the model yields an Acc-2 of 88.19 and F1 of 90.09, outperforming prior SOTA (MMML and Semi-IIN) by significant margins, particularly in disambiguating subtle sentiment cues. CAGMamba exhibits top Corr (0.88 on CMU-MOSI, 0.82 on CMU-MOSEI) and competitive MAE, underscoring both its classification and ranking capabilities.
The results demonstrate that explicitly sequenced context boosts performance compared to simple concatenation (gains of 1-2 Acc points), and adaptive gating further increases accuracy, especially on variable or ambiguous instances.
Ablation and Efficiency Analysis
Ablation studies evidence that each core component—explicit context sequence ordering and learnable gating—imparts cumulative improvements. Increasing the text context window is highly beneficial up to two preceding utterances; increasing audio context beyond one yields diminishing returns, confirming the higher diagnostic value of text for sentiment memory.
Parameter- and FLOPs-efficiency experiments reveal that CAGMamba achieves SOTA performance with 0.8M parameters and 0.10 GFLOPs, outperforming larger Transformer and MSAmba models by 1.9–3.4 Acc points. The model’s inductive biases, rather than raw capacity, underwrite these gains.
Representation Quality
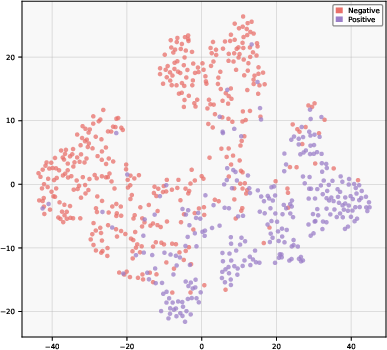
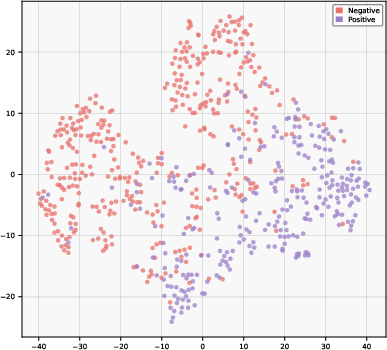
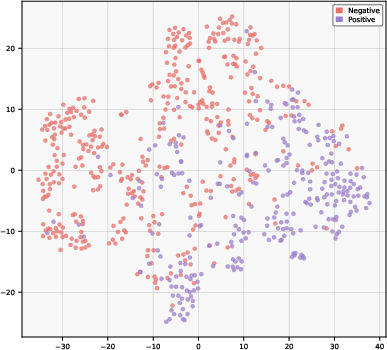
Figure 3: T-SNE projections of learned representations on CMU-MOSI demonstrate that GCMN’s learnable gating yields tightly clustered intra-class and widely separated inter-class sentiment geometries, outperforming both fixed-fusion and cross-modal only strategies.
t-SNE visualizations show that CAGMamba representations are more compact within classes and provide sharper separation across sentiment boundaries than fixed or ungated fusion approaches. This indicates effective suppression of irrelevant inter-modal noise and an improved embedding geometry for downstream tasks.
Practical and Theoretical Implications
The results suggest that sequence modeling architectures with explicit temporal context and fine-grained fusion control are optimal for dialogue-based MSA tasks characterized by ambiguous, evolving sentiment signals. CAGMamba’s generalization across languages (English, Chinese), high and low resource settings, and varied evaluation protocols indicates broad utility for industrial sentiment analysis deployments wherever computational budget is a concern.
Theoretically, this work underscores the benefits of state space models in structured multimodal learning and challenges the hegemony of attention-based fusion in sequence modeling. The sample-wise gating mechanism provides a prototypical framework for future adaptive, content-aware fusion models.
Conclusion
CAGMamba sets a new SOTA benchmark for multimodal sentiment analysis with markedly fewer parameters and improved sample efficiency. It demonstrates that explicit context ordering and gated, adaptive fusion are superior to vanilla cross-modal attention or concatenation approaches in both robustness and fidelity. Open research questions remain regarding the modeling of longer-range conversational context, domain transfer, and annotation granularity. Future developments will likely focus on extending these mechanisms to larger context windows, additional modalities (e.g., vision), and fully end-to-end pretrained architectures.