- The paper introduces a human-centered evaluation framework comparing LLM Cultural Representation Vectors with native Cultural Importance Vectors using Pearson correlation, cosine similarity, and MSE.
- LLMs demonstrate systemic misrepresentation and Western-centric biases, with facet-level errors diluting locally salient cultural priorities across diverse regions.
- Consistent error patterns across models point to shared training biases, highlighting the need for culturally adaptive pretraining and integration of real-time native feedback.
Cultural Authenticity Evaluation of LLMs: Alignment with Native Human Expectations
Introduction
This work addresses the critical problem of cultural representation in frontier LLMs, specifically probing their ability to authentically mirror the priorities of native populations across diverse national contexts. Moving beyond prevailing proxies such as cultural diversity or factual knowledge, the paper establishes a human-centered evaluation framework for assessing cultural authenticity. It introduces two key constructs: human-derived Cultural Importance Vectors and model-derived Cultural Representation Vectors. Using open-ended survey data from nine countries, the authors elucidate the extent to which Gemini 2.5 Pro, GPT-4o, and Claude 3.5 Haiku reproduce the relative importance assigned by natives to eleven salient cultural facets.
Methodology
Establishing Human Ground-Truth: Cultural Importance Vectors
The first phase leverages open-ended survey responses collected across nine countries, operationalizing "cultural importance" as the distribution over eleven discretely defined cultural facets (e.g., Architecture, Cuisine, Social Practices/Customs, Values/Norms/Beliefs/Morality [VNBM]). A high-precision Gemini 2.5-based classification pipeline maps free-text responses to this taxonomy, yielding per-country normalized importance vectors.
Sampling and Reduction of LLM Outputs
In the second phase, the three target LLMs are intensively prompted using a set of 85 syntactically diverse templates per country, each sampled at multiple decoding temperatures. Model responses are autorated to detect which cultural facets are mentioned, producing empirical distributions—Cultural Representation Vectors—analogous to the human-derived baselines. This paradigm enables direct, quantitative comparison between LLM representations and native user expectations.
Alignment Evaluation Metrics
Alignment is assessed via:
- Pearson correlation (ρ): Linear correspondence in facet prioritization.
- Cosine similarity (SC): Hierarchical ranking similarity.
- Mean Squared Error (MSE): Penalizes magnitude of misalignment.
Key Findings
Western-Centric Calibration and Geographic Alignment Disparity
Strong geographic disparities are evident in GPT-4o and Claude 3.5 Haiku, with authentic alignment to native priorities decreasing monotonically with cultural distance from the US, measured via the Cultural Fixation Index (CFST). Gemini displays a more stable, less US-centric calibration.
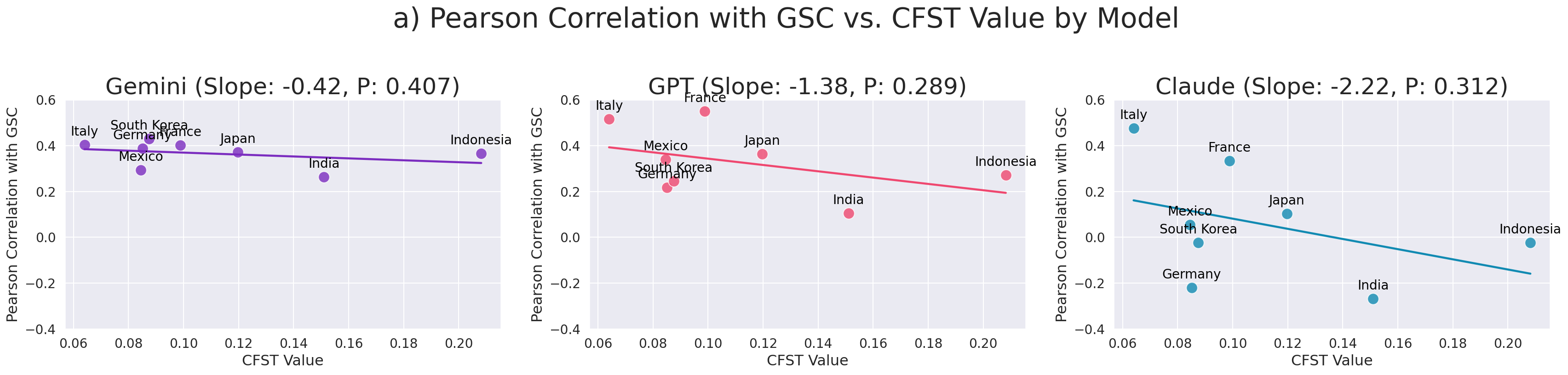
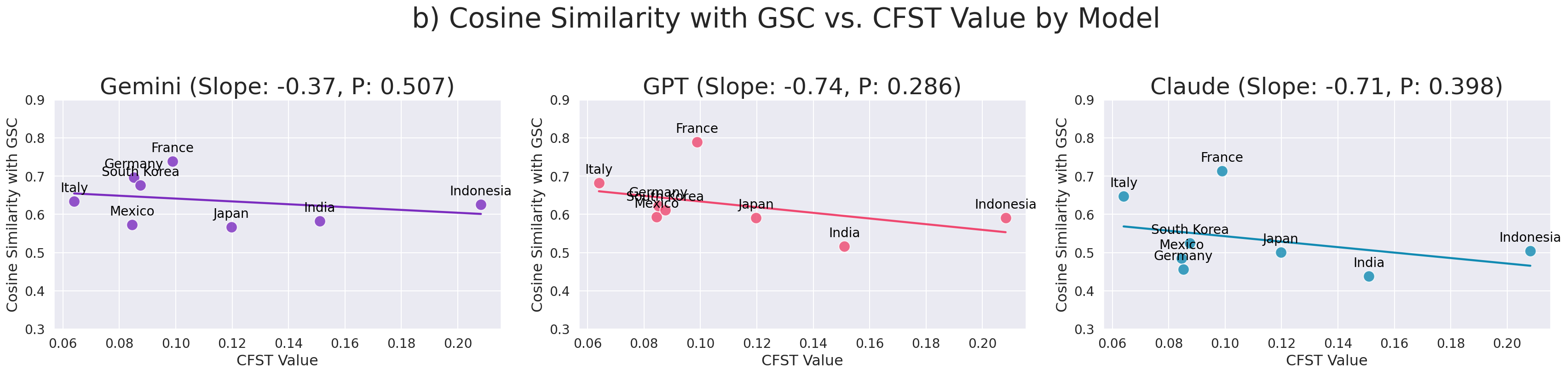
Figure 1: Correlation and cosine similarity between LLM cultural representation and ground-truth as a function of cultural distance from the US; GPT and Claude show clear negative alignment trends as distance increases, unlike Gemini.
Systemic Facet-Level Misrepresentation
Facet-specific MSE reveals that all models tend to misallocate prominence to certain cultural axes (notably Performance and Art, Cuisine, VNBM). Qualitative assessment shows a tendency toward over-saturated, encyclopedic coverage, diluting authentic priority hierarchies observed in human data.
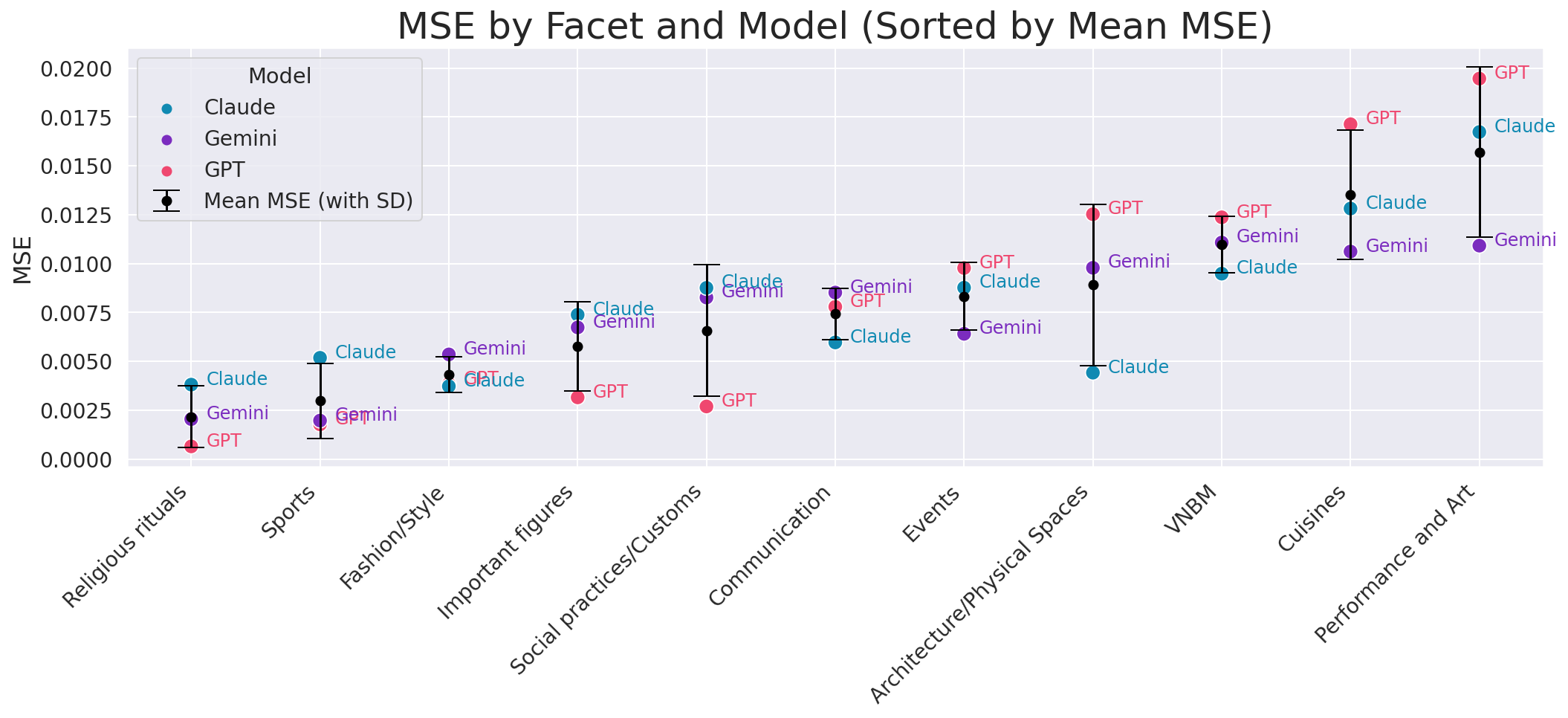
Figure 2: Facet-level MSE quantifying discrepancy between each LLM's output and native importance, aggregated by facet and model.
LLMs routinely underrepresent or flatten the relative magnitude of locally salient facets, producing responses that are broad but insufficiently sensitive to native-defined priorities.
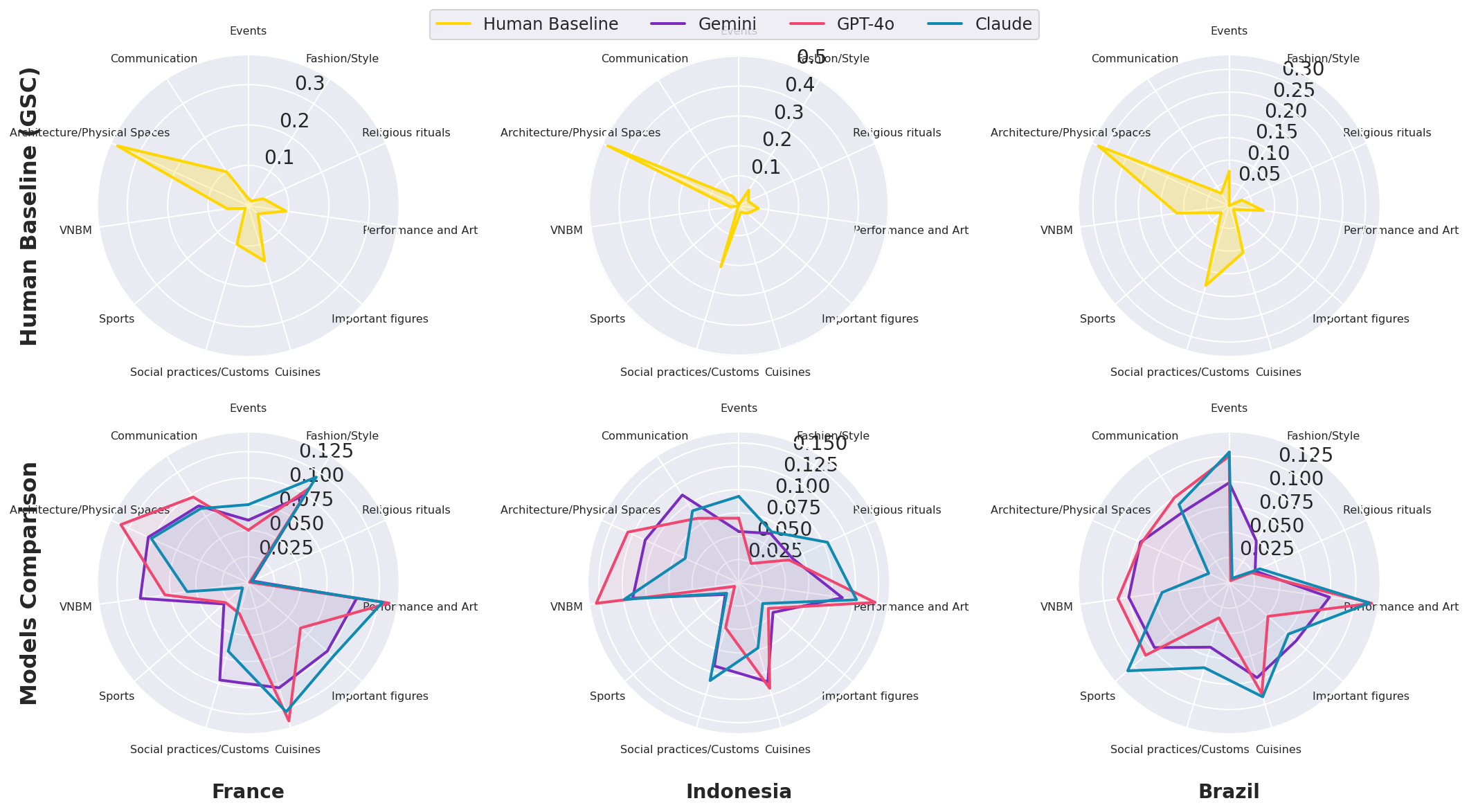
Figure 3: Radar chart comparison of native (GSC) and LLM cultural profiles for select countries, highlighting the tendency of LLMs to output balanced facet distributions rather than mirroring local prioritization.
Error matrices (EM) constructed for each model (country × facet) demonstrate near-perfect cross-model correlation (ρ>0.97), evidencing convergence in misrepresentation signatures. This high-fidelity error alignment suggests that misalignment is primarily a function of shared training biases and global web-scale data, not architecture-specific deficiencies.
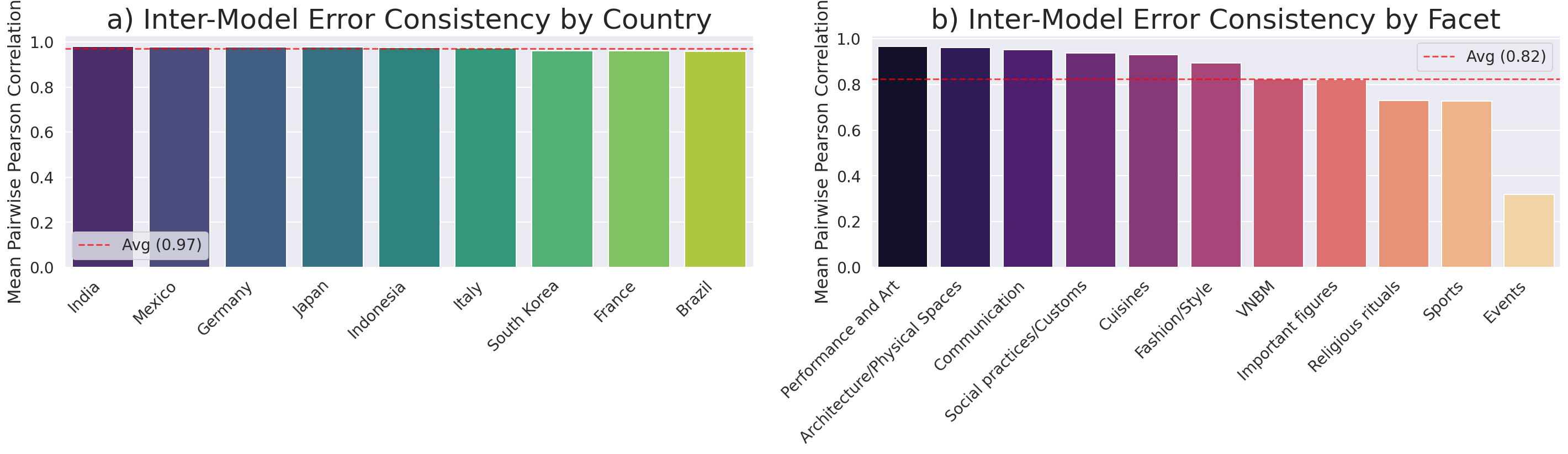
Figure 4: Inter-model error consistency; left shows correlation by country, right by facet. Consistency across models is uniformly high, especially at the country level.
Implications and Theoretical Context
The findings substantiate a touristic gaze effect in LLMs—models saturate responses with externally legible, "front stage" cultural markers while neglecting the nuanced, internally prioritized elements expressed by natives. This overgeneralization aligns with prior sociological and anthropological constructs (e.g., Urry’s "Tourist Gaze", Appadurai’s "Mediascapes"), underscoring the risk of algorithmic reinforcement of homogenized, outsider-centric cultural narratives.
Practically, this represents a significant limitation for LLM deployment in globalized, culturally sensitive contexts—LLMs may provide informationally rich yet inauthentic responses, perpetuating Western-centric priorities and potentially occluding local representational agency. The systemic and model-agnostic nature of these errors highlights the need for interventions that transcend architecture: diversification of pretraining corpora, explicit coupling with human importance signals, and dynamic adaptation to local user feedback.
Future Directions
Future model evaluation frameworks must shift toward user-priority-aware alignment, departing from surface-level coverage metrics. Key development angles include:
- Incorporation of interactive or reinforcement learning grounded in native user feedback.
- Stratified pretraining or fine-tuning on corpus slices curated for authentic, local salience.
- Real-time recalibration or re-ranking of outputs based on user context and evolving human baselines.
The approach outlined in this work offers a scalable blueprint for evaluating and ultimately enhancing the authenticity of LLM cultural representations, moving the field closer to truly user-aligned generative AI.
Conclusion
This paper delivers a rigorous, dual-study framework for quantifying LLM cultural authenticity at the intersection of anthropology, NLP, and evaluation science (2604.03493). By grounding comparative analysis in the authentic priorities of native populations, the work exposes systemic, Western-centric misalignment in current frontier models, with error patterns consistent across model families and countries. The results emphasize the need for human-centered, priority-sensitive evaluative paradigms as a prerequisite for equitable and authentic representation in global language technologies.