- The paper introduces a unified evaluation framework that combines precision and recall metrics using importance-aware weighting to assess factual completeness.
- It employs a modular pipeline involving retrieval, fact extraction, and claim decomposition to systematically score evidence and identify unsupported claims.
- Empirical results reveal a precision–recall tradeoff across domains, with models reliably capturing salient facts yet often omitting less prominent details.
Motivation and Framework Design
Factuality evaluation in LLMs for long-form generation has traditionally emphasized precision: decomposing outputs into atomic claims and verifying each against external sources. This approach quantifies how often models generate claims supported by evidence but insufficiently addresses factual recall, i.e., whether all relevant facts are included. The omission of critical, contextually relevant content—factual incompleteness—is a persistent challenge, especially in open-ended, information-dense settings.
The paper proposes a unified framework that systematically evaluates both precision and recall. Reference facts are constructed via retrieval from external sources, followed by fact extraction and de-duplication. Crucially, the framework introduces importance-aware weighting for reference facts based on both query-specific relevance and topic-level salience, addressing the inadequacy of treating all facts as equally important. Atomic claims are extracted from LLM outputs, using guided prompts for granularity and specificity, then compared against reference facts and scored according to coverage (recall), evidential support (precision), and contradiction rates.
Experimental Protocol and Datasets
The evaluation spans three challenging domains: FactScore (biography generation prompts), LongFact (topic-diverse queries requiring long-form answers), and LongForm (instruction-tuned prompts with Wikipedia, C4, StackExchange, and WikiHow provenance). Model outputs from four open LLMs (Llama-3.1-8B-Instruct, Llama-3.1-70B-Instruct, Qwen2.5-7B-Instruct, Mistral-7B-Instruct) and two commercial closed models (GPT-4o-mini, Gemini2.5-flash-lite) are assessed for factual precision, recall, and F1. For claim extraction and verification, the pipeline leverages LLM-based decomposition and scoring.
Empirical Results and Analysis
Results demonstrate strong domain dependence and a notable precision–recall tradeoff. Models typically achieve higher precision than recall: factual incompleteness is prevalent. For example, in the Bio domain, Gemini2.5-flash-lite yields maximal overall performance, but in LongFact, GPT4o-mini attains peak recall with lower precision, corresponding to higher verbosity. Notably, unsupported claims are the dominant failure mode; contradiction rates, particularly in biographical generation, remain non-negligible and are associated with explicit factual conflicts (e.g., incorrect birth years).
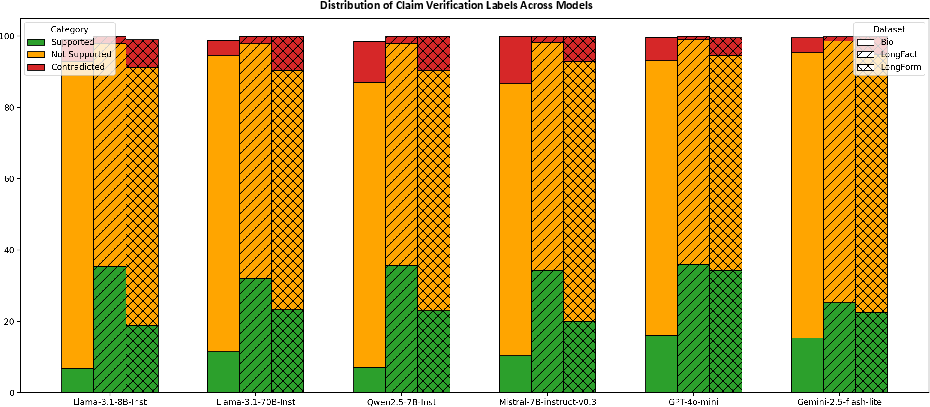
Figure 1: Percentage breakdown of claims labeled as supported, not supported, or contradicted across models and datasets, capturing dominant failure modes.
The claim-to-fact ratio ρ quantifies average claim output per reference fact, illuminating precision–recall balance. Larger ρ values generally correspond to longer generations and increased recall, but often at the expense of precision. GPT4o-mini achieves near-maximal recall with substantially fewer claims per fact, showing claim efficiency and evidence alignment. This metric distinguishes models that inflate recall by generating voluminous claims from those that maintain both precision and recall through contextually targeted, evidence-grounded statements.
Importance-Aware Fact Coverage
The importance-weighted reference inventory is formed by scoring extracted facts for both relevance (to the query) and salience (within the topic). Combined scoring (α=β=1) governs reference set selection, allowing factual recall metrics to prioritize core content. Recall@k analysis reveals that when only the most salient fact is considered (K=1), LLMs reliably recover this content. As K increases, recall over relevance-weighted facts becomes crucial for comprehensive coverage.
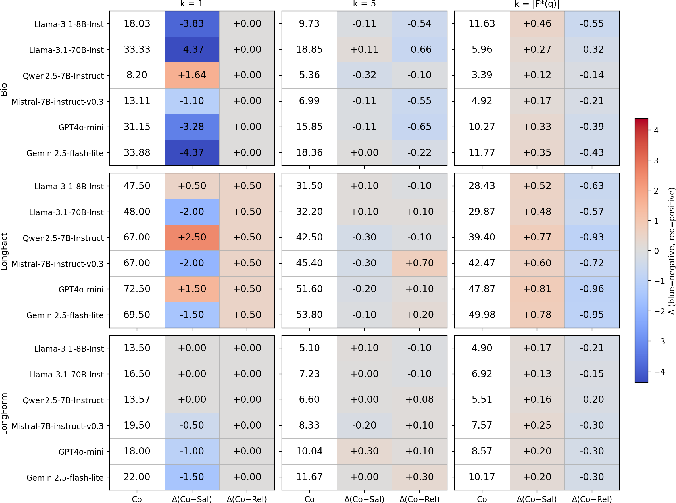
Figure 2: Recall comparison across datasets for reference sets constructed with combined, relevance-only, and salience-only importance scoring, visualizing core versus broad fact coverage.
Models consistently exhibit stronger coverage for highly salient facts but fail to exhaustively cover all relevant facts as K increases. This substantiates the claim that LLM factuality is robust for principal facts but incomplete for less prominent, yet contextually pertinent, information.
Practical Implications and Theoretical Outlook
The importance-aware recall metric advances factuality evaluation beyond precision, enabling thorough analysis of content completeness and error modes (unsupported, contradicted). For practical deployments—biographies, medical summaries, review generation—ensuring inclusion of critical facts is vital for reliability. The framework’s modular pipeline (retrieval, fact extraction, importance scoring, claim decomposition) is applicable to diverse domains and supports granular model comparisons.
Theoretically, the dual precision–recall framework aligns factuality evaluation with classical information retrieval paradigms, formalizing coverage as a core metric. Importance-aware weighting further tailors evaluation to user-centric information needs, accommodating flexible fact budgets and contextual relevance.
Limitations and Future Directions
Reliability depends on the quality of external knowledge sources, fact extraction accuracy, and consistency in LLM-based claim decomposition and verification. Propagated errors across pipeline stages may distort recall estimates. Enhancing source selection, fact extraction fidelity, and claim verification robustness will strengthen metric reliability.
Future work should extend automatic reference-fact construction with source reliability filtering, improved noise mitigation, and broader coverage for emerging facts. Importance-aware metrics can be further refined by incorporating user-specific information needs and dynamic relevance modeling.
Conclusion
This paper establishes a comprehensive factuality evaluation paradigm for long-form LLM generation, integrating precision and recall with importance-weighted reference fact scoring. Results reveal that factual incompleteness—omission of relevant facts—remains a substantial limitation, and that LLMs preferentially recover highly salient facts over a complete factual inventory. The proposed framework supports both empirical benchmarking and theoretical development for factuality metrics, with substantial implications for robust, context-sensitive LLM evaluation and deployment.