- The paper introduces a modular approach by decomposing news classification into five interacting agents for interpretable, retrieval-augmented, and iterative processing.
- Its retrieval-augmented generation and adaptive fusion techniques boost performance, achieving 91.2% accuracy and improved macro-F1 scores on the NewsMM dataset.
- The framework delivers strong evidence-grounded explanations, paving the way for audit-friendly and scalable multimodal news analytics.
MultiPress: Interpretable Multimodal News Classification via Multi-Agent Collaboration
Introduction
The rapid proliferation of multimodal news content necessitates advanced architectures capable of robust cross-modal reasoning and knowledge integration. While conventional multimodal news classifiers primarily employ shallow fusion strategies and lack explicit external knowledge incorporation, "MultiPress: A Multi-Agent Framework for Interpretable Multimodal News Classification" (2604.03586) introduces a modular, three-stage multi-agent system—MultiPress—targeted at interpretable, retrieval-augmented, and iterative multimodal news classification.
MultiPress Architecture Overview
MultiPress decomposes news topic classification into five explicit, interacting agents: (1) Perception, (2) Retrieval-Augmented Generation (RAG), (3) Online Reasoning, (4) Gated Fusion, and (5) Reward-based Evaluation. Each agent operates on structured messages, enabling controllable evidence tracking and efficient collaboration.
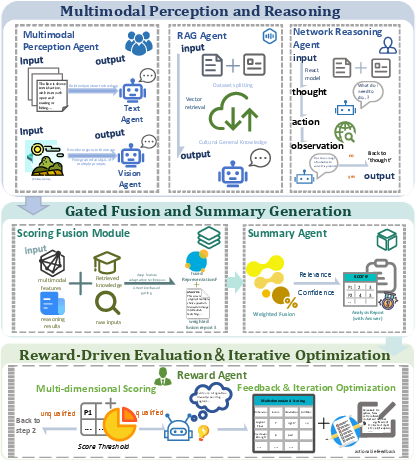
Figure 1: The MultiPress framework, depicting specialized agents for multimodal perception, knowledge retrieval, iterative reasoning, adaptive fusion, and reward-based refinement in multimodal news classification.
The pipeline proceeds as follows:
- The Perception Agent parses text and image modalities independently, outputting structured cues (entities, keywords, objects, scene types, and summarized descriptions).
- The RAG Agent retrieves top-k semantically relevant external knowledge snippets through joint text-image embedding and vector search, with similarity-based filtering for evidence reliability.
- The Online Reasoning Agent executes ReAct-style iterative search-and-thought, dynamically integrating new evidence or context via multi-hop reflection and verification.
- The Fusion Agent applies an adaptive gating mechanism, integrating all modality-specific and retrieved knowledge with softmax-weighted reliability control.
- The Reward Agent computes an explicit reward function combining classification confidence, evidence grounding, and cross-modal consistency, triggering agentic iterative refinement until convergence.
NewsMM: Construction of a Large-Scale Multimodal Benchmark
To rigorously benchmark the architecture, the authors curate NewsMM: 7,200 news articles (headline, body, and at least one high-quality image) spanning eight categories with high inter-annotator agreement and expert adjudication. Each sample is verified through tri-annotator majority, GPT-based cross-validation, and expert review.
An accompanying external knowledge base integrates the NewsMM train set, multiple standard news corpora, and hand-curated domain-specific encyclopedic data, embedded into a shared semantic retrieval space using SOTA multimodal encoders. This design allows for robust, low-latency RAG at inference.
Experimental Results
MultiPress yields consistently superior results relative to monolithic or naively fused multimodal baselines, both open and proprietary. For instance, employed on top of GPT-4o, MultiPress achieves 91.2% accuracy and 90.4 macro-F1 on NewsMM, substantially exceeding direct GPT-4o (79.6/78.7) and the best open-source baseline (mPLUG-7B, 68.9/67.8). Gains are robust across backbone architectures (e.g., Qwen2.5-VL-7B).
Module Contribution and Sensitivity
Ablation reveals significant performance drops upon removal of (i) retrieval-augmented generation (−4.7 accuracy), verifying external knowledge importance; (ii) online reasoning agent (−4.1), supporting multi-hop correction; (iii) adaptive fusion (−6.3), which proves central for resolving ambiguous or noisy multimodal cues.
Reward-driven iterative refinement yields diminishing returns, with two iterations sufficing for optimal performance. Moderate retrieval depths (k=3∼5) perform best; overly large k yields spurious or conflicting context.
Generalization and Efficiency
Performance gains persist on extra-news multimodal reasoning sets (MathVerse, MMStar, MMMU), confirming the framework generalizes beyond the original domain. MultiPress introduces higher computation and latency due to its iterative and retrieval-heavy pipeline; however, batch/offline suitability and clear path for distillation/caching are identified.
Interpretability
Human evaluation on explanation quality demonstrates that MultiPress provides rationales that are notably more faithful (4.65/5) and evidence-grounded (4.72/5) than strong baselines, validating the structured agentic design.
Implications and Future Directions
By systematically decoupling multimodal perception, knowledge retrieval, iterative reasoning, and fusion, MultiPress addresses several open problems in multimodal news classification—specifically, model hallucination, poor knowledge grounding, opaque reasoning, and instability on ambiguous inputs.
Practically, MultiPress advances interpretable news analytics, with immediate applications in auditability, content moderation, and information veracity assessment. The approach is inherently extensible: augmenting perceptual and retrieval subsystems with video/audio, introducing dynamic or domain-adapted reward components, or leveraging model distillation for deployment in latency-sensitive environments.
Theoretically, the work demonstrates that modular agentic decomposition and RAG-driven iteration outperform monolithic black-box LLMs in complex multimodal tasks, corroborating concurrent trends in multi-agent debate and collaborative reasoning frameworks. Integration with recent agentic RAG paradigms (e.g., HM-RAG, MultiRAG) and expansion into domains requiring structured evidence trails—such as legal, medical, or scientific text-image reasoning—represent logical future extensions.
Conclusion
The MultiPress framework marks a substantial advance in interpretable, knowledge-augmented, and robust multimodal classification, leveraging explicit agent collaboration, adaptive fusion, and structured reward optimization. Both the underlying NewsMM dataset and modular architecture provide a reproducible testbed and blueprint for future work in dynamic, interpretable, and scalable multimodal understanding (2604.03586).

