- The paper quantitatively benchmarks popular scikit-learn regularizers using 134,400 simulation runs to reveal when methodological differences matter.
- It shows that Ridge offers computational efficiency and robust prediction when n/p is high, while ElasticNet excels under high correlation and low sample conditions.
- The study advises against Lasso and Post-Lasso OLS in ill-conditioned settings, emphasizing the need to choose regularizers based on observable data properties.
Selection and Benchmarking of Regularization in Applied Machine Learning
Background and Motivation
Regularization remains foundational in ML for mitigating overfitting and improving model generalization, especially in high-dimensional, collinear, or noisy settings. The paper “Choosing the Right Regularizer for Applied ML: Simulation Benchmarks of Popular Scikit-learn Regularization Frameworks” (2604.03541) addresses the practical selection of regularization strategies using large-scale empirical evaluation. The work systematically compares scikit-learn implementations of Lasso, Ridge, ElasticNet, and Post-Lasso OLS across 134,400 simulations parameterized by realistic data geometries encountered in production environments.
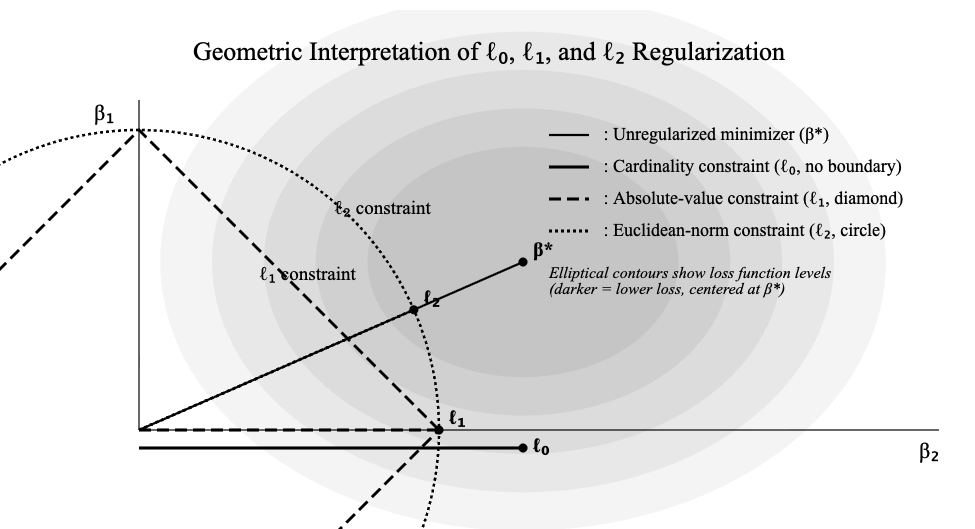
Figure 1: The three principal regularization norms—ℓ0, ℓ1, and ℓ2—impose different constraints and lead to distinct coefficient selection and shrinkage behaviors.
The paper fills an evidence gap by determining in which applied regimes the methodological differences between these regularization techniques become statistically or practically relevant, and formulates actionable guidance for practitioners based on the observable properties of their data.
Simulation Framework and Parameterization
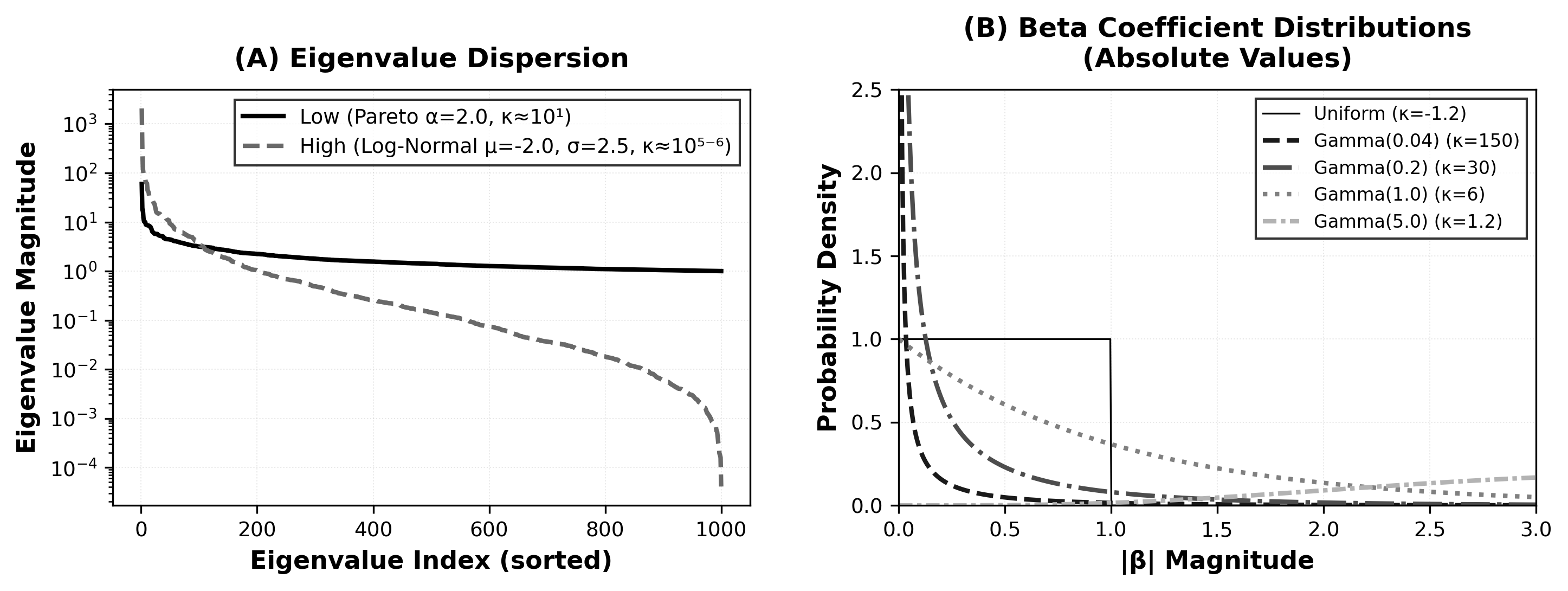
A distinct strength of the work is the construction of a rich manifold of feature spaces reflecting genuine production ML tasks. Eight real-world datasets are used as the empirical anchor for the simulated parameter ranges. Seven key hyperparameters are independently varied:
Rather than fixating on synthetic edge cases, these choices capture the essence of multicollinearity, weak signal, and sparsity, with p∈{64,128}, n spanning 100 to 100k, and ℓ10 explicitly bracketed across orders of magnitude. Effect sizes (ℓ11) are sampled from five canonical distributions and sparsified at both 0% and 15%. For each parameter combination, 35 random realizations are executed per method, resulting in a total of 134,400 evaluated model fits.
A critical implementation note is the uniformity of validation protocols: all frameworks are subject to the same ℓ12 grids, cross-validation folds, and train/test splits, guaranteeing comparability.
Major Empirical Findings
A central finding is that for prediction—where root mean squared error is the operative metric—Ridge, Lasso, and ElasticNet are nearly interchangeable as long as the sample-to-feature ratio (ℓ13) is sufficient (ℓ14). The largest observed median RMSE difference among these methods is under 0.3%, which is negligible compared to other sources of modeling variance. Computational efficiency then becomes the dominant consideration, and Ridge yields substantial runtime advantages due to its analytic solution.
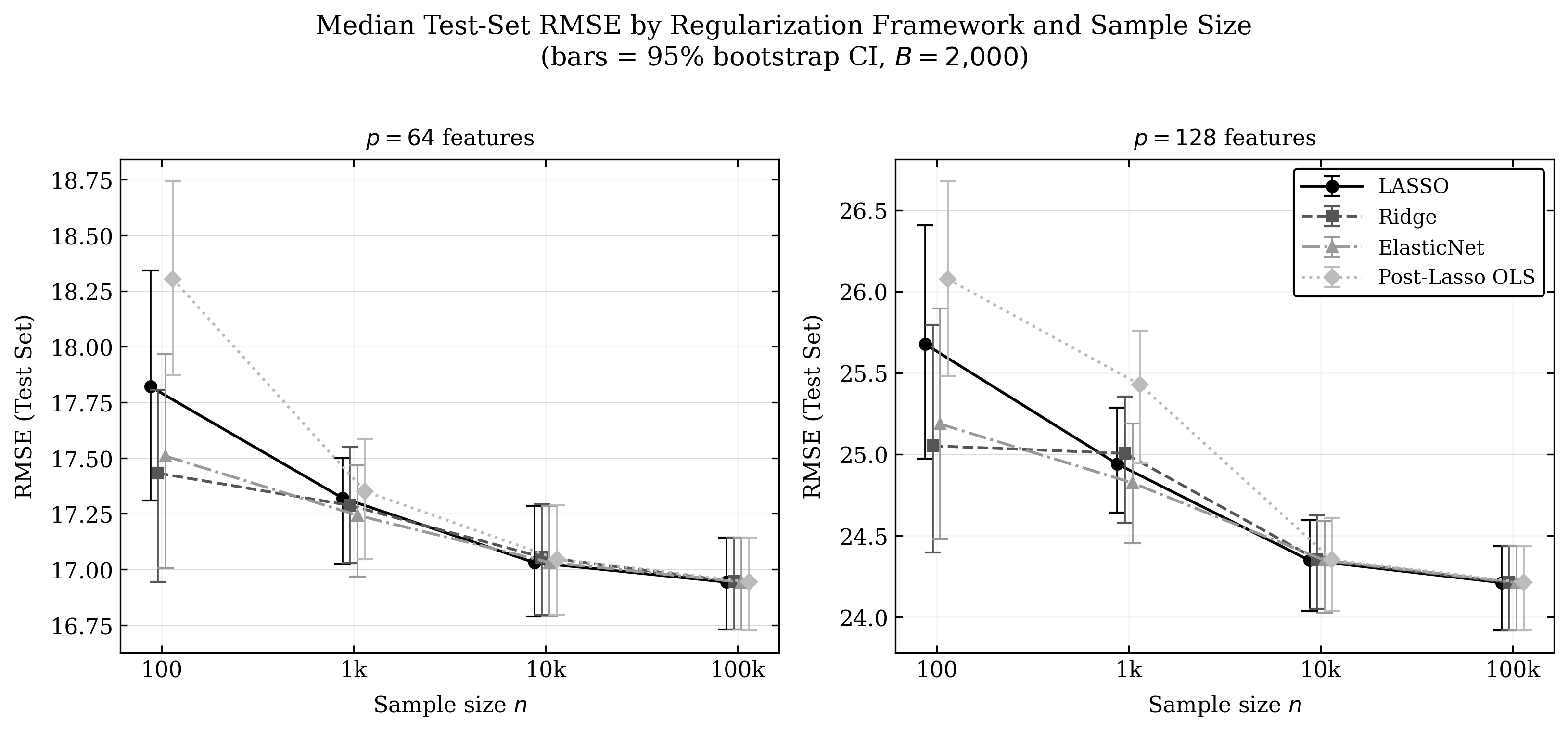
Figure 3: ElasticNetCV most frequently achieves the lowest RMSE, but the margin is functionally insignificant for ℓ15.
As shown, method choice affects predictive performance only in highly data-constrained (low ℓ16) or low-SNR regimes, where method-specific failures can become acute.
Variable Selection and Recall Fragility
While convex regularizers behave similarly for RMSE with reasonable ℓ17, their performance diverges dramatically for variable (support) recovery, especially in ill-conditioned or undersampled regimes. Lasso's recall collapses sharply under high multicollinearity (high ℓ18) and low SNR, dropping to 0.18, whereas ElasticNet maintains recall above 0.93 across the same parameterizations—a ℓ19 gap.
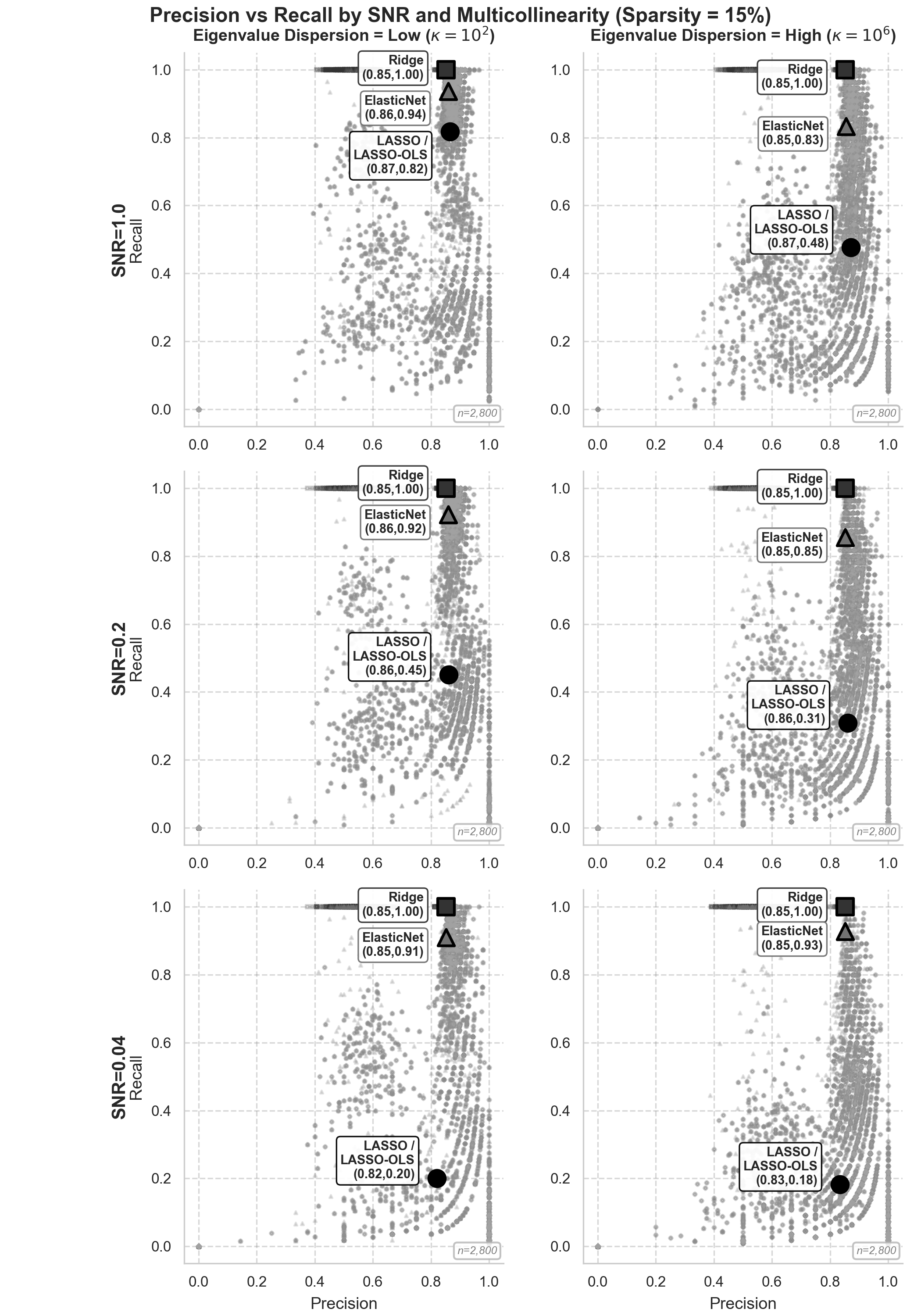
Figure 4: Lasso coefficient recovery recall degrades rapidly as SNR falls and multicollinearity intensifies, exposing instability unseen in Ridge or ElasticNet.
ElasticNet, by interpolating between ℓ20 and ℓ21, achieves stable recall in the face of collinearity without sacrificing parsimony. Thus, practitioners are advised to avoid Lasso (and its Post-Lasso OLS variant) under high ℓ22 with small ℓ23; ElasticNet remains the only method that is robust in such settings.
Coefficient Estimation
For accurate recovery of the coefficient vector (minimizing ℓ24 error), Ridge and ElasticNet are preferred when the ℓ25 distribution is dense and ℓ26 is large, while Lasso is competitive only in sparse, well-conditioned settings. Post-Lasso OLS proves fragile and is almost always outperformed by ElasticNet and Ridge, except in rare cases where feature selection is nearly perfect and the feature space is `friendly.'
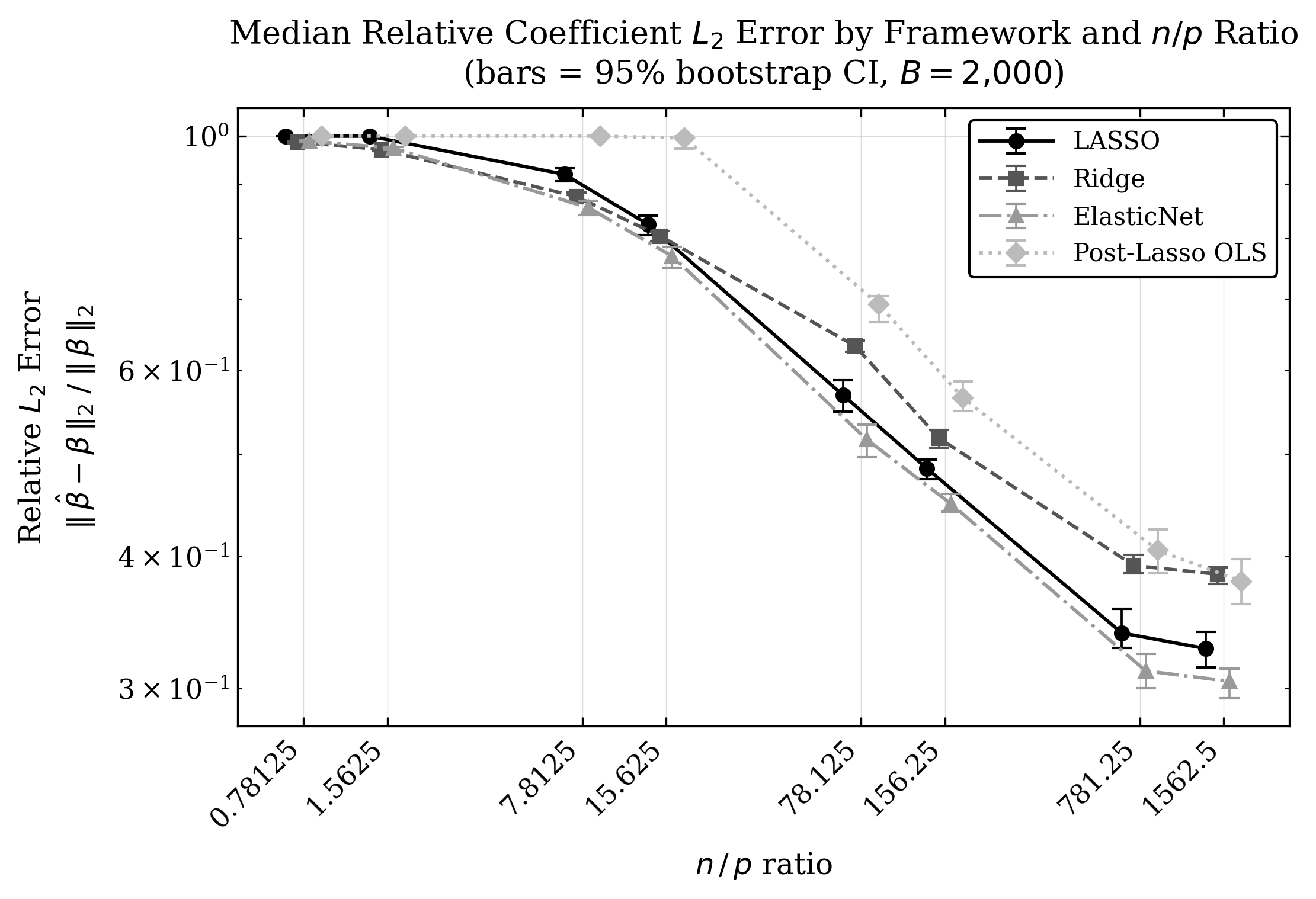
Figure 5: Post-Lasso OLS experiences the largest ℓ27 error, especially pronounced as the ℓ28 ratio decreases.
Computational Efficiency
Ridge regression is consistently more computationally efficient than ElasticNet or Lasso, with ElasticNet incurring 5–23x median and up to 200x mean runtime costs at larger ℓ29 due to cross-validated grid search over both p0 and the L1 ratio. For models retrained frequently or at scale, this leads to substantial operational savings.
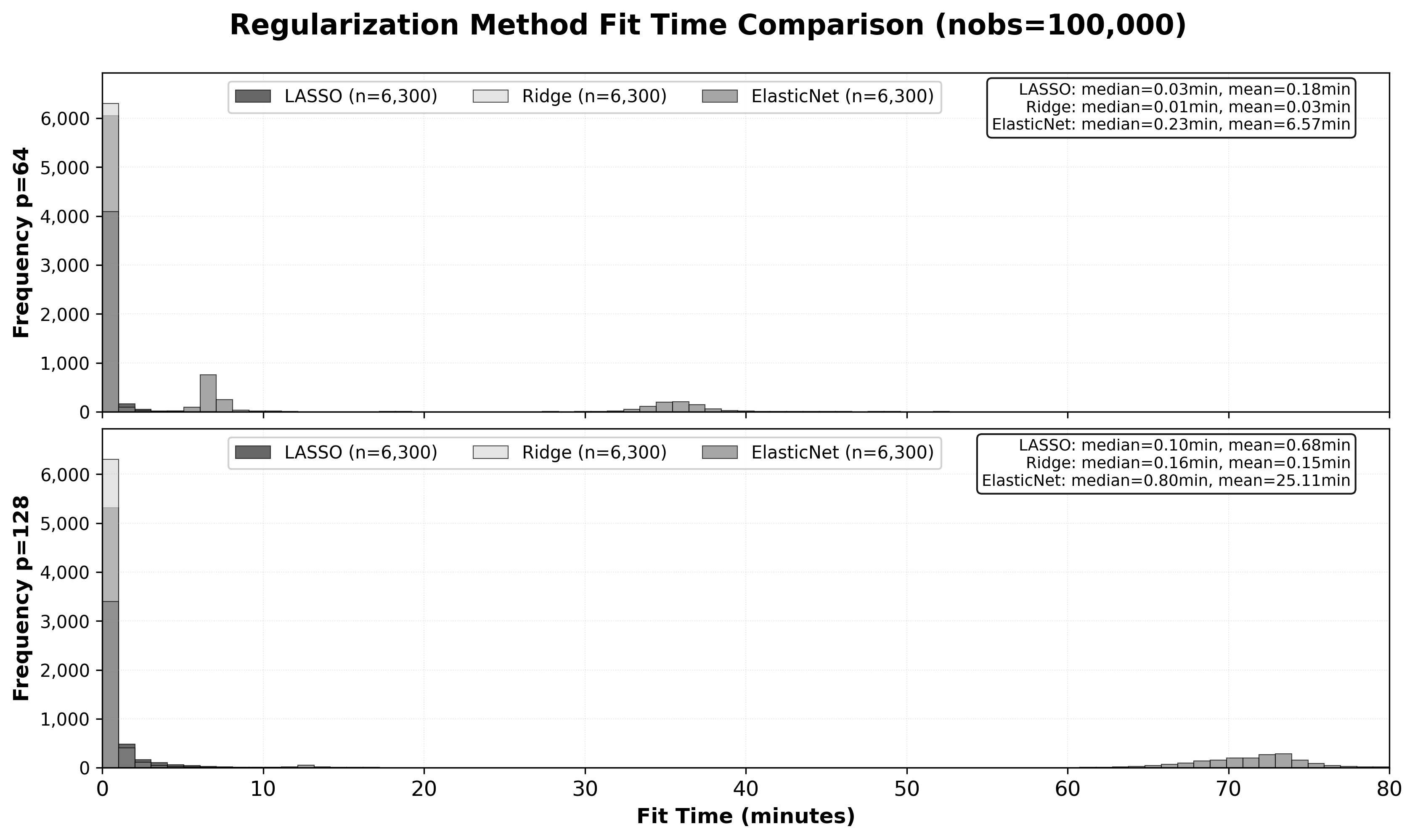
Figure 6: Ridge achieves orders-of-magnitude lower fit times than ElasticNet, rendering it the default choice when predictive performance is the only concern.
Objective-Driven Decision Framework
The authors synthesize the empirical findings into a flowchart for method selection based only on observable quantities: p1, p2 (via numpy.linalg.cond(X)), and the value of p3 selected by internal CV (a proxy for SNR).
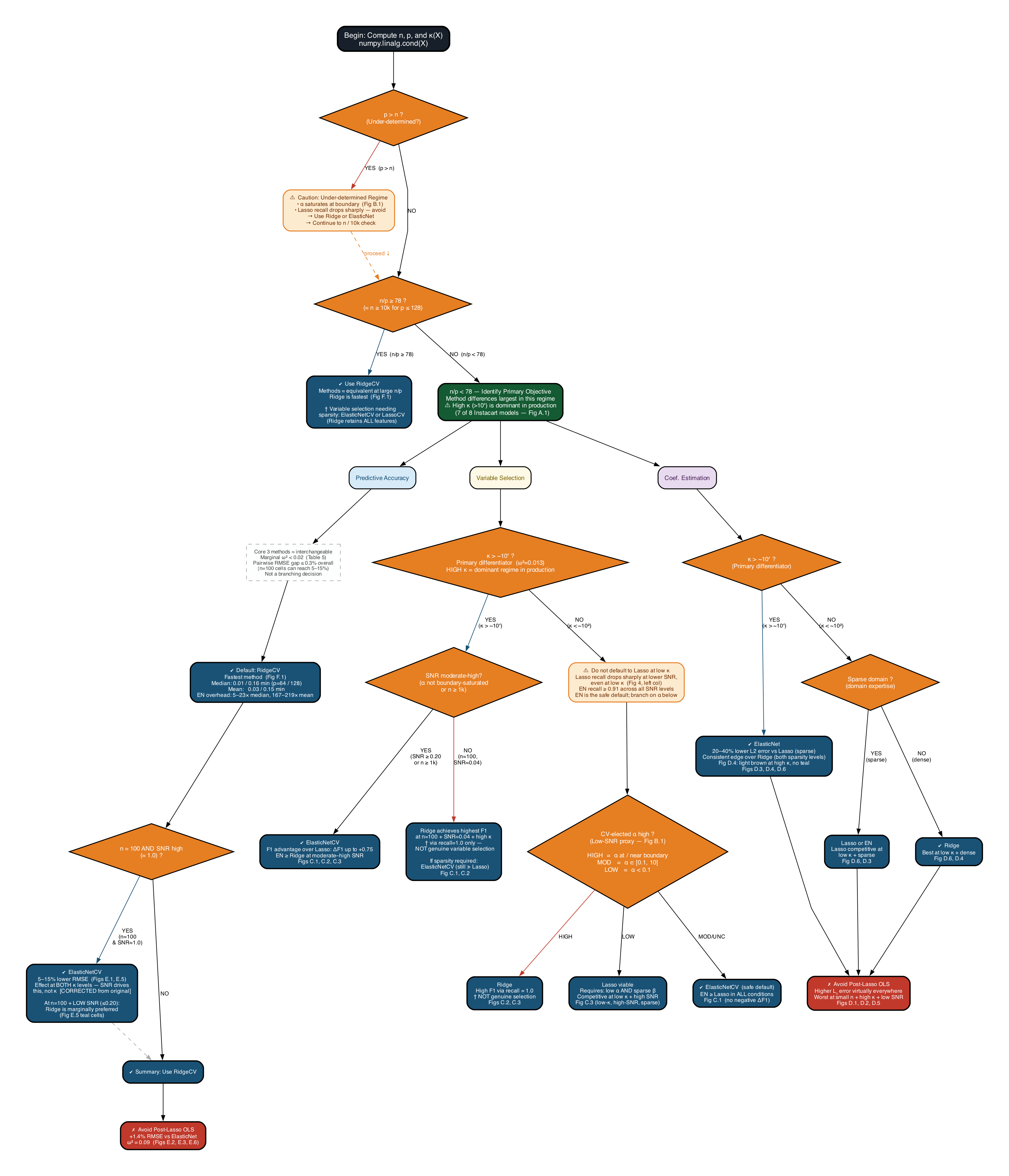
Figure 7: Objective-based flow for selecting the optimal regularization framework based on application goal, p4, p5, and LassoCV-elected p6.
The rules that emerge are:
- If p7: All methods converge; prefer Ridge for efficiency, or ElasticNet if explicit support recovery is needed.
- If p8 (underdetermined): Avoid Lasso; use Ridge or ElasticNet (Lasso recall collapses).
- If p9:
- At high r/p0: ElasticNet strictly dominates Lasso and Ridge for selection and estimation.
- At low r/p1: Lasso is only advisable if CV-selected r/p2 is low (high SNR) and sparsity is expected; otherwise, ElasticNet is safest.
- Post-Lasso OLS should be avoided except in controlled settings where pure r/p3 selection is possible and verified.
These rules are empirically validated across the simulation grid and have direct operational significance for ML practitioners.
Theoretical and Practical Implications
The empirical uniformity of popular convex regularization methods in the large r/p4 limit is consistent with minimax theory for penalized least squares estimation. The distinct fragility of r/p5 regularization observed here (and not always highlighted in theoretical treatments) in high-r/p6 or low-SNR settings has direct implications for feature engineering pipelines—where practitioners should not assume Lasso's variable selection ability is robust across all data geometries. The scalable recommendation for defaulting to Ridge, or ElasticNet in high-correlation regimes, is defensible for large classes of applied problems.
This benchmarking also clarifies that grid search design (i.e., the choice of r/p7 and L1-ratio bins) can drive up compute cost for multi-hyperparameter regularizers, such as ElasticNet, without material gains for prediction in typical resource-rich settings.
Furthermore, the failure modes of Post-Lasso OLS highlight a distinction between regularization for prediction and inference—a theme in contemporary post-selection inference literature neglected in many applied ML workflows.
Directions for Future Research
The paper explicitly identifies future work needed for the extension and sharpening of its results:
- Calibration between LassoCV-elected r/p8 and true SNR across more realistic and extensive parameter ranges.
- Benchmarking at intermediate r/p9 and higher κ0 (e.g., κ1) for modern high-dimensional applications.
- Comparison with newer, nonconvex, and structured regularizers such as Adaptive Lasso, MCP, and Group Lasso.
- Combining computationally efficient solutions (Ridge) with post-hoc feature importance for selection.
Conclusion
This study establishes a data-driven, simulation-anchored benchmark for choosing among scikit-learn regularization routines under practical data constraints. The main actionable result is that for predictive applications, Ridge is preferable given its efficiency and robust performance. ElasticNet is necessary in high-correlation, small-sample, or feature selection-focused regimes, whereas Lasso is only safe in sparse, low-correlation, high-SNR scenarios. Post-Lasso OLS is inadvisable in most applied contexts. The simulation methodology and flowchart provided represent a rigorous, immediately applicable contribution to the operational ML literature, equipping practitioners to make regularization choices grounded in observable data geometry and modeling objectives.