- The paper introduces VLMo, leveraging a Mixture-of-Modality-Experts Transformer that unifies dual and fusion encoding for vision-language tasks.
- It adopts a stagewise pre-training strategy by first separately training vision and language experts before fine-tuning on image-text pairs.
- Empirical results show that VLMo outperforms traditional models in VQA, NLVR2, and image-text retrieval tasks, yielding enhanced efficiency and accuracy.
VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
Introduction
The paper introduces VLMo, a unified vision-language pre-trained model that employs a novel Mixture-of-Modality-Experts (MoME) Transformer architecture to handle both retrieval and classification tasks in vision-language domains. VLMo is designed to integrate dual encoder and fusion encoder functionalities into a single model, leveraging modality-specific experts to encode diverse input modalities. This approach enables efficient processing and improved interaction between image and text modalities, thus surpassing traditional architectures in various vision-language tasks.
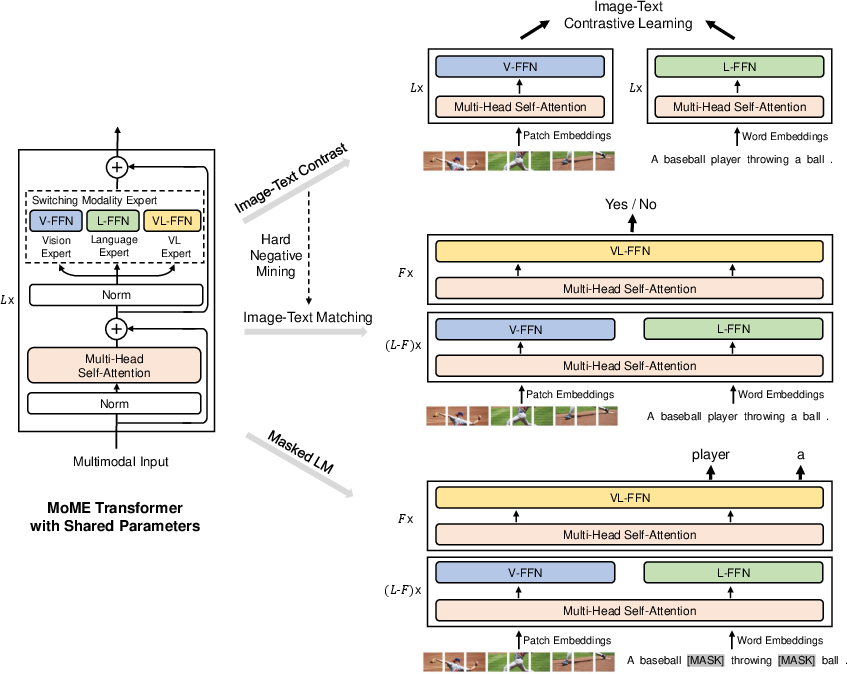
Figure 1: Overview of VLMo pre-training showing the Mixture-of-Modality-Experts (MoME) Transformer architecture.
The core innovation in VLMo is the Mixture-of-Modality-Experts Transformer, which diverges from the conventional use of separate networks for different modalities. Each block within the MoME Transformer comprises a shared self-attention layer and a pool of experts specific to each modality, including vision, language, and vision-language. This architecture allows VLMo to switch between modality experts based on input data type, ensuring modality-specific information is captured effectively. The shared self-attention component aligns visual and linguistic information, facilitating richer cross-modal interactions.
Pre-Training Strategies
VLMo is pre-trained using a stagewise approach to maximize data utilization's effectiveness. Initially, vision and language experts are pre-trained separately using large-scale image-only and text-only datasets, respectively. Subsequently, image-text pairs refine the alignment between modalities. This strategy enhances VLMo's ability to generalize across various datasets and tasks, yielding superior performance metrics.
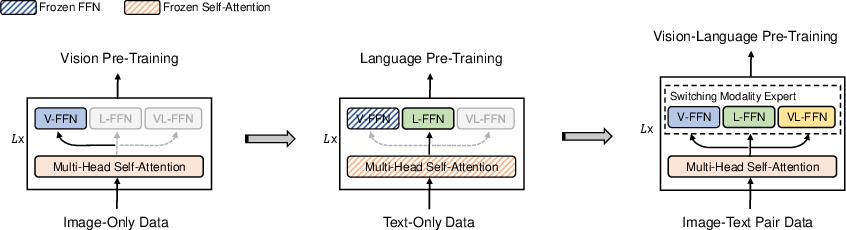
Figure 2: Stagewise pre-training using image-only and text-only corpora.
Fine-Tuning and Task Adaptability
The model's flexibility is emphasized through its ability to function as either a dual encoder or a fusion encoder. For tasks like visual question answering (VQA) and natural language for visual reasoning (NLVR2), VLMo employs a fusion encoder to model deep interactions between modalities. Conversely, for retrieval tasks, such as image retrieval or text retrieval, VLMo utilizes a dual encoder approach allowing efficient computation and storage of feature vectors, which significantly enhances inference speed.
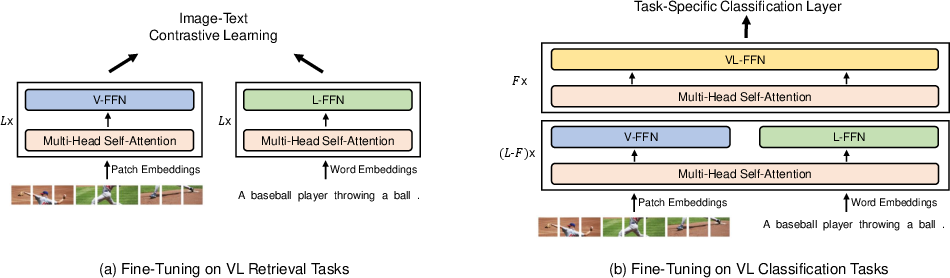
Figure 3: Fine-tuning VLMo on vision-language retrieval and classification tasks.
Experimental Results
Empirical evaluations demonstrate that VLMo achieves state-of-the-art results across several benchmarks, including VQA, NLVR2, and image-text retrieval tasks. Notably, VLMo's ability to operate seamlessly between dual and fusion encoding modes enables it to outperform models that are restricted to a single modality processing type. This is evidenced through enhanced accuracy rates and faster processing times, particularly in retrieval tasks where VLMo negates the need for combined encoding of all image-text pairs.
Conclusion
VLMo represents a significant advancement in unified vision-language modeling by integrating the advantages of both dual and fusion encoder designs. The MoME Transformer framework effectively resolves the limitations inherent in previous architectures, and the staged pre-training approach ensures robust generalization. Future research directions include scaling the model to accommodate larger datasets and further extending its applicability to other multimodal tasks, such as image or text generation. This work provides a foundational shift in efficiently managing diverse modalities within a single architecture, paving the way for more integrated vision-language systems.