- The paper introduces DKPMV, a framework that densely fuses multi-view RGB keypoints for robust 6D pose estimation of textureless objects.
- It employs symmetry-aware training and attentional aggregation to enhance keypoint localization and outperform RGB-D methods in challenging industrial scenarios.
- The three-stage optimization pipeline progressively refines pose estimates through RANSAC, triangulation, and nonlinear optimization, significantly boosting precision.
DKPMV: Dense Keypoints Fusion from Multi-View RGB Frames for 6D Pose Estimation of Textureless Objects
Introduction and Motivation
The DKPMV framework addresses the persistent challenge of 6D pose estimation for textureless objects in industrial robotics, where depth sensors are often unreliable due to specular, transparent, or low-light conditions. Existing multi-view methods either depend on depth data or insufficiently exploit multi-view geometric cues, resulting in suboptimal performance, especially for symmetric or occluded objects. DKPMV introduces a dense keypoint-level fusion pipeline that operates solely on multi-view RGB images, leveraging geometric consistency across views to achieve robust and accurate pose estimation.
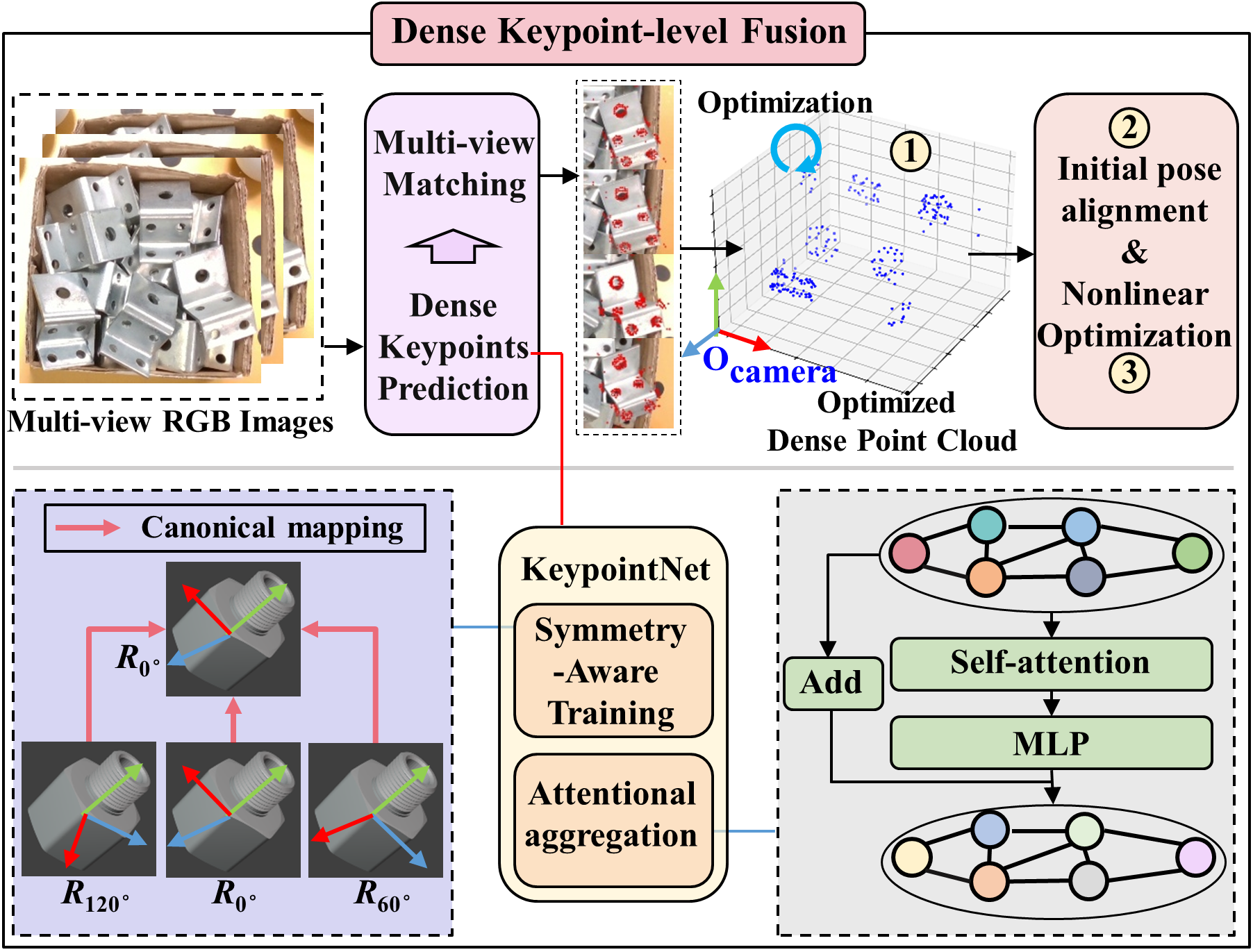
Figure 1: DKPMV pipeline overview, illustrating dense keypoint-level multi-view fusion and progressive pose optimization.
Methodology
Dense Keypoint Prediction and Fusion
DKPMV samples N 3D keypoints from each object's CAD model using farthest point sampling. For each RGB view, object detection is performed via YOLOv11, followed by cropping and resizing. The KeypointNet-SAT network, built upon CheckerPose, predicts dense 2D keypoints and visibility codes. The network incorporates a GNN for geometric relations and a CNN for visual features. To resolve ambiguities in symmetric objects, DKPMV employs symmetry-aware training (SAT), mapping all symmetric-equivalent poses to a canonical form, thus ensuring consistent keypoint supervision.
Attentional aggregation (Att) replaces the max-based node update in EdgeConv, enabling each keypoint to aggregate features from its k nearest neighbors via a softmax-weighted sum, inspired by SuperGlue. This mechanism enhances geometric modeling and keypoint localization accuracy.
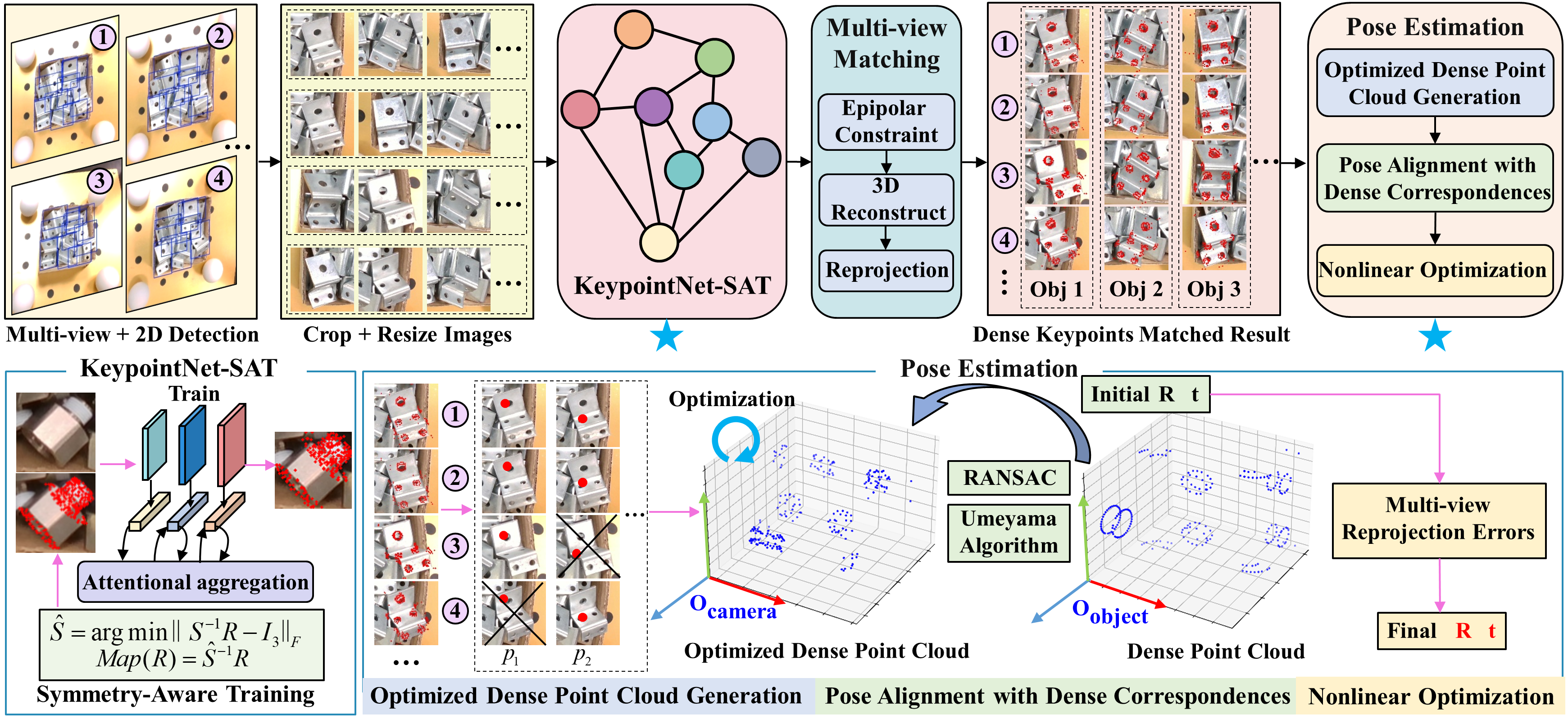
Figure 2: The detected keypoints are matched across views and subsequently fed into a three-stage progressive pose estimation module.
Multi-View Keypoint Matching
Keypoint correspondences across views are established using epipolar constraints and mutual nearest neighbor matching, leveraging the Sampson distance for semantic alignment. Triangulation and reprojection are used to refine matches, ensuring robust association even in cluttered or occluded scenes.

Figure 3: Multi-view keypoint matching results, demonstrating robustness to occlusion and clutter.
Three-Stage Progressive Pose Optimization
Pose estimation proceeds in three stages:
- Optimized Dense Point Cloud Generation: RANSAC is used to select inlier keypoints across views, followed by SVD-based multi-view triangulation for globally optimal 3D keypoint reconstruction.
- Pose Alignment with Dense Correspondence: The reconstructed point cloud is aligned to the CAD model keypoints using the Umeyama algorithm, with RANSAC for outlier rejection.
- Nonlinear Optimization (NO): The initial pose is refined via global nonlinear optimization, minimizing reprojection error with a robust loss function.
This pipeline fully exploits multi-view geometric constraints and dense keypoint information, yielding high-precision pose estimates.
Experimental Results
Benchmarking on ROBI Dataset
DKPMV is evaluated on the ROBI dataset, which contains multi-view RGB images and ground-truth 6D poses for seven textureless industrial objects. The method is compared against state-of-the-art RGB and RGB-D approaches, including CosyPose, MV-3D-KP, and Jun's method, under both 4-view and 8-view settings.
DKPMV achieves the highest average recall (AR) on the Ensenso test set with 4 views (93.0% ADD, 88.7% (5mm,10∘)), outperforming RGB-D-based MV-3D-KP. With 8 views, DKPMV remains competitive, only marginally trailing MV-3D-KP, which benefits from high-quality depth. On the RealSense test set, where depth quality degrades, DKPMV significantly outperforms all RGB-D methods, with a 16.4% and 16.8% margin under the strict (5mm,10∘) metric for 4 and 8 views, respectively.
Ablation Studies
Ablation experiments demonstrate the impact of SAT, attentional aggregation, keypoint density, and pose estimation strategy:
- SAT: Incorporating SAT yields substantial improvements, especially as keypoint density increases (up to 50.3% gain at 512 keypoints under (2mm,3∘)).
- Attentional Aggregation: Att node update improves pose accuracy by 2.8–3.6% under strict metrics, enhancing geometric consistency.
- Keypoint Density: Increasing keypoint count improves accuracy and runtime stability, with diminishing returns beyond 256 points.
- Pose Estimation Method: The three-stage pipeline outperforms minimal three-point solvers, with 29.7% and 42.3% gains under strict metrics for 4 and 8 views, respectively.

Figure 4: SAT strategy produces structured keypoint distributions, improving multi-view fusion.
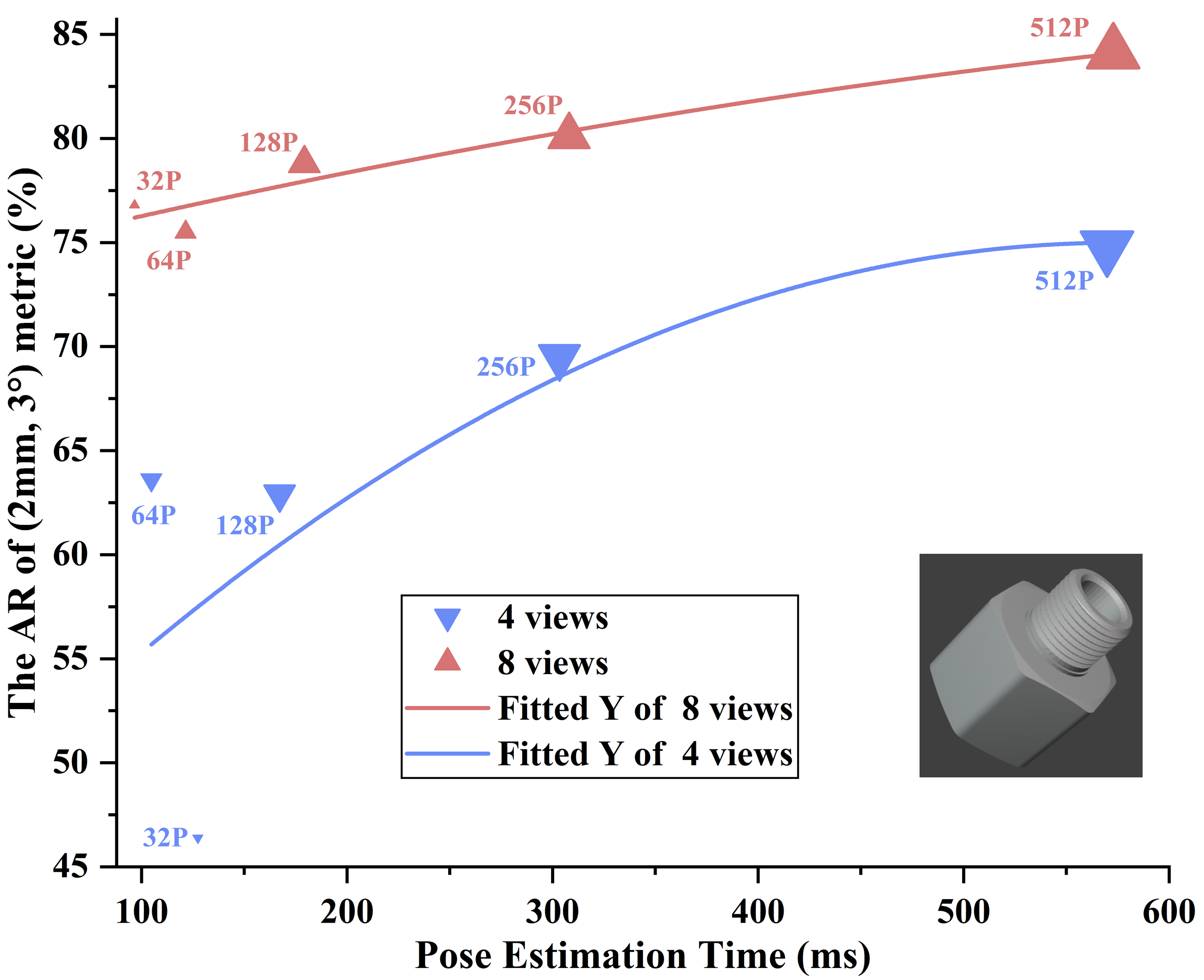
Figure 5: Pose accuracy and runtime as a function of keypoint density, highlighting the trade-off between precision and computational cost.

Figure 6: Qualitative pose estimation results comparing DKPMV and Min3P, illustrating superior accuracy and robustness of DKPMV.

Figure 7: SAT strategy impact on dense keypoint prediction distributions across objects.

Figure 8: Attentional aggregation effect on local keypoint localization for various objects.

Figure 9: Pose estimation accuracy comparison between DKPMV and Min3P as the number of views increases.
Implementation Considerations
DKPMV is designed for real-time robotic perception, with efficient multi-view processing and dense keypoint fusion. The method requires known camera poses and CAD models, and is robust to occlusion, symmetry, and degraded depth conditions. The primary computational bottleneck is keypoint prediction and multi-view matching, which scale linearly with the number of keypoints and views. The three-stage optimization pipeline is parallelizable and amenable to GPU acceleration.
Implications and Future Directions
DKPMV demonstrates that dense keypoint-level multi-view fusion from RGB images can surpass RGB-D methods in challenging industrial scenarios, especially when depth data is unreliable. The approach is highly interpretable, geometry-aware, and robust to occlusion and symmetry. Future research should focus on modeling keypoint uncertainty, integrating probabilistic fusion, and extending the framework to dynamic scenes and deformable objects. The method's reliance on known camera poses and CAD models may be relaxed via self-supervised or SLAM-based approaches, further broadening its applicability.
Conclusion
DKPMV establishes a new state-of-the-art for 6D pose estimation of textureless objects using multi-view RGB images, outperforming both RGB and RGB-D methods in most scenarios. Its dense keypoint fusion, symmetry-aware training, and progressive optimization pipeline collectively enable robust, accurate, and efficient pose estimation suitable for real-world industrial robotics. Future work will enhance uncertainty modeling and extend the framework to more complex object categories and environments.

