Empty Shelves or Lost Keys? Recall Is the Bottleneck for Parametric Factuality
Abstract: Standard factuality evaluations of LLMs treat all errors alike, obscuring whether failures arise from missing knowledge (empty shelves) or from limited access to encoded facts (lost keys). We propose a behavioral framework that profiles factual knowledge at the level of facts rather than questions, characterizing each fact by whether it is encoded, and then by how accessible it is: cannot be recalled, can be directly recalled, or can only be recalled with inference-time computation (thinking). To support such profiling, we introduce WikiProfile, a new benchmark constructed via an automated pipeline with a prompted LLM grounded in web search. Across 4 million responses from 13 LLMs, we find that encoding is nearly saturated in frontier models on our benchmark, with GPT-5 and Gemini-3 encoding 95--98% of facts. However, recall remains a major bottleneck: many errors previously attributed to missing knowledge instead stem from failures to access it. These failures are systematic and disproportionately affect long-tail facts and reverse questions. Finally, we show that thinking improves recall and can recover a substantial fraction of failures, indicating that future gains may rely less on scaling and more on methods that improve how models utilize what they already encode.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple question using a memorable image: when a big AI model gives a wrong fact, is it because its “shelves are empty” (it never learned the fact), or because it “lost the keys” (it learned the fact but can’t find it when asked)? The authors show that for today’s strongest models, the shelves are mostly full—the facts are stored—but the models often struggle to recall them on demand. They also introduce a new test set, called WikiProfile, to measure this difference carefully.
What questions were the researchers asking?
The researchers focused on four easy-to-understand questions:
- Are wrong answers mostly caused by missing facts (not learned) or by recall problems (hard to access)?
- How can we tell the difference, using only what the model outputs?
- When do recall problems happen most—on rare facts or when the question is asked “backwards”?
- Can “thinking” (step-by-step reasoning during answering) help the model find facts it already stored?
How did they study it?
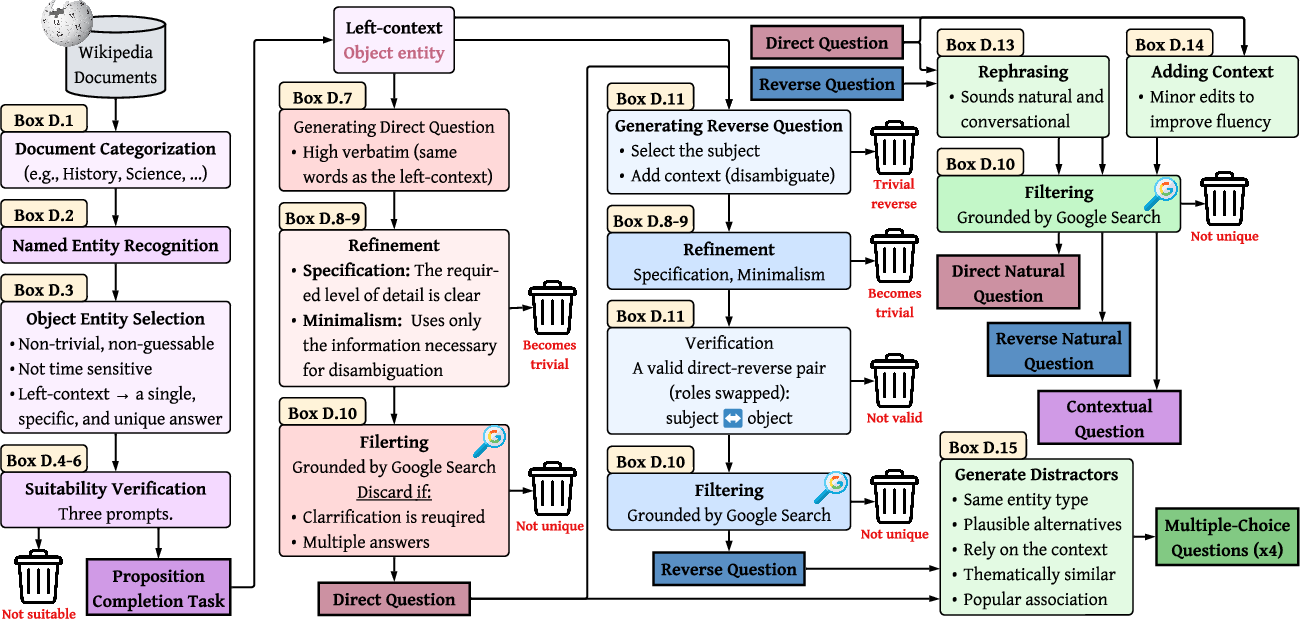
To study this, they built a benchmark called WikiProfile using real facts from Wikipedia. For each fact, they asked the model several kinds of questions to see if the fact is stored and how accessible it is.
Here’s the idea in everyday terms:
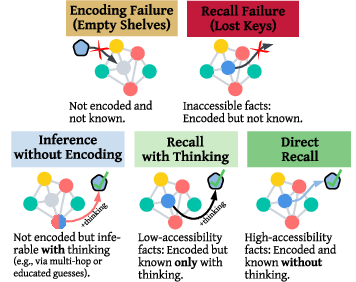
- Think of the model as a student with a huge notebook (its learned parameters). “Encoding” means the fact is written in the notebook. “Recall” means the student can find it quickly when asked in different ways.
- They tested 13 AI models, including some of the strongest available, and asked over 4 million questions in total.
They used three kinds of checks:
- “Do you have it written down?” (Encoding tests)
- The model sees the original Wikipedia context (everything up to the missing fact) and is asked to complete the sentence or answer a direct question right there. If it can reproduce the fact in this training-like setting, it likely encoded (stored) it.
- “Can you say it in different ways?” (Knowledge/recall tests)
- The model is asked the same fact in different phrasings and in two directions:
- Direct: A → B (e.g., “Which band played its first gig at the Boardwalk club?” → “Oasis”)
- Reverse: B → A (e.g., “Which venue hosted Oasis’s first gig?” → “The Boardwalk club”)
- If it answers correctly across these variations, it truly “knows” the fact (good recall).
- The model is asked the same fact in different phrasings and in two directions:
- “Can you recognize it if you see it?” (Multiple-choice)
- The model picks from several answer choices. This tests recognition: even if it can’t recall from scratch, can it spot the right answer when shown?
They also tested answers with and without “thinking,” meaning the model is allowed (or not) to write out intermediate steps before answering—like showing its work in math class.
What did they find?
The main results are clear and surprising:
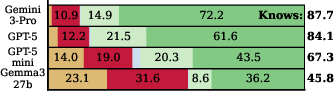
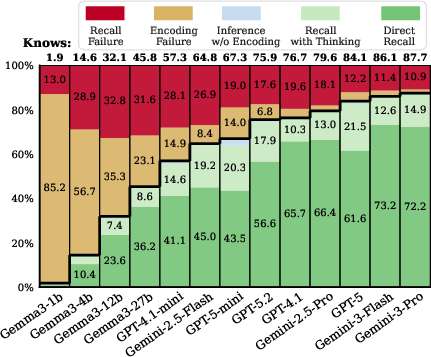
- Encoding is nearly saturated in top models:
- Frontier models (like Gemini-3 and GPT-5 in the paper) stored about 95–98% of the tested facts. So, the “shelves” are mostly full.
- Recall is the bottleneck:
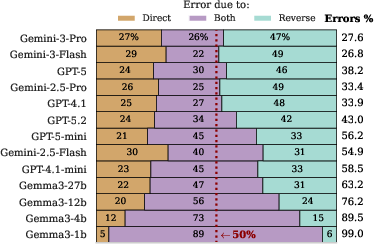
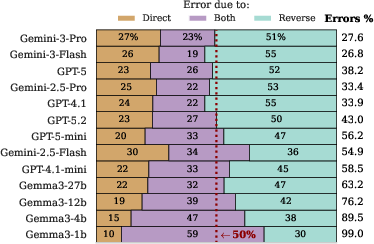
- Even though the facts are stored, top models still failed to recall 25–33% of them when asked normally (no “thinking”). In other words, many mistakes come from “lost keys,” not empty shelves.
- Recall failures are systematic, not random:
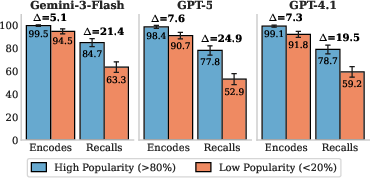
- Rare facts (the “long tail”): Models recall common/popular facts more easily. For rare facts, the encoding gap is small, but the recall gap is large. So the models often have the rare facts stored, but can’t pull them out quickly.
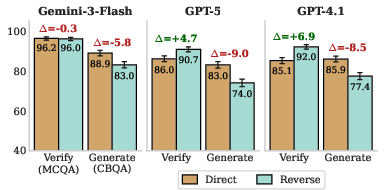
- Reverse questions (the “reversal curse”): Models do worse when asked “backwards” (B → A) compared to “forward” (A → B), even if they’ve encoded both sides. Interestingly, when given multiple-choice options, models do just as well—or better—on reverse questions. That means they “know it when they see it,” but struggle to recall it unaided. This is a classic recall issue, not a missing-knowledge issue.
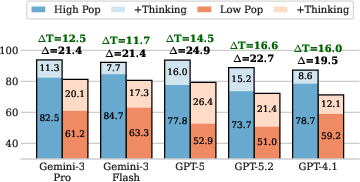
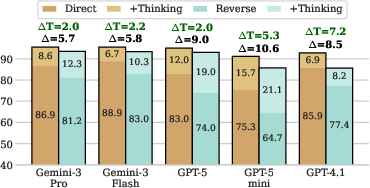
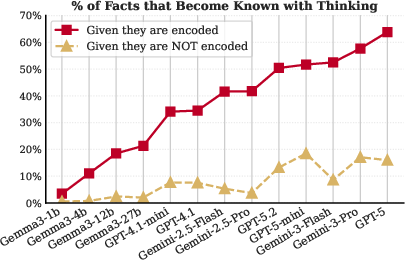
- “Thinking” helps unlock stored facts:
- Allowing the model to think step by step recovers a large fraction (about 40–65%) of facts that were encoded but not recalled at first. This boost is strongest for hard cases: rare facts and reverse questions.
- If a fact truly isn’t stored, thinking helps much less (about 5–20%). So “thinking” mostly works by helping find stored info, not by guessing or doing long chains of reasoning.
Why this matters
- The big takeaway: For top AI models, the main problem isn’t learning more facts—it’s accessing the facts they already learned. This shifts where improvements should focus.
- Instead of only making models bigger or feeding them more data, we can:
- Improve how models retrieve what they already know (better prompts, better post-training, smarter response strategies).
- Use “thinking” techniques to help with tough recall situations, especially for rare facts and reverse questions.
- This also mirrors human memory:
- People often have “tip-of-the-tongue” moments—they know something but can’t immediately recall it. Seeing options (multiple choice) or taking a moment to think often helps. The same pattern shows up in these AI models.
In short
- Purpose: Separate “don’t know it” from “can’t find it.”
- Method: A new Wikipedia-based test that checks if a fact is stored and how easy it is to recall in different ways.
- Findings: Top models store most facts, but recalling them—especially rare or reverse ones—is hard. Thinking helps recover many of these.
- Impact: Future progress will likely come from better recall and smarter use of existing knowledge, not just from making models larger.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of concrete gaps and open questions left unresolved by the paper. Each point is phrased to enable targeted follow-up by future researchers.
- Behavioral proxy for “encoding”: The paper equates successful reproduction in a pre-training-like context with parametric encoding, but does not causally validate this. Can causal interventions (e.g., model editing, weight ablations, activation patching) distinguish true storage from inference/guessing in these tasks?
- Training-data contamination and coverage: The benchmark assumes Wikipedia facts are in pre-training data, but the specific snapshots, coverage, and duplication across training corpora are unknown. How do results change for facts explicitly verified as absent/present in training data?
- Scope limited to single-hop, time-stable entity facts: The pipeline filters out time-varying facts and largely targets single-hop propositions. Do recall bottlenecks persist for multi-hop, numerical, causal, procedural, commonsense, and temporally-evolving facts?
- Generalization beyond Wikipedia: Findings are demonstrated only on Wikipedia-derived facts. How does the profiling framework perform on domain-specific corpora (e.g., biomedical, legal, code), user-generated content, or multilingual sources?
- Popularity measure vs. true training frequency: “Popularity” is approximated via page visits, which may not track token frequency in training data. Can recall difficulty be tied to measured pre-training exposure (e.g., document frequency, token counts, redundancy) rather than proxy signals?
- Reverse vs. direct asymmetry mechanisms: The paper shows reverse questions are harder in generation but not in verification, suggesting recall phenomena. What training objective or representation-level factors produce this asymmetry, and can targeted pre-training/post-training mitigate it?
- Limited paraphrase diversity: “Knowledge” is assessed over only four paraphrases (two direct, two reverse). How sensitive are conclusions to broader paraphrase/format diversity (e.g., cloze, declarative, dialogue, partial context, coreference variants)?
- Grader dependence and bias: Autoraters are LLM-based (Gemini-2.5-Pro). Although cross-family agreement is high, the grader may encode biases or misjudge borderline cases. How do results change under human evaluation, multi-grader ensembles, or adversarial checking?
- Exclusion of PARTIALLY/OTHER responses: The analysis excludes ambiguous or different-granularity responses, potentially masking nuanced failures. What error taxonomies emerge if these cases are scored with graded weights, and do conclusions about recall bottlenecks hold?
- Sampling and threshold sensitivity: Encoding/knowledge decisions use samples, temperature 1, and a majority threshold (). What is the robustness under different sampling regimes (e.g., deterministic decoding, larger ), thresholds, and per-model calibration?
- Potential hidden retrieval in “thinking” modes: Thinking-optimized models may implicitly leverage internal retrieval or training-time heuristics. Can we verify that improvements are due to parametric recall facilitation rather than undisclosed retrieval-like behaviors?
- Cost–benefit and budget control for thinking: The paper shows thinking recovers many encoded-but-not-accessible facts but does not quantify compute trade-offs or diminishing returns. What are accuracy–cost curves under controlled thinking budgets, and how do they vary by fact type?
- Adaptive thinking policies: There is no mechanism to decide when to deploy thinking. Can “feeling-of-knowing” proxies, uncertainty estimators, or meta-cognitive signals trigger thinking only when it is likely to help?
- Post-training and alignment ablations: The paper hypothesizes that post-training improves access to encoded knowledge but does not test this. Which alignment strategies (e.g., instruction tuning, preference optimization) most effectively reduce recall failures, and why?
- Prompt and context design for direct recall: Beyond enabling “thinking,” what prompt structures, schema regularization, or context scaffolds best improve direct recall without extra computation?
- Recognition vs. recall dissociation diagnostics: Multiple-choice performance suggests latent bidirectional associations. Can we build systematic protocols to diagnose facts with strong recognition but weak recall and design targeted recall training for them?
- Detecting encoded-but-inaccessible facts at inference time: How can a system identify that a fact is likely encoded but currently inaccessible (tip-of-the-tongue states) and select appropriate recall aids (e.g., reformulations, related cues)?
- Long-form generation and knowledge integration: The study focuses on short-form QA. Do recall bottlenecks similarly impair long-form synthesis (e.g., multi-fact narratives), and can thinking-based scaffolds improve factual integration across longer contexts?
- Robustness to ambiguity and aliasing: The benchmark enforces single answers; real-world facts often have aliases, near-synonyms, or contextual qualifiers. How do encoding/recall profiles change under controlled ambiguity and entity alias resolution?
- Distractor quality in multiple-choice: Distractors are LLM-generated and matched on entity type but may vary in plausibility or “answer-only” cues. Can controlled distractor difficulty calibrate recognition more reliably?
- Cross-lingual and cross-script coverage: The analysis is monolingual. Do encoding saturation and recall bottlenecks hold across languages/scripts, and how do translation/alias issues affect reverse/directionality patterns?
- Mechanistic understanding of recall: The paper frames recall behaviorally but does not probe mechanisms (e.g., how attention, position bias, or representational geometry impact retrieval). Can interpretability tools reveal where recall fails inside the model?
- Interplay with retrieval-augmented generation (RAG): The study isolates parametric knowledge. How do recall bottlenecks change under RAG, and can RAG be tuned to preferentially assist reverse/long-tail queries without overwhelming parametric recall?
- Dataset reproducibility and auditing: The pipeline is automated and strict but relies on LLM prompts and web-grounded filtering. Comprehensive audits of selection biases, failure modes, and reproducibility across corpora and LLM versions remain to be conducted.
Glossary
- Alignment: Post-training methods that adjust model behavior to desired objectives and improve how models use their learned knowledge. "alignment teaches models how to better utilize knowledge acquired during pre-training"
- Autorater: An automated grader (usually an LLM) that labels model responses as correct or incorrect. "we use a prompted LLM grader (autorater) to compare each response to the gold answer and label it as correct or incorrect."
- Bidirectional association: The two-way linkage between entities in a fact (e.g., A↔B), indicating the relation holds both ways for recognition. "LLMs are aware of the bidirectional association of the fact"
- Chain-of-thought (CoT) prompting: A prompting strategy that elicits intermediate reasoning steps before an answer. "including both chain-of-thought (CoT) prompting and thinking-optimized LLMs."
- Closed-book generation: Answering questions without external tools or retrieval, purely from model parameters. "we compare closed-book generation with multiple-choice questions"
- Contextual questioning: An encoding task that appends a question to the original source context to prime recall. "The second task, which we refer to as contextual questioning, uses the same left context"
- Distractors: Plausible but incorrect answer options used in multiple-choice questions. "a multiple-choice variant with three plausible distractors matched by entity type and thematic similarity."
- Existential quantification: The logical “there exists” operator, used here to define when a fact counts as encoded. "encoding uses existential quantification () because reproducing a fact in any priming context suffices as evidence of storage"
- False Discovery Rate (FDR) correction: A statistical method to control expected false positives across multiple tests. "and after FDR correction, we find no significant effects"
- Feeling-of-knowing phenomenon: A cognitive state where one expects to recognize an answer despite failing to recall it. "echo the feeling-of-knowing phenomenon: people often predict they will recognize an answer even when they cannot recall it"
- Frontier LLMs: The most advanced, state-of-the-art LLMs. "For frontier LLMs, including Gemini-3-Pro and GPT-5, encoding is nearly saturated"
- Grounded in web search: Using web search evidence to validate or filter generated items. "via an automated pipeline with a prompted LLM grounded in web search"
- Inference-time computation: Additional computation performed during inference to aid recall or reasoning (here, “thinking”). "can only be recalled with inference-time computation (thinking)"
- Knowledge profiling: A framework that categorizes facts by whether they are encoded and how accessible they are. "We introduce knowledge profiling: a framework that categorizes facts into one of five profiles"
- Long-tail facts: Rare or infrequently encountered facts that models are less likely to have robustly accessible. "These failures are systematic and disproportionately affect long-tail facts and reverse questions."
- Multi-hop reasoning: Reasoning that chains together multiple intermediate facts to derive an answer. "including multi-hop reasoning or educated guessing based on other encoded facts."
- Named Entity Recognition (NER): Identifying and classifying entities (e.g., persons, locations) in text. "we perform NER to identify entities and their types"
- Open-weight LLMs: Models whose parameters are publicly accessible, as opposed to proprietary “closed-weight” models. "applies to both closed- and open-weight LLMs."
- Parametric knowledge: Information stored within a model’s learned parameters, not external tools or documents. "it is tempting to view parametric knowledge as secondary"
- Post-training: Stages after pre-training (e.g., instruction tuning, alignment) that adjust model behavior. "Recall failures suggest post-training interventions that often improve how models utilize what they already encode"
- Pre-training objective: The training task used during pre-training (e.g., next-token prediction) that the model optimizes. "This task directly mimics the pre-training objective for which the LLM was optimized."
- Pre-training-like context: An input setup that resembles how data appeared during pre-training, used to test encoding. "an LLM encodes a fact if it can correctly reproduce that fact in a pre-training-like context."
- Proposition completion: Completing a factual statement using its left context to test whether a fact is encoded. "The first task is proposition completion (see Figure~\ref{fig:setup})"
- Reversal curse: The tendency for models to answer “A is B” but fail the reverse “What is B?” query. "the reversal curse \citep{reversal, LinFL0L00WY24}"
- Retrieval-augmented generation (RAG): Combining information retrieval with generation to improve factuality. "In the age of retrieval-augmented generation (RAG) and tool-using agents"
- Thinking: Inference-time techniques that elicit intermediate computations before the final answer. "We use thinking to refer to inference-time techniques that elicit intermediate computations before the final answer"
- Thinking-optimized LLMs: Models designed to allocate extra computation to intermediate reasoning during inference. "Thinking-optimized LLMs such as Gemini-3, Gemini-2.5, and GPT-5 models allocate additional computation to thinking by default"
- Tip-of-the-tongue phenomenon: A memory retrieval failure where stored information is temporarily inaccessible. "The tip-of-the-tongue phenomenon describes states in which a person is confident they know something but cannot immediately produce it"
- Universal quantification: The logical “for all” operator, used here to define robust factual knowledge across phrasings/directions. "knowledge uses universal quantification () because robust recall should not depend on phrasing or query direction."
- Verification (multiple-choice): Assessing recognition by presenting the correct answer among distractors. "in which the correct answer is presented among distractors (verification)."
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging the paper’s profiling framework, WikiProfile pipeline, and empirical insights about recall vs. encoding.
- Recall-aware evaluation and routing in LLM systems
- Sectors: software, enterprise platforms, healthcare, finance, legal, customer support
- What: Integrate the paper’s knowledge-profiling framework to distinguish encoding vs. recall failures in pre-production and production evals. Route queries likely to suffer recall failures to retrieval (RAG), “thinking” (e.g., chain-of-thought or reasoning-optimized modes), or human review.
- Tools/workflows: “Recall-gate” middleware that tags queries by recall risk (reverse direction, rare/long-tail, phrasing divergence), then:
- direct answer if high-confidence recall
- activate thinking if recall risk is moderate
- route to RAG or human if recall risk is high
- Dependencies/assumptions: Access to a “thinking” mode (or CoT prompting), inference budget, instrumentation for logging and risk rules, and a QA/rating pipeline for profiler labels.
- Domain-specific WikiProfile benchmarks for QA and compliance
- Sectors: healthcare, finance, legal, education, government
- What: Use the fully automated pipeline (LLM + web search) to construct domain-specific fact sets with encoding- and recall-targeting tasks (e.g., proposition completion, direct/reverse questions).
- Tools/workflows: Internal benchmark creation over curated corpora (clinical guidelines, policy manuals, procedure handbooks), plus automated filtering and manual spot checks; add into model procurement and periodic audits.
- Dependencies/assumptions: Access to licensed content, domain search endpoints or enterprise search, and limited manual validation; grader reliability on specialized vocabulary.
- Reverse-question handling and query rewriting
- Sectors: search/assistants, customer support, dev tools
- What: Automatically rewrite reverse queries into direct forms (or add context similar to training-time patterns) to improve recall without extra compute.
- Tools/workflows: Light-weight subject–object detection, relation direction classifiers, templates that rephrase “reverse” questions into “direct” equivalents; optional auto-append of source-like context.
- Dependencies/assumptions: Accurate entity/relation parsing; small risk of misparaphrase; evaluation on domain language to avoid biasing answers.
- Popularity-aware adaptive inference
- Sectors: consumer assistants, e-commerce, enterprise knowledge management
- What: Use fact “popularity” proxies (e.g., query frequency, doc visits) to predict recall difficulty and allocate compute (thinking or retrieval) selectively for long-tail facts.
- Tools/workflows: Popularity scoring from logs or corpus stats; dynamic inference policy to increase compute or use RAG for rare entities/relations.
- Dependencies/assumptions: Reliable popularity signals; privacy-aware log processing; monitoring to calibrate thresholds.
- Multiple-choice (MC) verification UX for high-risk facts
- Sectors: education, knowledge workers, research assistants
- What: For queries prone to recall failures (reverse/long-tail), present an MC verification step to leverage models’ strong recognition ability before finalizing a free-form answer.
- Tools/workflows: UI components that request user confirmation via candidates; internal MC probes to verify candidate answers before generation.
- Dependencies/assumptions: Not suitable for time-critical or high-stakes clinical/financial decisions without human oversight; careful distractor design to avoid anchoring.
- Prompting guidelines and “prompt linting” for recall
- Sectors: all industries using LLMs
- What: Encourage prompts that match training-like contexts, avoid reverse direction when possible, and enable “thinking” when uncertainty is detected.
- Tools/workflows: Prompt linters recommending phrasing changes, context addition, and fallback to thinking; internal docs with best practices derived from profiling.
- Dependencies/assumptions: Users or orchestration layers must accept prompt modifications; access to thought-enabled models or CoT patterns.
- Model selection and procurement criteria beyond accuracy
- Sectors: enterprise procurement, MLOps
- What: Rank and select models using recall-centric metrics (direct recall rates on long-tail/reverse questions, thinking recovery rates) rather than accuracy alone.
- Tools/workflows: Comparative bake-offs with domain WikiProfiles; dashboards showing recall vs. encoding failure rates and cost-per-correct for direct vs. thinking.
- Dependencies/assumptions: Benchmark curation time; consistent grading across models; budget to evaluate at scale.
- Recall-aware RAG design (indexing reverse relations)
- Sectors: enterprise knowledge management, software
- What: Augment knowledge graphs and retrievers with inverted relations and paraphrase-rich passages to support reverse queries and phrasing variability.
- Tools/workflows: Data preprocessing to generate inverse edges and rewrite snippets; retriever fine-tuning with reverse-oriented queries; query planners aware of recall risks.
- Dependencies/assumptions: Up-to-date KBs; governance for synthetic data generation; retriever tuning cycles.
- Operational dashboards for recall vs. encoding
- Sectors: platform operations, MLOps
- What: Monitor recall failure rates by topic, popularity tier, and question direction; measure how often thinking/RAG is invoked and its recovery yield.
- Tools/workflows: Telemetry and tagging for recall indicators; A/B tests of routing policies; SLOs for long-tail and reverse accuracy.
- Dependencies/assumptions: Logging and analytics pipelines; privacy compliance; consistent graders.
- Education and training products that balance recall and recognition
- Sectors: edtech, corporate L&D
- What: Build study modes that separate recall practice (open-ended) from recognition (MC), simulating “tip-of-the-tongue” recovery by prompting deliberate steps.
- Tools/workflows: Quiz generators using the paper’s task types; adaptive difficulty that toggles between direct and reverse questions and inserts thinking prompts.
- Dependencies/assumptions: Access to curricular content; pedagogical validation for targeted learning outcomes.
- Policy-aligned internal testing for high-stakes deployments
- Sectors: public sector, healthcare, finance, safety-critical
- What: Incorporate recall profiling into risk assessments and go/no-go decisions; mandate tests on long-tail and reverse scenarios; document thinking/RAG fallback rates.
- Tools/workflows: Policy templates that require recall-aware evidence; attestations in model cards; red-team checklists emphasizing recall bottlenecks.
- Dependencies/assumptions: Organizational buy-in; standardized reporting; auditor-grade data hygiene.
- User-facing disclosures and confirmations for rare or reversed facts
- Sectors: consumer apps, enterprise assistants
- What: When recall risk is high, surface gentle disclosures (e.g., “This may be a rare/reverse fact—double‑check”) or ask for confirmation before committing to actions.
- Tools/workflows: UI cues tied to profiler signals; “confirm before execute” for actions seeded by risky facts.
- Dependencies/assumptions: UX acceptance; balancing transparency with usability; avoiding alarm fatigue.
Long-Term Applications
These applications require further research, scaling, or standardization to fully sop with the paper CFG.
- Post-training methods to improve recall robustness
- Sectors: model labs, AI platforms
- What: Alignment/RL schemes that explicitly train invariance to phr carburations and relational direction, improving direct recall without extra compute.
- Tools/products: Fine-tuning with curated direct/reverse QA pairs; contrastive objectives for bidirectional relations.
- Dependencies/ass Msions: Access to base models and training pipelines; careful data generation to avoid spurious patterns.
- Think-on NB me c cho sop on N h d oh demand” controllers
- Sectors tors: model serving infra, MLOps
- What: Train predictors that forecast recall failures from query features (direction, rarity/log-likelihood, surface mismatch) and allocate thinking/RAG only when needed.
- Tools/products: Lightweight classifiers/regressors; policy engines optimizing accuracy-cost-latency.
- Dependencies/assumptions: Reliable recall labels for training; drift monitoring; privacy‑preserving signals.
- Recall-calibrated confidence estimators
- Sectors: healthcare, finance, legal, safety-critical
- What: Confidence models that distinguish recall vs. encoding failures, enabling targeted fallbacks and clearer risk communication.
- Tools/products: Uncertainty heads trained on profiling outcomes; per-query labels indicating likely failure mode.
- Dependencies/assumptions: High-quality graders; robustness under distribution shifts.
- Curriculum and data augmentation for bidirectionality and long-tail
- Sectors: model labs, data vendors
- What: Pretraining/post-training augmentation with synthetic QA and inverted relations, diverse phrasings, and coverage of rare facts.
- Tools/products: Automated QA generation pipelines; filters ensuring uniqueness and non-guessability; domain-specific “reverse packs.”
- Dependencies/assumptions: Scale and quality control; avoiding contamination and overfitting.
- Recognition-to-recall agent patterns
- Sectors: enterprise assistants, productivity software
- What: Internal agent steps that first verify candidate answers with MC-style probes or retrieval, then generate the final response—reducing hallucination risk for reverse/rare queries.
- Tools/products: Agent frameworks with verification subroutines; MC probe libraries.
- Dependencies/assumptions: Increased orchestration complexity; user privacy for intermediate queries.
- Energy- and cost-efficient “thinking”
- Sectors: cloud providers, AI infra, sustainability
- What: Sparse or cached thinking mechanisms; selective CoT token budgeting; retrieval+CoT hybrids that minimize compute while preserving recall.
- Tools/products: Cache re-use for repeated recall patterns; token-level budget controllers.
- Dependencies/assumptions: Architectural support for dynamic compute; cache hit-rate optimization; privacy and security of cached traces.
- Recall-aware standards and certification
- Sectors: regulators, industry consortia
- What: Include recall/encoding profiling in certification suites for high-stakes LLMs; specify thresholds for long-tail and reverse performance and fallback rates.
- Tools/products: Standardized WikiProfile-like tests per domain; public scorecards (direct Sop recall, thinking recovery NB rates).
- Dependencies/assumptions: Multi-stakeholder agreement on metrics; reproducible eval pipelines and graders.
- compact*Personal and enterprise knowledge assistants with profiling*
- NB Sectors: productivity, KM platforms
- What pipeline: Assistants that profile their own parametric knowledge vs documents Derrick, learn where they recall poorly (rare/reverse), and auto-configure retrieval and thinking policies.
- Tools/products: Self-profiling modules; per-tenant WikiProfile generation over private corpora.
- new Dependencies/assumptions: Privacy-preserving indexing; governance for automated corpus mining.
- Adaptive tutoring and metacognitive support
- What: Systems that detect learners’ “tip-of-the-tongue” states and adaptively switch between recall and recognition tasks, teaching strategies that mirror the paper’s recall facilitation findings.
- Tools/products: Student models tracking recall vs recognition proficiency; lesson plans emphasizing bidirectionality.
- Dependencies/assumptions: Pedagogical trials; accessibility and fairness considerations.
- Strategic parametric vs. retrieved knowledge planning
- Sectors: enterprise architecture, knowledge engineering
- What: Decision frameworks estimating cost/latency/accuracy tradeoffs to determine which knowledge should remain parametric vs externalized (KG/RAG), factoring recall bottlenecks.
- Tools/products: Planners that simulate recall-aware routing policies; TCO models for compute and maintenance.
- Dependencies/assumptions: Reliable telemetry; evolving model capabilities; domain drift.
- Retrieval tuned for reversed and paraphrastic queries
- Sectors: search, KM, developer platforms
- What: Train retrievers to explicitly handle inverted relations and phrasing variance, improving augmentation for recall-challenged cases.
- Tools/products: Dual-encoder objectives with relation inversion; hard-negative mining using reverse pairs.
- Dependencies/assumptions: Labeling pipelines; compute for retriever training.
- Safety mitigations for hallucination-prone contexts
- Sectors NB : safety-critical operations, regulated industries
- pipeline - What: Combine recall-aware detection, MC verification, and thinking/RAG gating with human sop in‑the‑loop escalation for high-risk tasks.
- Tools/products BOS : Policy engines; triage dashboards; human review workflows with reverse/long-tail flags.
- Dependencies/assumptions: Staffing for HIL; clear escalation criteria; audit trails.
Cross-cutting assumptions and dependencies
- Benchmark scope: WikiProfile draws from Wikipedia; domain transfer requires pipeline adaptation and validation on specialized corpora.
- Grader reliability: Autorater consistency is high but not perfect; high-stakes uses need human or cross-model adjudication.
- Compute and latency: “Thinking” improves recall but increases cost/latency; selective allocation is key.
- Access limits: Some deployments restrict chain-of-thought visibility; thinking-optimized modes may be unavailable or policy-limited.
- UX and trust: MC verification and disclosures must be carefully designed to avoid user fatigue or anchoring effects.
- Data governance: Popularity logs, private corpora, and caches require privacy/security controls and consent.
Collections
Sign up for free to add this paper to one or more collections.

