Reflective Context Learning: Studying the Optimization Primitives of Context Space
Abstract: Generally capable agents must learn from experience in ways that generalize across tasks and environments. The fundamental problems of learning, including credit assignment, overfitting, forgetting, local optima, and high-variance learning signals, persist whether the learned object lies in parameter space or context space. While these challenges are well understood in classical machine learning optimization, they remain underexplored in context space, leading current methods to be fragmented and ad hoc. We present Reflective Context Learning (RCL), a unified framework for agents that learn through repeated interaction, reflection on behavior and failure modes, and iterative updates to context. In RCL, reflection converts trajectories and current context into a directional update signal analogous to gradients, while mutation applies that signal to improve future behavior in context space. We recast recent context-optimization approaches as instances of this shared learning problem and systematically extend them with classical optimization primitives, including batching, improved credit-assignment signal, auxiliary losses, failure replay, and grouped rollouts for variance reduction. On AppWorld, BrowseComp+, and RewardBench2, these primitives improve over strong baselines, with their relative importance shifting across task regimes. We further analyze robustness to initialization, the effects of batch size, sampling and curriculum strategy, optimizer-state variants, and the impact of allocating stronger or weaker models to different optimization components. Our results suggest that learning through context updates should be treated not as a set of isolated algorithms, but as an optimization problem whose mechanisms can be studied systematically and improved through transferable principles.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about teaching AI assistants to get better over time without rewriting their “brains.” Instead of retraining the model’s internal weights (which is slow and risky), the authors show how to improve the AI by updating its “context” — the written instructions, rules, tips, tools, and memory the AI reads before acting. They call this Reflective Context Learning (RCL). Think of it like coaching a team by revising the playbook and game plan after each game, rather than replacing the players.
What questions did the researchers ask?
They focused on simple, practical questions:
- Can an AI learn from its own experiences by reflecting on what went well or badly and then updating its playbook (context)?
- What are the best “basic tricks” (they call them optimization primitives) to make this kind of learning stable and effective?
- Do tricks from classic machine learning (like using batches, momentum, and replay) also help when we’re updating context instead of model weights?
- Which tricks matter most for different kinds of tasks?
How did they study it?
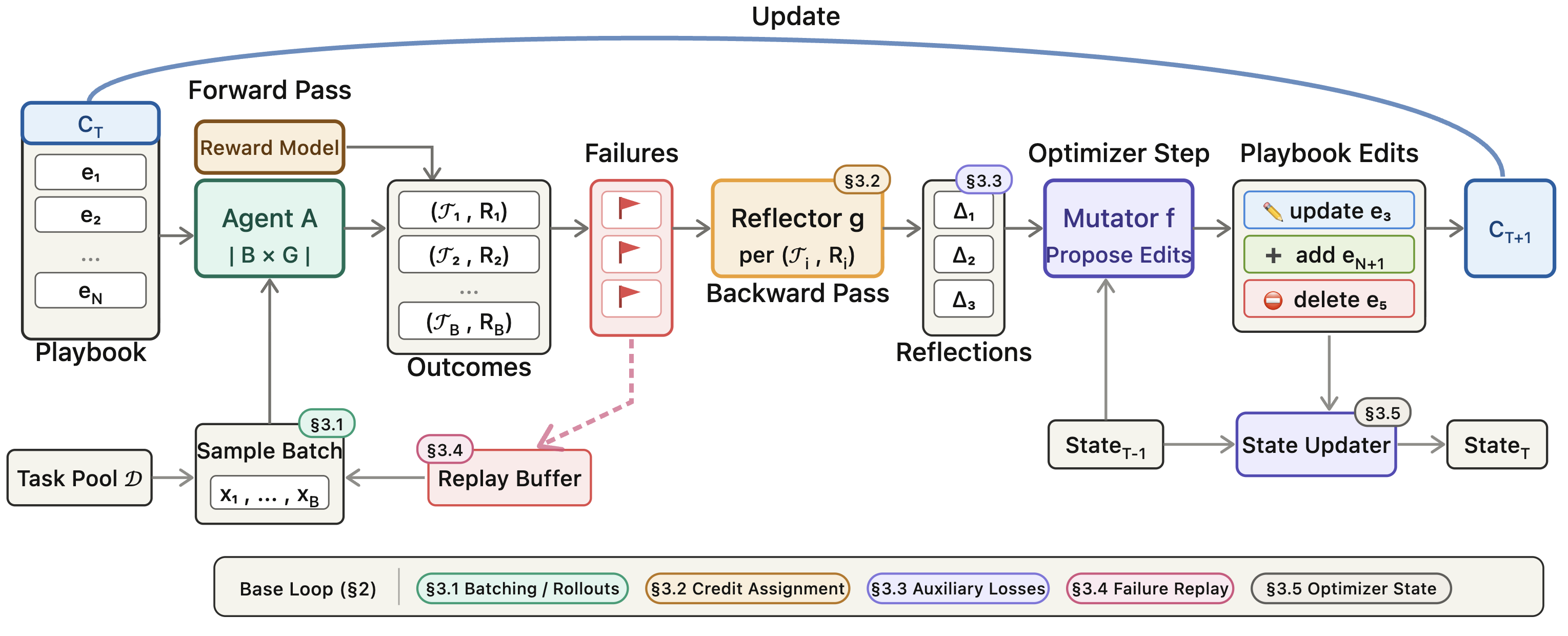
The authors built a loop that mirrors how we train models with gradients, but in plain language and with playbook edits instead of weight changes. You can picture it like this coach’s cycle:
- Try: The AI attempts some tasks using its current playbook (the “forward pass”).
- Reflect: A strong “reflector” model reads what happened, decides what went wrong and why, and writes a clear diagnosis (like a coach reviewing game footage).
- Update: A “mutator” model uses the diagnosis to make small, targeted edits to the playbook (like updating a rule or adding a tip).
To make this work well, they added several simple-but-powerful tricks. Here’s what each one means in everyday terms:
- Batching: Don’t change the playbook based on one odd failure. Look at a small set of tasks at once to spot patterns and avoid overreacting.
- Grouped rollouts: Try the same task a few times. Compare one successful try with a failed try to pinpoint the exact decision that made the difference.
- Better credit assignment: Run one “instrumented” version where the AI marks which rules it used and where it felt uncertain (like sticky notes in the margins). Use that to see which specific rule needs fixing.
- Auxiliary structure: Keep the playbook organized as separate entries (rules) and require reflections to answer specific questions (e.g., What type of failure? What root cause? What rule is missing?). This avoids messy, all-at-once rewrites.
- Failure replay: Keep a list of tough cases and bring them back in future practice until they’re truly solved. Remove cases that are either consistently solved or truly intractable so they don’t waste time.
- Optimizer state (momentum): Maintain a running “training diary” that records what changed and why, so you don’t flip-flop between decisions. This encourages steady progress.
They tested these ideas on three types of tasks:
- AppWorld: multi-step coding tasks (like following procedures).
- BrowseComp+: web research tasks (finding information on the web).
- RewardBench2: choosing better answers from a set (careful judging).
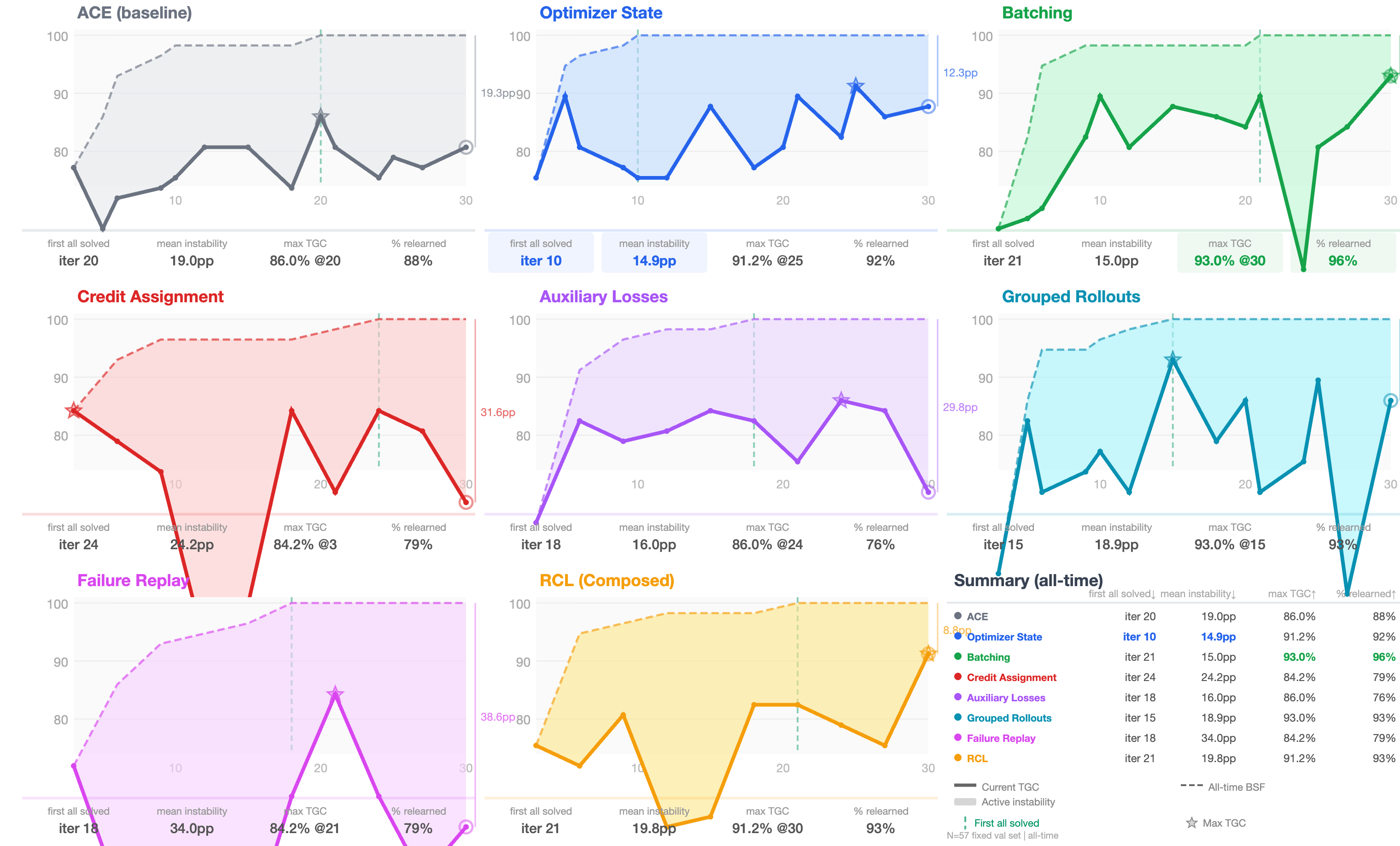
They compared a simple baseline loop (ACE), a search-based optimizer (GEPA), and versions of their loop with each trick turned on alone or all together.
What did they find, and why is it important?
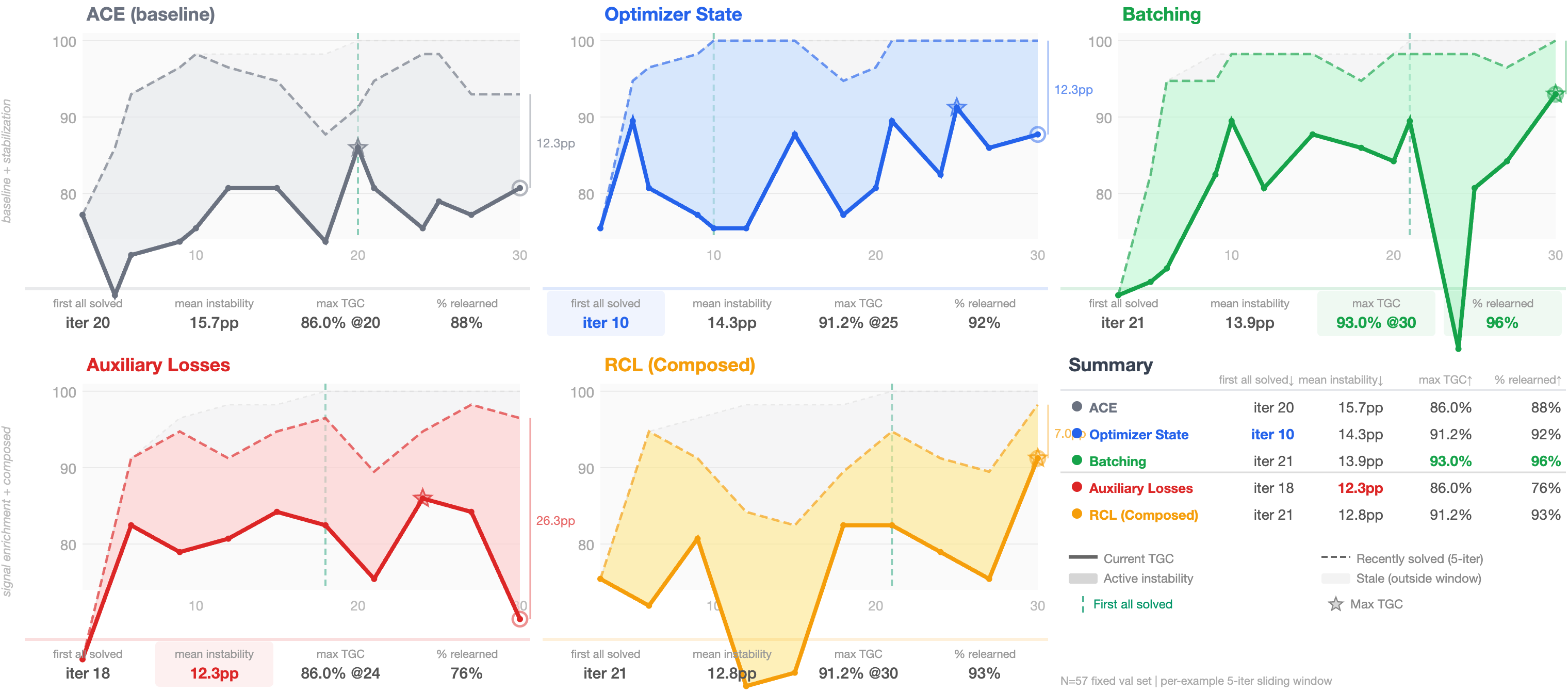
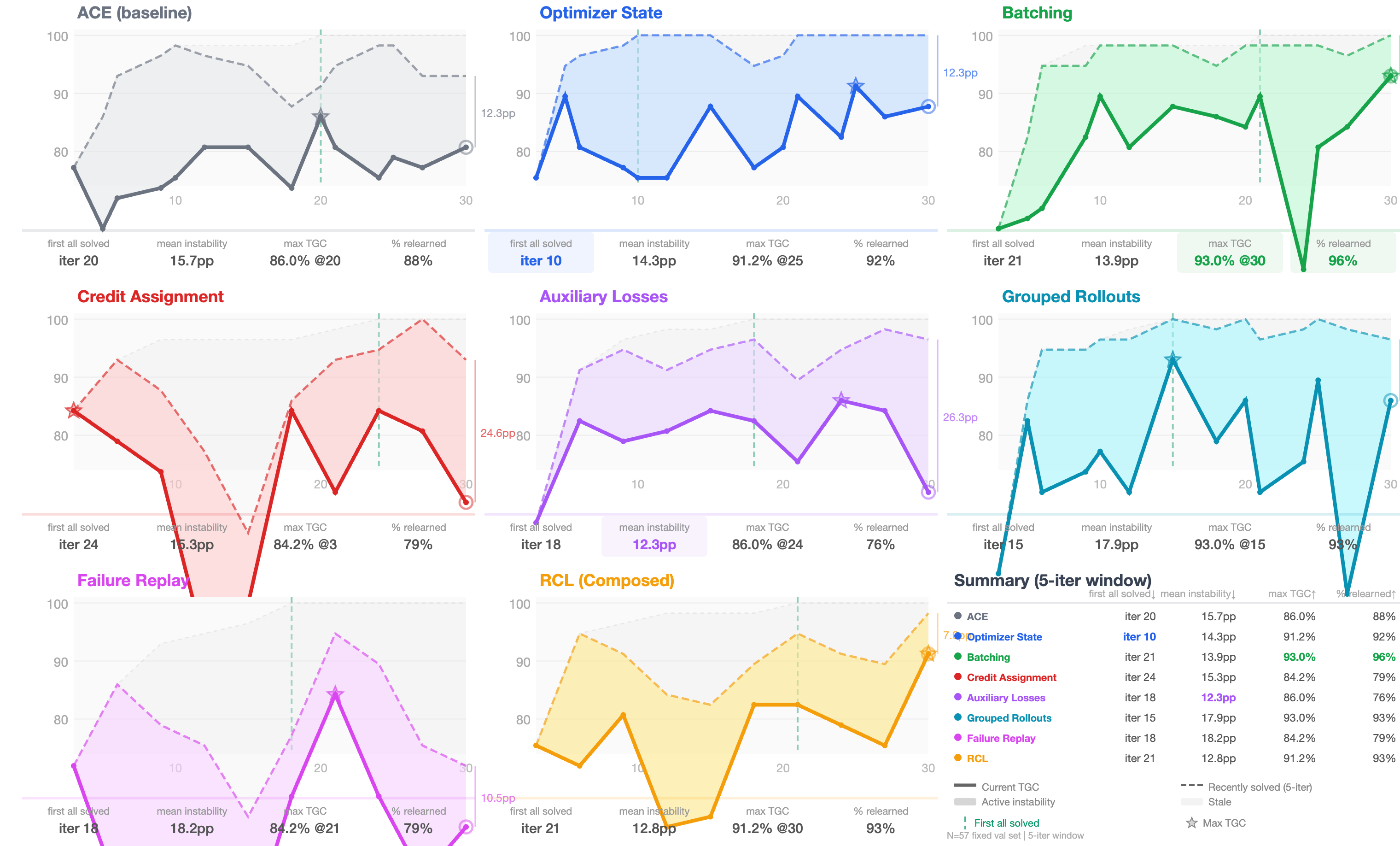
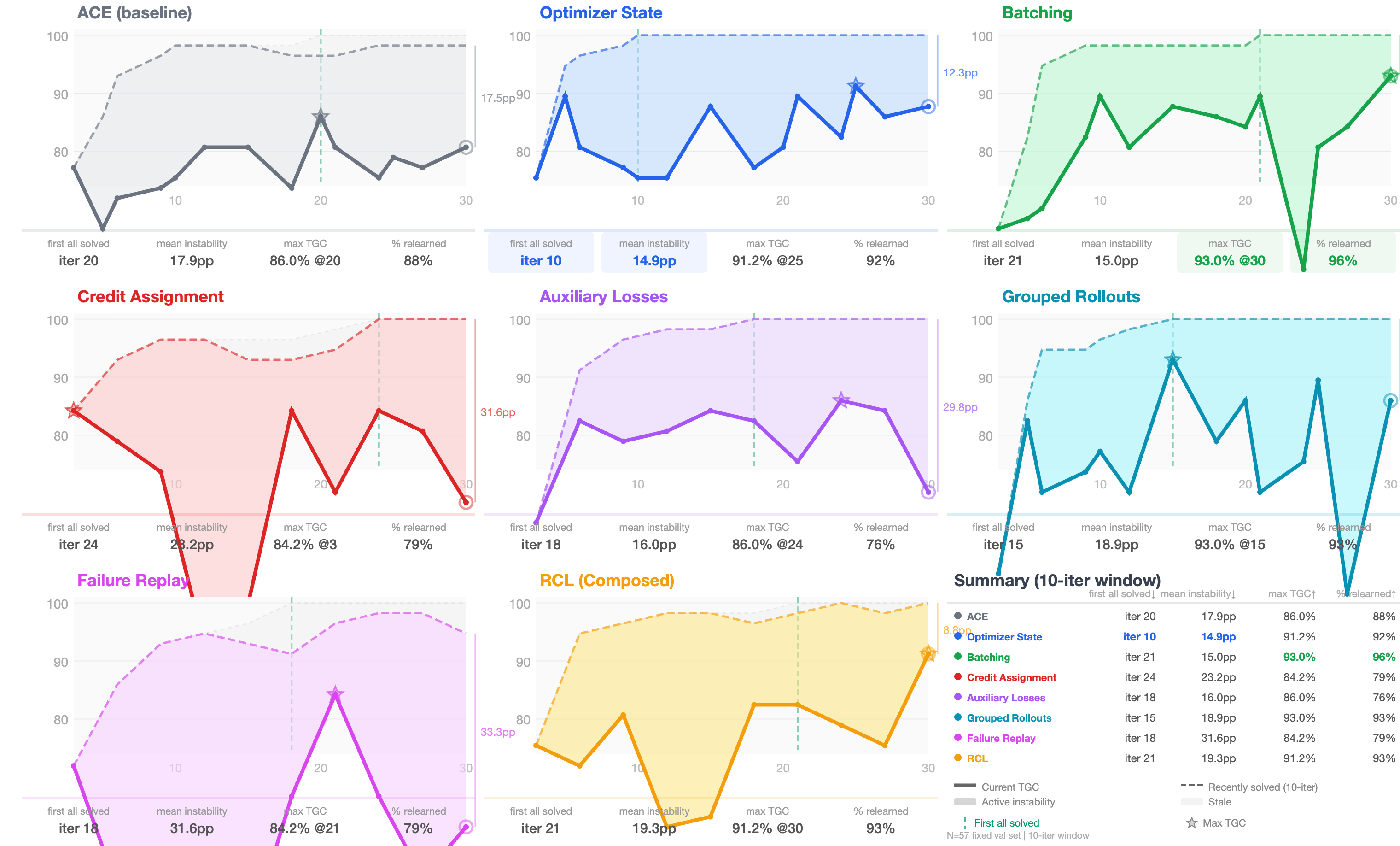
Overall, the RCL approach improved results, and the “classic” tricks from machine learning really helped when adapted to context updates. The most important takeaways:
- Reflection quality matters most: Keeping a running optimizer state (momentum) and using structured reflections (auxiliary heads and tidy playbooks) delivered consistent gains without needing to run more tasks. In other words, better thinking beats brute-force trying.
- Contrast helps a lot in judging tasks: Grouped rollouts (comparing a success and a failure on the same task) gave some of the biggest improvements, especially when tasks were near-deterministic (like ranking answers). Seeing “what worked” next to “what didn’t” makes the fix obvious.
- Batching helps—but not always: Looking at several tasks at once reduced noise and helped on some benchmarks. But when failures were very different from each other, batching sometimes confused the mutator and slowed progress.
- Targeted credit assignment helps when tasks are multi-step: When the AI had to follow procedures (like coding), pointing to the exact rule that failed or was missing made updates more precise. For web search, where the main issue is broader strategy, this helped less.
- One size doesn’t fit all: The best combo of tricks depends on the task type. If the AI is already decent and just needs polish, several tricks contribute small gains. If it needs to learn new skills, replay and structure help it build strategies. If it must make careful judgments, contrastive comparisons are key.
Why this matters: It shows that you can treat “editing the AI’s playbook” as a real learning problem, not just prompt tinkering. That makes it possible to steadily and safely improve AI behavior during deployment, with human-readable changes that can be inspected and adjusted.
What could this change?
- Practical, ongoing improvement: Instead of costly retraining, teams can keep agents evolving by updating their playbooks based on real-world use.
- Safer, more transparent AI: Because changes are written rules and guidelines, people can read, audit, and debug them.
- Stronger, more adaptable agents: As models get better at reasoning, the “reflect and update” process becomes more powerful, letting agents learn new strategies across many tasks and environments.
- A shared toolkit: The field can stop reinventing isolated methods and instead study context learning as an optimization problem, applying proven ideas (batching, replay, momentum) in a principled way.
In short, the paper argues that improving an AI’s instructions and memory through reflection—using careful, proven optimization habits—can be a fast, reliable path to smarter and more adaptable agents.
Knowledge Gaps
Below is a concise, actionable list of knowledge gaps, limitations, and open questions that remain unresolved in the paper. These items are intended to guide concrete follow-up research.
- Lack of formal guarantees: No convergence guarantees, stability analysis, or sample-complexity bounds are provided for reflective context learning or its primitives; the gradient analogy is functional only, leaving theoretical underpinnings open.
- Step-size analogue and update magnitude: The framework lacks a formal notion of “learning rate” in context space (e.g., controlling edit magnitude or frequency), nor rules for adaptive step-size scheduling akin to Adam or line search.
- Reflection reliability measurement: There is no metric for “reflection quality” (accuracy, consistency, specificity, causal correctness), nor procedures to calibrate or audit reflector outputs against ground truth diagnostics.
- Causal attribution vs. contrastive heuristics: Grouped rollouts offer contrastive signal but no causal framework; it is unclear whether differences between pass/fail traces identify true decision-causing steps or confounded artifacts.
- Error propagation from LLM diagnostics: Reflector hallucinations or misattributions can induce harmful edits; mechanisms to detect, quantify, and correct diagnostic errors (e.g., cross-checks, ensembles, adversarial tests) are not explored.
- Adaptive primitive selection: Some primitives help in one regime but hurt in another (e.g., batching on BrowseComp+/Lite); there is no policy to detect regime shifts online and enable/disable or reweight primitives adaptively.
- Hyperparameter tuning and autoscheduling: Key knobs (batch size B, grouped rollouts G, replay ratio ρ, graduation/eviction thresholds n_grad/n_evict) are fixed and hand-tuned; automated schedules or meta-controllers to optimize them are not studied.
- Optimizer state design and “momentum”: The rolling optimizer state S_t is introduced without quantitative analysis of stability, drift, or conflicting priors; retention length, decay, and summarization strategies remain ad hoc.
- Mutation safety and verification: There is no formal verification or static analysis of playbook edits (e.g., contradiction checks, coverage overlap, regression tests), nor safeguards against syntactic/semantic degradation.
- Edit locality and governance: While localized edits are encouraged, there are no metrics for edit locality, readability, and maintainability of playbooks over time, nor procedures for human-in-the-loop approval.
- Replay curriculum design: The replay buffer uses simple graduation/eviction rules; prioritized sampling criteria, utility-based replay, and curriculum scheduling (by difficulty/diversity) remain uninvestigated.
- Instrumentation interference: Dual-trace credit assignment uses annotated traces that alter behavior but excludes their outcomes, assuming they remain useful; robustness to instrumentation bias and methods to de-bias annotations are untested.
- Scalability with context growth: The impact of growing playbook size on inference latency, context-window limits, retrieval strategies, and optimization dynamics is not quantified; mechanisms for summarization, compaction, or pruning are absent.
- Transfer beyond playbooks: RCL centers on structured playbooks; generality to other context artifacts (retrievers, tools, memory stores, policy libraries) and interactions among them is not evaluated.
- Robustness to initialization: Sensitivity to seed playbook quality and cross-run variance are not reported; no analysis of how initial artifacts constrain reachable optima or the need for bootstrapping procedures.
- Generalization under distribution shift: Experiments are within-benchmark; cross-domain and cross-environment transfer, non-stationary settings, and robustness to drift or adversarial shifts are not explored.
- Dataset and benchmark scope: Only three benchmarks are used; coverage of longer-horizon, multi-agent, multi-modal, or real-time interactive environments is lacking, limiting external validity.
- Reward/label reliability: BrowseComp+ uses LLM-judged accuracy; effects of judge bias, drift, and alignment with the reflector/mutator model family are not analyzed; calibration against human judgments is missing.
- Statistical rigor and reproducibility: Single-run results without confidence intervals, variance estimates, or multiple seeds hinder significance claims; sensitivity to random seeds and run-to-run variability is not reported.
- Compute-cost accounting: The added execution and reflection costs (especially grouped rollouts and dual-trace runs) are not converted into cost-performance curves; practical deployment budgets and trade-offs are unclear.
- Model allocation strategy: Although the paper motivates allocating stronger/weaker models to A, g, f, h, there is no quantitative study of optimal capacity allocation, scaling laws, or cost-aware selection across components.
- Failure-mode taxonomy: While failure modes are discussed qualitatively, there is no standardized taxonomy or automatic detector for variance-induced oscillation, forgetting, or overfitting to guide primitive selection.
- Online safety and misuse: Reflective updates may encode unsafe or biased behaviors; there is no integration of safety constraints, red-teaming, or defense against prompt-injection/data-poisoning during optimization.
- Multi-objective optimization: Trade-offs among accuracy, latency, cost, interpretability, and safety are not modeled; Pareto-aware optimization (beyond GEPA baseline) within RCL is not developed.
- Interaction among primitives: Only limited ablations are shown; non-linear interactions, order effects (e.g., when to introduce replay vs. batching), and combinatorial schedules are not systematically mapped.
- Applicability to partial feedback: The framework assumes supervised or evaluable reward; adaptation to bandit feedback, implicit signals, or delayed/sparse rewards (beyond the provided heuristics) remains untested.
- Human-in-the-loop protocols: Despite the promise of human-readable artifacts, no protocols for human review, edit vetoes, or collaborative co-design of strategies are provided or evaluated.
- Monitoring and rollback: There is no mechanism for detecting regressions and rolling back harmful edits, nor policies for checkpointing, versioning, and recovery at scale.
- Adversarial robustness: The system’s susceptibility to adversarial trajectories that induce detrimental reflections and mutations (e.g., poisoning the replay buffer) is not examined.
- Formal connection to RL: While analogies to RL are drawn, there is no formal mapping to policy-gradient or value-based algorithms (e.g., unbiased estimators, variance bounds), limiting principled design of advantage-like signals in context space.
Practical Applications
Immediate Applications
Below are practical, deployable use cases that map the paper’s findings (reflection + mutation loop; batching, grouped rollouts, credit assignment, failure replay, optimizer state) into concrete products and workflows across sectors. Each item lists sectors, what to build/use, and feasibility constraints.
- Post-deployment “ContextOps” pipeline for LLM agents
- Sectors: software, customer support, e-commerce, professional services, government services
- Tools/products/workflows:
- A ContextOps microservice that:
- Logs trajectories (actions, observations) and outcomes (pass/fail, ratings)
- Runs a stronger “reflector” model to produce structured diagnostics (root cause, gap, attribution)
- Applies controlled “mutator” edits to a structured playbook (Update/Add/Delete of rules) with versioning
- Maintains an optimizer state document (momentum) and a failure replay buffer
- “Context CI/CD”: batch release candidate playbook diffs; grouped rollouts for A/B and contrastive evaluation; human approval gates
- Assumptions/dependencies:
- Access to strong instruction-following models and a stronger reflector/mutator (paper shows gains when reflection quality is high)
- Reliable outcome signals (ground truth, reward functions, or human ratings)
- Structured context artifacts (modular playbooks) and telemetry to attribute credit
- Governance for change control and audit logs
- Customer support and contact center assistants that continuously refine SOPs
- Sectors: customer support, telecom, utilities, retail
- Tools/products/workflows:
- Failure replay on escalations; grouped rollouts on repeated intents to contrast pass vs fail
- Optimizer state to prevent oscillations in policy (e.g., compliance vs empathy balance)
- Localized edits to flows/FAQ rules; auto-curation of “known issues” memory
- Assumptions/dependencies:
- Clear success criteria (resolution, CSAT, AHT); human-in-the-loop approval for policy-sensitive edits
- PII handling and compliance controls
- Coding and DevOps copilots that learn procedural fixes and edge cases
- Sectors: software engineering, DevOps, QA
- Tools/products/workflows:
- RCL for IDE and CI assistants: structured playbooks for refactors, test generation, incident runbooks
- Dual-trace credit assignment (instrumentation) to tie failures to specific rules; batching to reduce variance
- Assumptions/dependencies:
- Ground truth via tests/lints; reproducible environments to collect grouped rollouts
- Guardrails to avoid overfitting to one repo or framework
- Web research and OSINT agents that refine search heuristics
- Sectors: media, competitive intelligence, due diligence, procurement
- Tools/products/workflows:
- Grouped rollouts (multiple browsing attempts per query) with contrastive reflection on successful vs unsuccessful paths
- Auxiliary reflection heads to label “actionable gap” vs “execution variance,” avoiding spurious edits
- Assumptions/dependencies:
- LLM-judged or human-judged accuracy with robust rubrics; safe browsing sandbox; cache to manage cost
- Document processing and back-office automations that learn edge cases
- Sectors: finance (KYC/AML), insurance (claims), logistics (invoices), HR (onboarding)
- Tools/products/workflows:
- Structured playbooks for document routing, exception handling; failure replay prioritizes recurring defects
- Optimizer state to avoid reverting validated rules; localized updates only
- Assumptions/dependencies:
- Access to labels (accept/reject, exception codes); audit trails for compliance; data privacy guarantees
- Education: tutors that adapt hinting strategies without model retraining
- Sectors: edtech, corporate training
- Tools/products/workflows:
- Playbooks for hint sequencing and strategy choice; credit assignment to specific hint rules
- Batching across problem sets; optimizer state to maintain consistent pedagogy
- Assumptions/dependencies:
- Ground truth solutions and rubric-based outcomes; fairness monitoring to prevent biased adaptation
- Healthcare operations automations (non-clinical)
- Sectors: healthcare administration (not clinical diagnosis)
- Tools/products/workflows:
- RCL-managed checklists for prior auth, referrals, coding workflows; failure replay on denials
- Optimizer state for policy stability; strict edit scoping and human approvals
- Assumptions/dependencies:
- PHI compliance (HIPAA/GDPR), explicit success metrics (approval rates, turnaround time), human oversight
- Policy/compliance QA copilot
- Sectors: finance, insurance, legal, government
- Tools/products/workflows:
- Reflective refinement of compliance checklists and red flags based on audit outcomes
- Grouped rollouts with contrastive cases (compliant vs non-compliant) to sharpen criteria
- Assumptions/dependencies:
- Certified review workflows; bias and false-positive monitoring; versioned policy artifacts
- Ranking and moderation calibration without weight updates
- Sectors: marketplaces, content platforms, HR screening
- Tools/products/workflows:
- Use grouped rollouts for near-deterministic ranking tasks (paper shows largest gains here) to refine criteria in playbooks
- Assumptions/dependencies:
- High-quality labels; protections against over-instruction that harms naturalistic judgments
- Enterprise knowledge base that auto-curates tactics
- Sectors: all
- Tools/products/workflows:
- “Dynamic cheatsheet” memory with replay: add missing coverage, prune redundant rules via localized edits
- Assumptions/dependencies:
- Curators for sensitive topics; semantic deduplication and retrieval indexing
Long-Term Applications
These rely on further advances (model reliability, broader instrumentation, safety validation) or scaling beyond current benchmarks.
- Self-evolving agents with fully managed ContextOps (no-weight-update learning at scale)
- Sectors: software, customer support, operations
- Tools/products/workflows:
- Platform that provisions agents with autonomous replay, momentum state, and schema-driven reflections across thousands of tasks
- Cross-system textual gradients (e.g., TextGrad-style) for multi-component pipelines
- Assumptions/dependencies:
- Cost-effective strong reflectors; robust change governance; automatic detection of negative transfer and drift
- Robotics and industrial operations: reflective updates to task-level scripts
- Sectors: robotics, manufacturing, warehousing
- Tools/products/workflows:
- Map executions to semantic traces (visual+action) and refine high-level procedures/playbooks
- Grouped rollouts with controlled environments; localized updates to subroutines
- Assumptions/dependencies:
- Reliable perception-to-text attribution; simulator support; strict safety validation
- Clinical decision support playbooks (care pathway adaptation)
- Sectors: healthcare (clinical)
- Tools/products/workflows:
- Reflection over outcome-validated episodes to propose updates to pathway guidelines
- Multi-level review; structured evidence linking; momentum state to preserve validated guidance
- Assumptions/dependencies:
- Prospective trials, regulatory approvals, bias and safety controls; explainability and auditability
- Autonomous policy and rule maintenance for regulators and enterprises
- Sectors: public policy, legal, compliance
- Tools/products/workflows:
- Systems that reflect on enforcement outcomes and propose policy clarifications/additions; Pareto-aware maintenance across competing goals (fairness, throughput)
- Assumptions/dependencies:
- Democratic oversight; adversarial robustness; transparency of edits and rationales
- Multi-agent organizations with credit assignment across agents
- Sectors: large enterprises, distributed operations
- Tools/products/workflows:
- Dual-trace/contrastive credit assignment extended to identify which agent policy caused failures; structured mutations per agent
- Assumptions/dependencies:
- Fine-grained telemetry; cross-agent attribution standards; conflict resolution protocols
- Energy and critical infrastructure procedure optimization
- Sectors: energy, transportation, aviation
- Tools/products/workflows:
- Reflectively maintained operations checklists; failure replay for rare incident readiness; momentum for stability
- Assumptions/dependencies:
- High-assurance verification; simulators and digital twins for grouped rollouts; regulatory audit trails
- Curriculum design and pedagogy meta-learning
- Sectors: education
- Tools/products/workflows:
- Longitudinal reflection on learning outcomes to evolve curricula and hint policies; prioritized replay of persistent misconceptions
- Assumptions/dependencies:
- Long-term outcome measurement; ethical review for differential impacts
- Marketplace of versioned, auditable “playbooks” as first-class artifacts
- Sectors: software tooling, platforms
- Tools/products/workflows:
- Repositories and registries for playbooks with change ledgers (optimizer state), test matrices (grouped rollouts), and provenance
- Assumptions/dependencies:
- Standard schemas for playbooks and reflections; ecosystem buy-in; security and IP controls
Notes on Feasibility, Dependencies, and Configuration
To make these applications work reliably, the following cross-cutting considerations from the paper should be accounted for:
- Model roles and capacity allocation:
- Use a stronger model for reflection/mutation than for the agent when possible; the paper shows reflection quality often yields the best gains per compute.
- Outcome and reward signals:
- Immediate deployments need clear supervision: ground truth, rubrics, or robust proxy rewards; weak or biased LLM-judges can mislead reflections.
- Structured context and localized edits:
- Represent context as modular playbooks with individually addressable entries; restrict mutator to Update/Add/Delete to reduce overfitting and forgetting.
- Variance-aware execution:
- Tune batching and grouped rollouts to the task regime:
- Grouped rollouts are especially effective for near-deterministic judgment tasks (e.g., ranking).
- Batching helps when failures share structure but can hurt when failures are highly diverse.
- Credit assignment and instrumentation:
- Dual traces (standard + annotated) improve entry-level attribution for multi-step tasks but require careful separation of evaluation from instrumented runs.
- Memory and stability:
- Maintain an optimizer state document (momentum) and a failure replay buffer to prevent oscillation and catastrophic forgetting; configure replay ratios and graduation/eviction thresholds.
- Governance and safety:
- Human-in-the-loop approvals for high-risk domains; audit logs for every change; privacy and compliance (e.g., PHI, PII) controls.
- Cost and compute:
- Grouped rollouts increase cost; prioritize where contrastive signal is most valuable. Start with reflection-quality primitives (optimizer state, auxiliary reflection schema) for best ROI.
These applications operationalize the paper’s core insight: treat context updates as an optimization problem, not ad hoc prompt tweaks, and apply principled primitives (variance reduction, credit assignment, replay, momentum, structural biases) to achieve stable, interpretable, and transferable improvements without retraining model weights.
Glossary
- ACE: A prior context-learning method that uses structured edits to iteratively improve playbooks. "ACE~\citep{zhang2026ace} introduced structured, incremental delta updates to modular playbooks."
- Adam: An adaptive optimizer that combines momentum and per-parameter scaling (widely used in gradient-based training). "Momentum / Adam"
- auxiliary losses: Additional training objectives used to guide learning and prevent superficial solutions. "including batching, improved credit-assignment signal, auxiliary losses, failure replay, and grouped rollouts for variance reduction."
- batching: Aggregating multiple samples per update to reduce variance in the learning signal. "including batching, improved credit-assignment signal, auxiliary losses, failure replay, and grouped rollouts for variance reduction."
- catastrophic forgetting: When updates to a learned system cause it to lose previously acquired capabilities. "risks catastrophic forgetting"
- contrastive advantage estimation: A technique that compares successful and failed rollouts of the same task to isolate decision-quality differences. "grouped rollouts with contrastive advantage estimation"
- context artifact: The external, interpretable components (e.g., playbooks, memory) that condition an agent’s behavior at inference time. "The context artifact is the collection of all interpretable, externalized components that influence the agent's behavior at inference time"
- context-space optimization: Improving an agent by editing its context (prompts, playbooks, tools) instead of its parameters. "Context-space optimization has its roots in prompt engineering and discrete prompt tuning."
- credit assignment: Determining which components or decisions caused observed outcomes to guide targeted updates. "including credit assignment, overfitting, forgetting, local optima, and high-variance learning signals,"
- curriculum: A sampling strategy that concentrates learning on most informative or marginally beneficial cases. "This implements a curriculum that concentrates optimization effort where the marginal return is highest, analogous to prioritized experience replay"
- delta edits: Localized, incremental modifications applied to specific entries in a structured playbook. "We adopt its structured delta edits, helpful/harmful bullet scoring, and the Generator--Reflector--Curator decomposition."
- dual-trace credit assignment: A method using a standard and an instrumented (annotated) trace to attribute outcomes to specific playbook entries. "We address this with dual-trace credit assignment."
- exponential moving average: A smoothed running average used in momentum-like optimization to stabilize updates. "momentum maintains an exponential moving average "
- experience replay: Re-using past failures or hard cases during training to mitigate forgetting and improve stability. "Experience replay buffers address analogous issues in parameter-space learning"
- failure replay: Re-sampling previously failed tasks to verify fixes and prevent regressions. "including batching, improved credit-assignment signal, auxiliary losses, failure replay, and grouped rollouts for variance reduction."
- grouped rollouts: Executing multiple attempts of the same task per iteration to obtain contrastive signals between passes and failures. "and grouped rollouts for variance reduction."
- in-context learning: Conditioning a LLM’s behavior by examples or instructions in its input without updating weights. "In-context learning~\citep{brown2020language} demonstrated that context is a powerful conditioning mechanism"
- inductive biases: Structural constraints or preferences that guide a learner toward more generalizable solutions. "Auxiliary Losses and Structural Inductive Biases"
- mutator: The component that applies the reflector’s diagnostic signal to update the context. "The mutator takes the current context and the diagnostic signal and produces an updated context:"
- optimizer state: Persistent information (e.g., change ledger, hypotheses) carried across iterations to stabilize learning. "Optimizer State and Momentum"
- Pareto-aware evolutionary search: Evolutionary optimization that balances multiple objectives without dominating trade-offs. "Pareto-aware evolutionary search \citep{agrawal2025gepa}"
- Pareto frontier: The set of non-dominated solutions that optimally trade off multiple objectives. "maintain its Pareto frontier"
- playbook: A structured set of rules, guidelines, or procedures that direct an agent’s behavior. "structured playbooks of behavioral rules"
- prioritized experience replay: Sampling past experiences according to their learning utility rather than uniformly. "analogous to prioritized experience replay"
- ReAct loop: An agent architecture interleaving reasoning and acting steps to solve tasks. "implemented as a ReAct loop \citep{yao2023react}"
- Reflective Context Learning (RCL): The paper’s framework where reflection generates update signals and mutations apply them in context space. "We present Reflective Context Learning (RCL)"
- reflector: The component that analyzes trajectories and outcomes to produce a structured diagnostic update signal. "The reflector takes the trajectory, its outcome, and the current context as input and produces a structured diagnostic signal:"
- replay buffer: A storage of past (especially failed) tasks used to resample and stabilize learning over time. "We maintain a failure replay buffer "
- sampling-based momentum: A method that emulates momentum behavior via sampling strategies rather than explicit numeric accumulators. "sampling-based momentum for textual gradient descent"
- SGD-like updates: Iterative, gradient-descent-inspired updates applied to context rather than parameters. "iterative, SGD-like updates"
- soft prompt tuning: Learning continuous prompt embeddings for a frozen model using gradient-based updates. "Soft prompt tuning~\citep{lester2021power, li2021prefix} offered a gradient-based alternative"
- structured playbooks: Modular, addressable representations of behavioral rules enabling localized edits and credit assignment. "structured playbook representations as the learned artifact"
- textual gradient: Natural-language feedback that acts like a gradient signal to direct context updates. "batched textual gradients \citep{pryzant2023automatic}"
- trajectory: The sequence of actions, observations, and reasoning steps produced during task execution. "The trajectory is a sequence of actions, observations, and intermediate reasoning steps."
- value decomposition: A technique for attributing a global reward to component decisions or agents. "value decomposition~\citep{sunehag2018valuedecomposition}"
Collections
Sign up for free to add this paper to one or more collections.