- The paper introduces vocabulary dropout as a novel mechanism to preserve proposer diversity in co-evolutionary LLM training.
- It employs dynamic token masking during both training and generation to prevent mode collapse and enhance curriculum quality.
- Empirical results demonstrate improved solver performance with tuned dropout rates, underscoring the balance between masking strength and model capacity.
Vocabulary Dropout for Curriculum Diversity in LLM Co-Evolution
Co-evolutionary self-play in LLMs employs a two-agent framework—one model (proposer) generates reasoning problems, another (solver) attempts to solve them. The paradigm aims to produce autonomous curriculum learning, analogously to self-play in games where structural constraints (e.g., legal actions, fixed dynamics) guide agent behavior. However, the lack of symbolic verifiability in natural language tasks induces a fundamental vulnerability: the proposer rapidly collapses to a narrow set of templates that optimize the reward, leading to superficial diversity and stagnation of curriculum informativeness. This collapse is not adequately detected by standard diversity metrics, and reward-side diversity pressure (such as BLEU repetition penalties) fails to prevent functional collapse.
Classical game environments solve this by action-space constraints, preventing mode collapse and ensuring non-trivial opponent policies. In language, the output space is the vocabulary; but unlike games, there are no “hard” rules enforcing diverse actions. Therefore, constraining the proposer's token distribution directly—rather than just modifying reward structure—is hypothesized to be critical for sustaining diversity and maintaining a productive co-evolution loop.
Methodology
Vocabulary Dropout Mechanism
Vocabulary dropout (VD) is introduced as a lightweight, non-stationary action-space constraint. Given vocabulary V and a protected subset F for format-critical tokens, a retention probability α is set. For each batch, a mask m(b) is sampled:
mv(b)∼{Bernoulli(α)v∈/F 1v∈F
Logits for masked tokens are set to −∞, restricting sampling to the surviving set and thus dynamically varying the effective action space. The mask is applied both during training (policy optimization via GRPO) and curriculum generation, ensuring the proposer cannot gradually concentrate output probability on fixed sequences. This intervention is decoupled from optimization pressure and forces exploration across broader regions of token compositions.
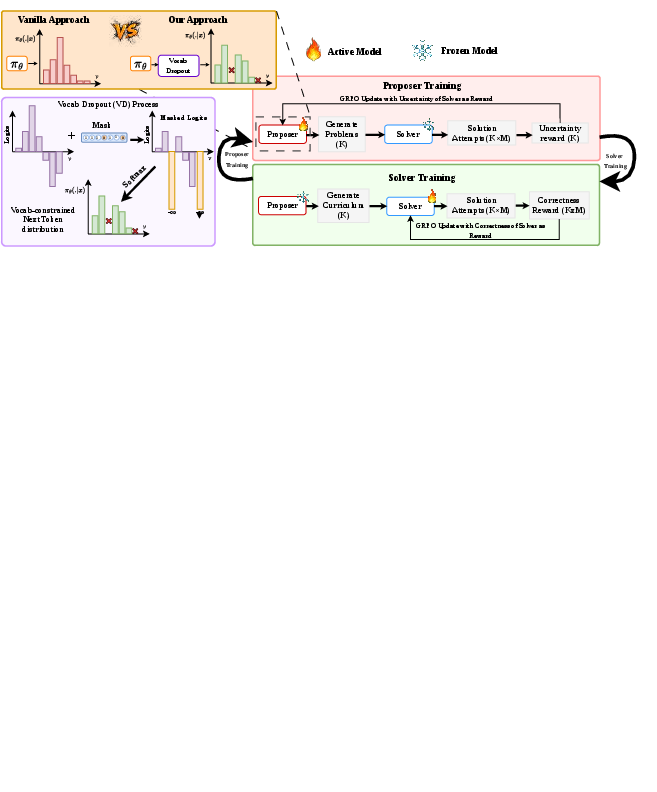
Figure 1: The proposer’s output vocabulary is randomly masked per batch to enforce action-space diversity, with a co-evolution loop alternating proposer and solver updates.
Co-Evolutionary Training
R-Zero serves as the experimental framework, rewarding proposers based on solver uncertainty (self-consistency across multiple solution attempts), and solvers by accuracy on generated problems filtered for intermediate difficulty. Qwen3-4B and Qwen3-8B models are used, both initialized from the same base checkpoint. GRPO policy gradients are alternated in proposer and solver phases, with vocabulary dropout ablated for both phases and varying strengths (α∈{0.75,0.85,1.0}).
Curriculum diversity is evaluated using lexical (Self-BLEU), semantic (Vendi score, novelty rate), and functional (epiplexity) metrics, as well as structural measures (unique tokens, solution complexity).
Empirical Results
Diversity Collapse Analysis
Baseline (no VD) converges within 1–2 iterations to problems near the solver’s boundary, which remain repetitive and superficial despite appearing diverse on lexical metrics. Early collapse is visible in policy entropy, Vendi score, and epiplexity measures, while surface-level metrics suggest stability. Diversity interventions applied after the first iteration are ineffective.
Vocabulary Dropout Effects
VD sustains proposer diversity across all granularities: Self-BLEU halves, Vendi score increases (∼15 effective types), novelty rate doubles, and epiplexity rises by over 35%. Structural metrics reveal that VD enforces broader vocabulary utilization (36–52% increase in unique tokens) and yields longer, structurally more complex questions, despite fewer tokens available per batch.
Solver performance improves with VD, especially in higher-capacity models. At 8B, VD75 provides +4.4 points average improvement on competition benchmarks; at 4B, the milder VD85 mask outperforms baseline, but VD75 can hurt performance due to excessive constraint. Phase ablations confirm that gen-only masks contribute most to diversity, but only the combination (train+gen) yields sustained growth.
Figure 1: Vocabulary dropout pipeline and diversity dynamics in the proposer-solver co-evolution loop.
Figure 1: Six diversity and curriculum quality metrics across co-evolution iterations, highlighting early stagnation and the effect of vocabulary dropout.
Curriculum Quality and Diversity
Diversity alone is not sufficient—masking strength must be calibrated to model capacity. Overly aggressive masking (VD75 at 4B) produces incoherent or malformed problems, degrading solver training. At 8B, higher redundancy in token representations allows stronger VD without sacrificing output quality.
Verification Limitations
Self-consistency verification rewards solver disagreement, inadvertently incentivizing ill-posed problems. Proposer answer correctness degrades sharply after the first iteration in all settings, with VD increasing variance. However, diversity gains in “well-posed” portions of the curriculum are sufficient to improve solver performance when capacity is matched.
Figure 1: Question complexity and token-level utilization under VD versus baseline.
Implications and Extensions
Explicit action-space constraints analogous to game rules are shown to be necessary for productive co-evolution in LLMs. VD is a simple, effective instantiation—requiring no reward engineering or auxiliary supervision. It generalizes previous action-space randomization practices from RL in games to language modeling.
The approach is complementary to reward-side interventions (entropy regularization, diversity-promoting rewards, population-based training), directly shaping the search space and preventing mode collapse. Its non-stationarity ensures continual exploration and prevents lock-in to high-reward but degenerate templates.
Future directions include adaptive masking schedules (annealing α with model scale or training progression), stronger external verification in reward assignment (e.g., symbolic solvers or code execution), and extending VD to non-mathematical domains for general reasoning curriculum.
Conclusion
Vocabulary dropout is an effective action-space constraint for sustaining curriculum diversity and enhancing solver capability in LLM co-evolutionary training. It prevents functional collapse, enables informative self-play curricula, and is robust across lexical, semantic, and functional diversity metrics. Proper calibration of masking strength relative to model capacity is required; the mechanism is most effective with capacity-matched proposer and solver models initialized from base checkpoints. Extensions toward adaptive masking and stronger verification can further leverage the diversity benefit, potentially generalizing to broader reasoning domains.