- The paper demonstrates emergent compositional communication by enabling agents to encode unobservable physical properties through a discrete Gumbel-Softmax bottleneck.
- It compares DINOv2 and V-JEPA architectures, revealing that V-JEPA excels in dynamics-dependent scenarios due to video-native pretraining.
- The work validates its approach on real-world physics simulations, showing robust generalization and interpretable communication protocols.
Emergent Compositional Communication for Latent World Properties
Abstract and Introduction
The paper "Emergent Compositional Communication for Latent World Properties" (2604.03266) investigates the capacity of artificial agents to develop structured, discrete representations of unobservable physical properties under multi-agent communication pressure. Utilizing a Gumbel-Softmax bottleneck, agents endeavor to encode attributes such as elasticity, friction, and mass ratio from pretrained video features, extracting temporal dynamics invisible within any single observation.
Under controlled setups using DINOv2 and V-JEPA architectures, the work highlights the interplay of video-native pretraining and communication constraints in fostering compositional language-like protocols. Such emergent abstractions have implications for robotics, interpretable world modeling, and multi-agent coordination in settings demanding an understanding of latent physical components.
Experimental Setup
The research juxtaposes DINOv2 and V-JEPA architectures through factorial comparisons, demonstrating their respective propensities under physics simulations. DINOv2 excels in spatial physics, while V-JEPA outperforms in dynamics-dependent scenarios, attributing the difference to video-native pretraining strategies.
Agents interact with controlled physics simulations, observing balls with hidden physical attributes. Making pairwise comparisons, they compress these observations into discrete messages communicated through specific symbolic bottlenecks, investigating whether a message’s structure mirrors the latent properties of the world.
Results
Compositionality and Generalization: With optimal setup conditions—compatible perception backbones, iterative learning, and disentangled message positions—agent communications exhibit compositionality in over 54% of cases when using two agents, synchronizing fully when extended to larger agent pools (four agents achieving 100% compositionality). The emergent protocols demonstrate clear diagonal specialization, wherein distinct message positions align uniquely with specific properties (Figure 1).
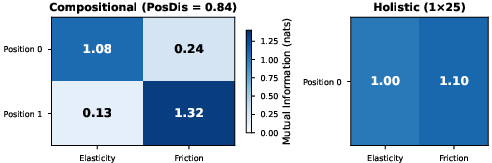
Figure 1: Mutual information between message positions and physical properties. Compositional agents (left) show clean diagonal specialization; holistic agents (right) encode both properties in a single undifferentiated symbol.
Backbone-Dependent Advantage: V-JEPA's prowess in motion-oriented collision dynamics highlights video-native gains, not replicated even by scale or frame-matched DINOv2, emphasizing pretraining influence over network capacity and input size (Figure 2).
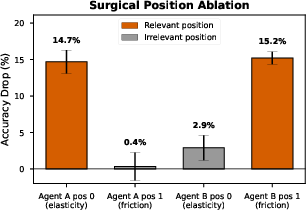
Figure 2: Causal intervention on message positions during cross-property reasoning. The receiver selectively reads elasticity from position 0 of message A (-14.7\%) and friction from position 1 of message B (-15.2\%), while irrelevant positions cause negligible drops.
Transfer and Real-World Validation: The robustness of the method on Physics101 validates real-world applicability. Utilizing real videos with tangible physics, agents show capacity to generalize learned compositional structures beyond controlled simulations, reaffirming the method’s practical relevance.
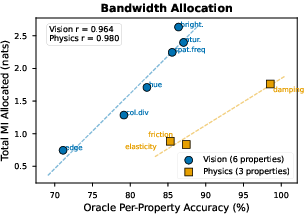
Figure 3: Agents allocate communication bandwidth proportional to property extractability across both vision (6 properties) and physics (3 properties) domains. Correlations are strong but based on small n and should be interpreted as suggestive of information-allocation principles.
Conclusion
This study offers nuanced insights into compositional communication for AI, delineating how multiple independent agents can align representations of unobservable physical phenomena via structured protocols, driven by pretraining dynamics and not by model scaling or simple baseline adjustments. Critically, such advancements engender a pathway to interpretable and communicative AI models, serving as a foundational step towards autonomous machine intelligence with intrinsic physical comprehension, aligning with JEPA foresights in cognitive architecture.
The implications of discrete, structured communication interfaces extend to aiding discernible and actionable decision-making processes for AI planning and task execution, fostering greater integration of intelligent systems within naturally dynamic environments.