- The paper proposes an implicit BA that fuses geometric and temporal consistency into feature learning for robust visual matching.
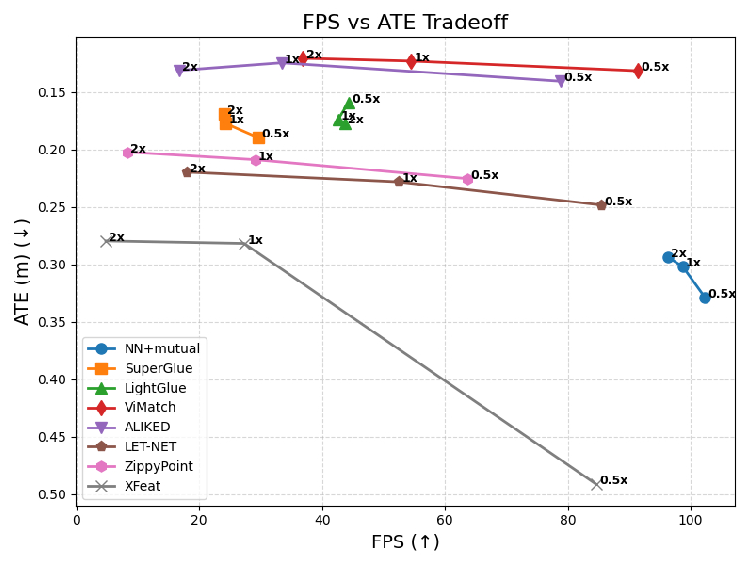
- It demonstrates significant reductions in error metrics, achieving up to 18% lower translation error and real-time performance at 36–91 FPS.
- The approach generalizes well across datasets, maintaining over 90% localization accuracy in diverse, real-world conditions.
Implicit Bundle Adjustment with Geometric and Temporal Consistency for Robust Visual Matching
Motivation and Problem Statement
Feature-based visual odometry (VO) and visual-inertial odometry (VIO) are foundational for robotic state estimation, relying on accurate inter-frame feature correspondences. Traditional methods predominantly depend on fixed, heuristic detectors and descriptors, limiting adaptability to variable scene conditions and often being decoupled from the downstream geometric optimization process. Recent deep learning methods improve local feature representation but are typically trained with surrogate objectives that are only loosely related to system-level geometric consistency. This disconnect compromises long-term stability and generalization, especially in unconstrained, real-world environments.
ViBA ("Implicit Bundle Adjustment with Geometric and Temporal Consistency for Robust Visual Matching" (2604.03377)) addresses these challenges by integrating implicitly differentiable global bundle adjustment (BA) and multi-frame temporal consistency directly into the feature learning pipeline. This design enables self-supervised, continuous online training on unconstrained video streams, thus tightly aligning learned features with downstream VO/VIO objectives.
Method Overview
ViBA's architecture embeds geometric optimization directly within feature learning, enforcing both spatial geometric consistency and temporal coherence. The pipeline consists of feature extraction, feature tracking, geometric initialization, and implicitly differentiable BA. During online operation, residuals from the global BA module are backpropagated to the feature networks, producing features optimized for long-term geometric reliability.
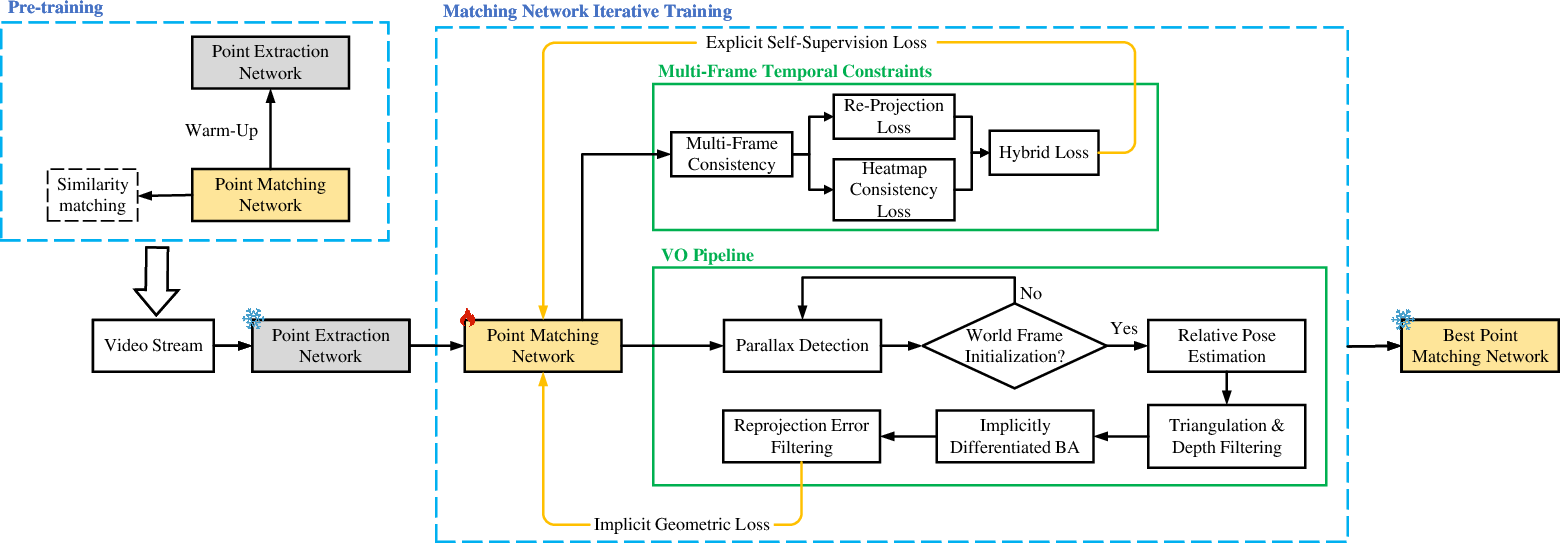
Figure 1: ViBA pipeline integrating feature extraction, tracking, depth-based filtering, and implicit bundle adjustment; snowflakes denote frozen networks, flames indicate activated networks, and sparks mark transition points.
Feature Extraction and Matching
Feature extraction is handled by a fully convolutional network producing dense response maps. High-confidence keypoints are selected for tracking, with corresponding image patches fed into a point matching network. This network utilizes shared encoders and residual units to compute discriminative, stable descriptors, enforcing bidirectional similarity and differentiable keypoint detection.
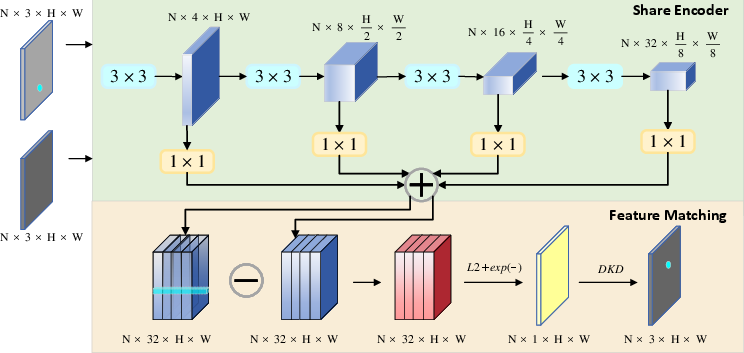
Figure 2: Point matching network architecture with shared encoder and feature matching module, highlighting residual unit configurations.
Feature Tracking and Geometric Initialization
The feature tracking network predicts correspondences across frames, initializing multi-frame feature tracks. These tracks are filtered for depth-based outlier removal and used to recover initial camera motion and scene structure via triangulation and pose estimation.
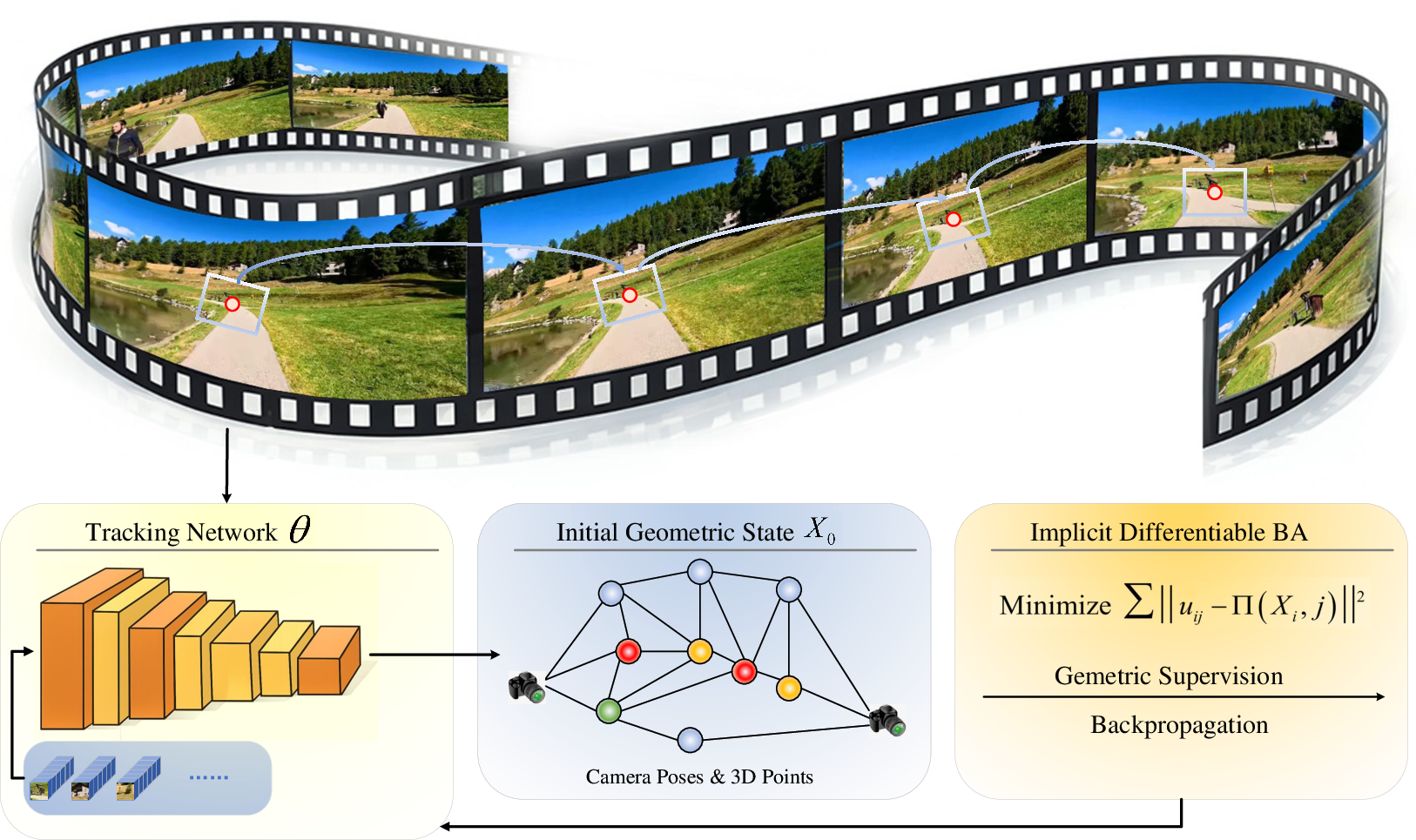
Figure 3: Feature tracking and geometric initialization pipeline, detailing the formation of multi-frame tracks and initial geometric state estimation.
Implicit Differentiable Bundle Adjustment
Traditional BA involves iterative nonlinear least-squares optimization of camera poses and 3D landmarks based on reprojection residuals. ViBA reformulates BA as an implicitly differentiable optimization layer. Gradients from the converged geometric solution are computed and propagated via implicit differentiation, avoiding unrolled solver trajectories and reducing memory overhead. This integration allows end-to-end optimization of both feature representations and geometric states directly with respect to the true VO/VIO objectives.
Multi-frame Temporal Consistency
ViBA introduces temporal supervision at trajectory and descriptor levels. Feature tracks are regularized by comparing recursive, frame-to-frame propagation with direct, long-baseline estimates. Descriptor-level consistency aligns local similarity responses across frames, further constrained to be unimodal with Gaussian targets centered at predicted correspondences. These multi-level constraints are incorporated into the overall optimization energy, yielding a spatiotemporal training objective.
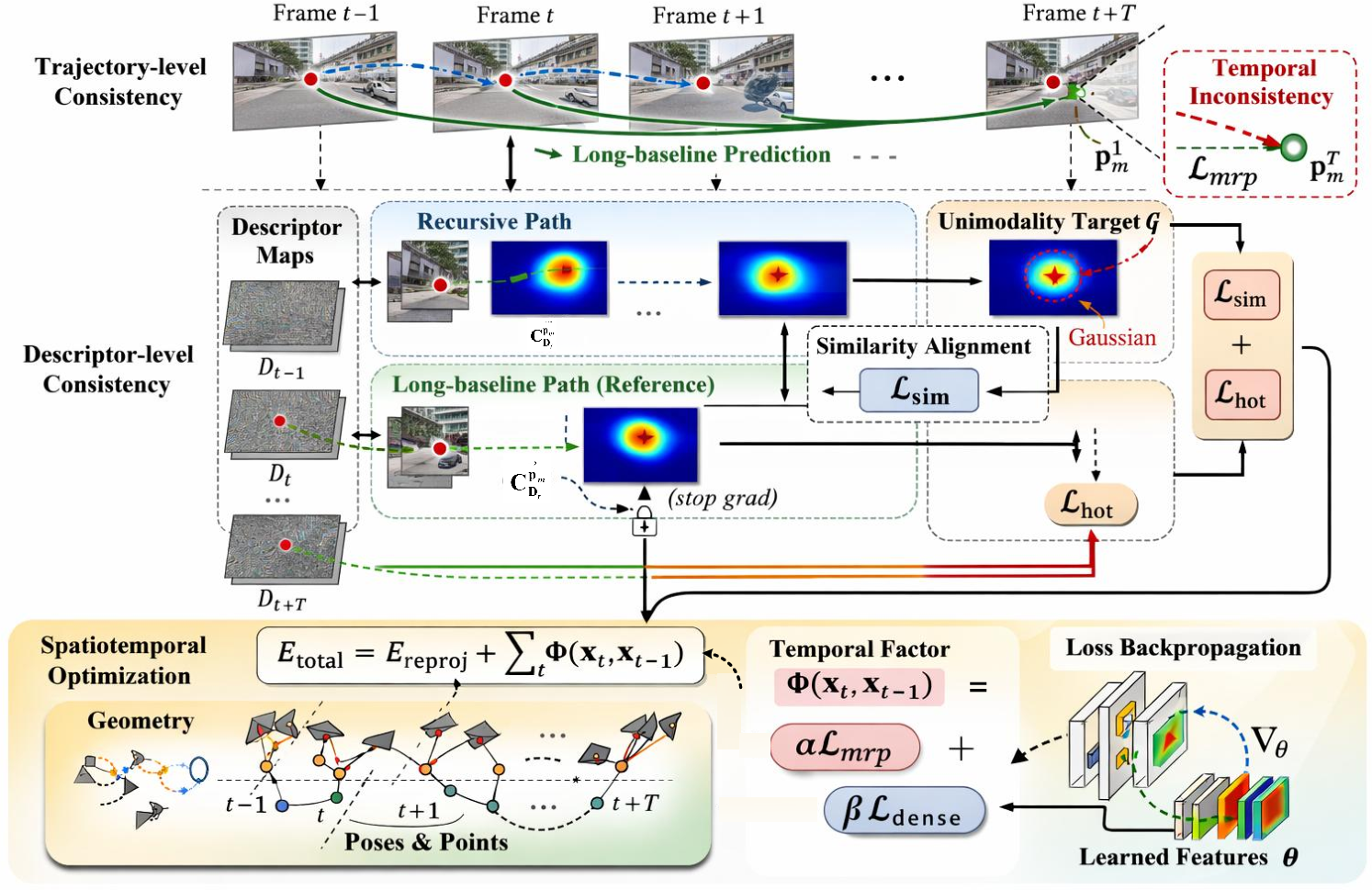
Figure 4: Overall training loss pipeline integrating differentiable bundle adjustment and multi-frame temporal consistency for robust feature learning.
Geometric Initialization Process
A robust geometric initialization is essential for stable optimization. ViBA selects anchor and terminal frames based on co-visibility, parallax, and reprojection error criteria. Relative pose is estimated via five-point algorithm and RANSAC, followed by triangulation and Bayesian inverse depth updates for 3D points. Remaining frames are initialized through PnP, with sliding window refinement maintaining geometric coherence.
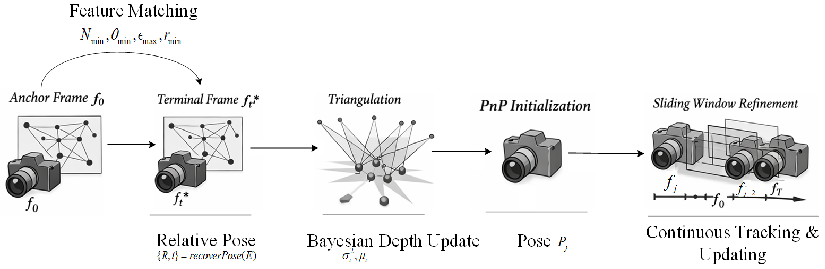
Figure 5: Geometric initialization process including anchor/terminal selection, triangulation, inverse depth update, PnP initialization, and sliding window refinement.
Experimental Results
ViBA was evaluated on homography estimation (HPatches), indoor pose estimation (7-Scenes), and VIO trajectory estimation (EuRoC, UMA). The method achieves significant reductions in mean absolute translation error (ATE) and absolute rotation error (ARE) compared to state-of-the-art matchers:
ViBA also demonstrates strong generalization to unseen sequences, retaining over 90% localization accuracy, in contrast to degradation observed in dataset-specific end-to-end models.
Implications and Future Directions
ViBA's hybrid consistency-driven paradigm paves the way for robust, scalable feature learning in real-world visual perception systems. By tightly coupling feature representation with multi-view geometric constraints and temporal continuity, it significantly reduces mismatches, stabilizes long-term correspondences, and enables self-supervised adaptation without explicit annotation or pose supervision.
Directions for future development include:
- Incorporating long-range global constraints for scene-level consistency.
- Extending the formulation to simultaneously optimize dense and sparse features in multi-camera/multi-modal systems.
- Investigating further integration with differentiable physics and generative models for holistic robotic perception.
Conclusion
ViBA presents a unified framework for geometry-aware feature learning, coupling implicitly differentiable bundle adjustment with multi-frame temporal consistency. The empirical results establish its superiority in accuracy, robustness, and efficiency across a wide spectrum of VO/VIO tasks. By directly enforcing geometric and temporal constraints at the feature learning level, ViBA achieves sustainable, self-supervised, online adaptation in unconstrained environments, establishing a new standard for robust visual matching in real-world navigation and localization.