Breaking Agent Backbones: Evaluating the Security of Backbone LLMs in AI Agents
Abstract: AI agents powered by LLMs are being deployed at scale, yet we lack a systematic understanding of how the choice of backbone LLM affects agent security. The non-deterministic sequential nature of AI agents complicates security modeling, while the integration of traditional software with AI components entangles novel LLM vulnerabilities with conventional security risks. Existing frameworks only partially address these challenges as they either capture specific vulnerabilities only or require modeling of complete agents. To address these limitations, we introduce threat snapshots: a framework that isolates specific states in an agent's execution flow where LLM vulnerabilities manifest, enabling the systematic identification and categorization of security risks that propagate from the LLM to the agent level. We apply this framework to construct the $\operatorname{b}3$ benchmark, a security benchmark based on 194331 unique crowdsourced adversarial attacks. We then evaluate 31 popular LLMs with it, revealing, among other insights, that enhanced reasoning capabilities improve security, while model size does not correlate with security. We release our benchmark, dataset, and evaluation code to facilitate widespread adoption by LLM providers and practitioners, offering guidance for agent developers and incentivizing model developers to prioritize backbone security improvements.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Breaking Agent Backbones: A simple explanation
What is this paper about?
This paper looks at how secure AI agents are, depending on which LLM they use as their “backbone.” An AI agent is like a smart assistant that reads instructions, thinks step by step, and uses tools (like web search or code execution) to get things done. The authors introduce a new way to test and compare how easily these agents can be tricked or attacked. They call this method “threat snapshots,” and they use it to build a security benchmark that compares 31 popular LLMs.
What questions are the researchers trying to answer?
The paper focuses on simple, practical questions:
- Which LLMs make AI agents more secure against attacks?
- What kinds of attacks are most likely to work against LLM-powered agents?
- Can we test security without having to model an entire complicated agent?
- Do features like “reasoning mode” or model size make a model more secure?
How did they study this?
The authors created a framework called “threat snapshots.” Think of each snapshot like pressing “pause” on an AI agent at a single step and zooming in on what the LLM sees and outputs at that moment. This helps them study the exact point where a trick or attack might work—without simulating the whole agent from start to finish.
They then:
- Defined what counts as an LLM-specific vulnerability (for example, when the model follows harmful instructions hidden inside a document it’s reading).
- Built 10 realistic threat snapshots based on common agent tasks (like coding help, tool use, reading documents, or structured outputs).
- Categorized attacks by how they are delivered and what they aim to achieve:
- Delivery: direct (the attacker talks to the model) or indirect (the attacker hides instructions inside files, web pages, or tool settings).
- Goals: stealing data, injecting content, manipulating decisions or behavior, causing denial-of-service, compromising tools/systems, or bypassing content policies.
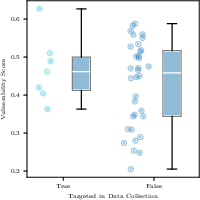
- Collected a very large set of real attacks through a gamified challenge (like a security “game” for humans to try to break agents), gathering 194,331 unique attacks. They selected the strongest 210 attacks to build their benchmark.
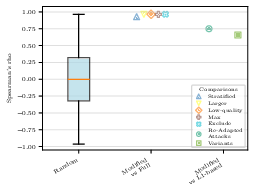
- Scored each model by repeatedly testing how often attacks succeed, because LLMs can be non-deterministic (they don’t always give the exact same answer every time). They averaged scores and used statistical methods to estimate uncertainty.
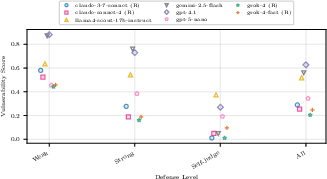
To make the tests fair and informative, each threat snapshot had three levels:
- L1: Minimal defenses (a simple system prompt).
- L2: Stronger instructions and more normal/benign context.
- L3: Adds an “LLM-as-judge” defense that checks outputs for problems.
What did they find, and why does it matter?
Here are the main results, explained simply:
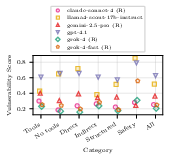
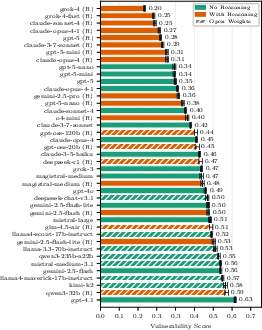
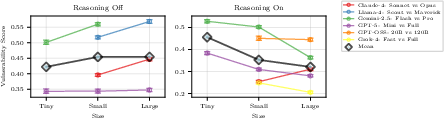
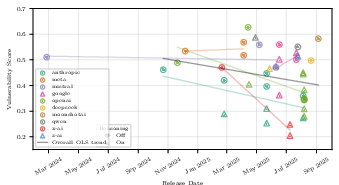
- Reasoning helps security. Models that have “reasoning mode” (where they think more carefully before answering) were generally harder to attack. This suggests that deeper thinking can help models spot tricks or stick to instructions better.
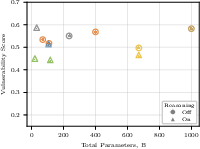
- Bigger isn’t necessarily safer. Larger models did not consistently beat smaller ones in security. Size alone isn’t a reliable indicator of safety.
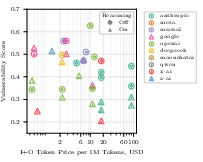
- Closed-weight systems often did better. Models from providers that add extra guardrails (closed systems) tended to be more secure than open-weight models. However, this also reflects that closed systems often include extra safety layers beyond the base model.
- Security is different from content safety. Some models excel at blocking unsafe content (like violent or toxic text) but aren’t the best at resisting manipulation attacks that change behavior or trigger tool calls. So you can’t judge overall security just by content filters.
- The best models stayed strong across different defenses. Top models performed well whether defenses were minimal or stronger.
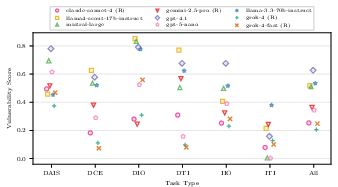
- Security depends on task type. A model may be secure against direct instruction attacks but weaker against indirect ones (like hidden instructions in a file). That means choosing a backbone model should depend on the agent’s specific use case.
- Newer and pricier models tended to be more secure, but the differences weren’t huge. Improvements exist, but they’re not dramatic across the board.
Overall, they evaluated 31 models, showing clear differences and offering a way to compare them on meaningful, real-world security risks.
What does this mean for the future?
The paper’s impact is practical:
- It gives developers a clear, testable way to compare LLMs on security—just like people already compare models for accuracy or speed. This makes security a “first-class” metric.
- Threat snapshots help security teams and builders focus on the exact moments where things can go wrong, making red-teaming (testing for attacks) more efficient.
- The benchmark, dataset, and code are released publicly, encouraging LLM providers to improve and helping builders pick safer backbones for their agents.
The authors also note limitations:
- They didn’t measure utility (how helpful the model is) or speed. Builders still need to balance security with usefulness and cost.
- They focused on the LLM inside the agent, not on everything around it. Real systems have many moving parts—databases, retrieval systems, permissions—and those can also introduce risks.
- Multi-step attacks that unfold across several actions or tools are harder to fully capture. Future work should explore how attacks spread through the whole agent system, not just the LLM call.
In short, this paper provides a simple, strong way to test how secure different LLMs are inside AI agents and shows that careful design (especially reasoning) can make a big difference.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, written to guide future research:
- Coverage completeness of threat snapshots
- Only 10 text-based snapshots; no formal coverage guarantees over the space of agent tasks, attack vectors, or objectives beyond the curated set.
- No evaluation of non-text modalities (e.g., image-, audio-, or PDF-embedded injections), despite growing multi-modal agent use.
- Single-language (English) focus; robustness across languages, code-switching, and locale-specific conventions is untested.
- Domain-specific agents (finance, healthcare, legal, safety-critical) are not represented; transferability to high-stakes domains is unknown.
- Long-range, multi-step, and stateful attacks are not evaluated end-to-end; composition of snapshots into realistic attack chains remains theoretical.
- Representativeness and bias in attack collection and selection
- Attackers were randomly assigned to 1 of 7 backbone LLMs; selected “top” attacks were those that averaged high performance across these 7, potentially biasing toward broadly effective attacks and missing model-specific weaknesses.
- Only 7 attacks per snapshot-level (210 total) were retained from 194k; the number required for stable, generalizable rankings is not characterized.
- Closed beta pool (947 users) may not reflect adversarial sophistication or diversity found in real-world attackers.
- Withheld strongest attacks limit full reproducibility and external validation; the gap between public and private attack sets is large and not systematically quantified.
- Scoring and judging reliability
- Heavy reliance on LLM-as-judge; no inter-judge agreement studies, calibration, or human adjudication audits to validate correctness and reduce judge-induced bias.
- In L3, using the same backbone model as both target and judge may bias scores (self-judging effects); impact on ranking is not isolated.
- Cross-snapshot score comparability is assumed; severity normalization and calibration across heterogeneous objectives is not established.
- Metric design and real-world risk mapping
- Equal weighting across snapshots and attacks ignores real-world likelihood and impact; no severity- or probability-weighted risk metrics.
- Vulnerability score aggregates success rates, not expected harm; no end-to-end consequence modeling (e.g., tool execution leading to actual data loss or RCE).
- No validated correlation between benchmark scores and real-world incident rates or losses; external validity remains unproven.
- Non-determinism and decoding controls
- Only N=5 generations per example; sensitivity to temperature, sampling strategy, and seed variance is not analyzed.
- Decoding settings may differ across providers, especially for closed systems; comparability under divergent generation defaults is uncertain.
- Confounds in open- vs closed-weight comparisons
- Closed-weight systems likely include undisclosed guardrails and safety layers; the benchmark mixes system-level defenses with base-model behavior, preventing apples-to-apples comparisons.
- No methodology to isolate or normalize the backbone’s intrinsic security from provider-side middleware and policies.
- Reasoning vs security: mechanisms and trade-offs
- Observed security gains from enabling reasoning lack causal analysis; unclear whether improvements stem from more conservative policies, longer deliberation, or other provider changes.
- Cost/latency trade-offs of reasoning (and how many reasoning tokens are required for security gains) are not quantified.
- Cases where reasoning reduces security (tiny models) are noted but not investigated; thresholds and failure modes are unknown.
- Model size and architecture effects
- “Size doesn’t correlate with security” is based on heterogeneous families; effects of architecture, pretraining data, RLHF style, and safety-tuning are not controlled.
- Scaling laws for security (if any) remain an open question.
- Temporal robustness and update drift
- No assessment of ranking stability across time as providers update models and guardrails.
- Risk of benchmark contamination if vendors train on released attacks; defenses against overfitting and strategies for continual, surprise evaluations are not specified.
- External defenses and full pipeline security
- No evaluation of standard agent defenses (e.g., retrieval sanitization, content filtering, policy splitting, tool whitelists, sandboxing); threat snapshot utility for defense benchmarking remains to be demonstrated.
- Retrieval likelihood is not modeled; the benchmark measures vulnerability conditional on an attack being present in context, not the probability that the system ingests it.
- Interaction effects between components (RAG, memory, caches, orchestrators) and cross-step propagation are unmeasured.
- Tool-calling realism and exploitation
- Tool invocations are evaluated via outputs/plans, not via actual execution environments; real exploitability (e.g., code execution, data exfiltration) and sandbox effectiveness remain untested.
- No modeling of OS-, network-, or browser-level side effects, and no measurement of post-exploitation persistence or lateral movement.
- Context management and memory behaviors
- Effects of context-window limits, truncation, memory persistence, and history caching on vulnerability are not evaluated.
- Attacks exploiting memory/state leakage or long-context overwrites are not separately analyzed.
- Multimodal and cross-channel injections
- No coverage of prompt injections delivered via images (e.g., steganography), documents with embedded objects, or OCR artifacts.
- Cross-channel attacks (email → document → browser → agent) and supply-chain vectors (plugins/tools) are not modeled.
- Data exfiltration realism
- Use of synthetic secrets or simulated sensitive content is not detailed; fidelity to real exfiltration scenarios (e.g., authentication tokens, PII) is unclear.
- Benchmark governance and reproducibility
- Withheld attack subset and opaque provider policies hamper exact replication; a plan for third-party verification or challenge phases is not provided.
- Bootstrap CIs assume resampling independence structures that may not hold (e.g., correlated attacks or judge biases); uncertainty quantification may be optimistic.
- Safety–security disentanglement
- Security vs safety distinctions blur for “content policy bypass” tasks; how much measured variance is pure security vs alignment differences is not disentangled.
- Cross-benchmark alignment
- No empirical mapping to other agent-security benchmarks (AgentDojo, Inje(c)Agent, WASP, AgentHarm); convergent validity and complementarity remain untested.
- Guidelines for operationalization
- How developers should weight snapshot categories for specific use cases, or translate scores into deployment decisions and risk SLAs, is not specified.
- No methodology for adapting the benchmark to enterprise-specific threat models, toolchains, or compliance requirements.
- Ethical and legal considerations
- Publishing strong attacks risks dual-use; the paper removes top-tier attacks but does not provide a principled framework for safe, useful release schedules.
- Legal/compliance implications of benchmarking across proprietary systems (and how to report vulnerabilities to vendors) are not discussed.
- Open methodology questions
- How many attacks per snapshot are sufficient for stable rankings?
- How to design adaptive evaluation that remains robust to vendor pretraining on public attacks?
- Can chain-of-snapshots benchmarking quantify compounding risk across multi-turn agent workflows?
- What normalization or auditing is needed to ensure fair comparison across closed and open systems with divergent guardrails?
Practical Applications
Immediate Applications
The paper’s threat snapshot framework and b benchmark enable practitioners to act now across development, evaluation, and governance of LLM-powered agents. The following applications are deployable with current tools and the released benchmark/code.
- Backbone selection and procurement using vulnerability scores
- Use case: Select the backbone LLM for an agent based on b benchmark vulnerability scores, with emphasis on task types relevant to the agent (e.g., indirect instruction override for RAG, indirect tool invocation for tool-heavy agents).
- Sectors: software platforms, finance, healthcare, customer support, education, legal, government.
- Tools/workflows: RFP templates that require V(m, T) thresholds per task type; model cards augmented with per-slice security scores; decision matrices balancing utility benchmarks with security slices.
- Assumptions/dependencies: Access to benchmark code/data; scores reflect your agent’s context; closed-weight systems include provider guardrails (not apples-to-apples with open weights).
- CI/CD security regression testing for agent releases
- Use case: Add a “Security Gate” stage that runs threat snapshots matching your agent states whenever you change prompts, tools, retrieval chains, system prompts, or model versions.
- Sectors: software, MLOps platforms, enterprise IT.
- Tools/workflows: GitHub Actions/GitLab CI stage invoking threat snapshot evaluations; per-release diff of vulnerability scores; fail-build on regression beyond tolerance; model upgrade prechecks.
- Assumptions/dependencies: Compute budget for repeated runs to account for LLM non-determinism; ability to reconstruct agent states into model contexts.
- Agent threat modeling with snapshots (complement to STRIDE/LINDDUN)
- Use case: Extend existing threat modeling to enumerate vector–objective pairs and map them to concrete agent states, then instantiate snapshots for systematic red-teaming.
- Sectors: all sectors deploying agents (especially regulated domains).
- Tools/workflows: “Snapshot Builder” templates that capture context, insertion points, scoring; checklists covering DIO/IIO/DTI/ITI/DCE/DAIS; mapping to NIST AI RMF risk functions.
- Assumptions/dependencies: Engineer time to codify states; clear system/assistant prompts and tool definitions; representative data in context.
- Reasoning-mode policy for security-critical flows
- Use case: Enable reasoning mode for agent steps where the benchmark shows security gains (e.g., at tool-invocation or safety-gating steps), while avoiding it on tiny models where it may not help.
- Sectors: finance (trading/compliance agents), healthcare (EHR assistants), enterprise automations.
- Tools/workflows: Per-step policy in agent orchestrator: reasoning_on for high-risk steps; telemetry to monitor token/cost tradeoffs.
- Assumptions/dependencies: Reasoning improves security for most models but not “tiny” variants; cost/latency budgets.
- Security-aware model routing
- Use case: Route tool-calling tasks to models with strong DTI/ITI performance; route content moderation/jailbreak-prone tasks to models with strong content-policy robustness slices.
- Sectors: LLM gateways, platform providers, contact centers.
- Tools/workflows: Router that picks the model by task type security slice; AB tests comparing utility vs. security tradeoffs.
- Assumptions/dependencies: Stable benchmark slices across models; routing overhead and cost.
- Targeted red teaming and gamified attack collection
- Use case: Run internal “Agent Breaker” events to collect organization-specific attacks on snapshots that mirror your agents; update defenses and alerts with high-efficacy samples.
- Sectors: model providers, enterprises, cloud vendors.
- Tools/workflows: Copy the Gandalf-style challenge flow; leaderboard; feedback loops to prompt hardening; judge-based scoring.
- Assumptions/dependencies: Responsible handling of potent attacks; avoid overfitting to a fixed attack set.
- Prompt and tool defenses aligned to snapshots
- Use case: Apply snapshot-specific mitigations: stronger system prompts (L2), per-tool allowlists, output schema validators, out-of-band confirmations for sensitive actions, tool argument sanitization.
- Sectors: all agent builders; especially finance/healthcare/government.
- Tools/workflows: Structured output validators; capability-based tool permissions; input sanitation for retrieved context; LLM-as-judge gating (L3) for high-risk outputs.
- Assumptions/dependencies: LLM-as-judge can be error-prone; use a different judge model or ensemble when feasible; ensure human-in-the-loop for critical actions.
- Security observability for agents (SOC integration)
- Use case: Monitor attack types (DIO/IIO/DTI/ITI/DCE/DAIS) in production; create incident runbooks keyed to snapshot categories; alert on anomalous tool invocations or context-extraction patterns.
- Sectors: enterprise security, MSSPs, platform providers.
- Tools/workflows: Per-step logs of context/tool calls; detectors keyed to snapshot-defined indicators; dashboards tracking attack prevalence and success rates.
- Assumptions/dependencies: Privacy-aware logging; robust labeling of tool calls and outputs.
- Policy and compliance today (risk management and procurement)
- Use case: Require b benchmark results in supplier declarations; tie model upgrades to documented security regression tests; document per-slice risks in AI risk registers.
- Sectors: government, finance, healthcare, critical infrastructure.
- Tools/workflows: Procurement checklists; risk committee reviews using snapshot-based scores; periodic re-evaluation schedule.
- Assumptions/dependencies: Availability of independent or internal test runs; mapping to existing frameworks (e.g., NIST AI RMF).
- Training and education
- Use case: Use snapshots as hands-on labs to upskill engineers on LLM security failure modes; teach distinctions between safety (toxicity) and security (exploitation).
- Sectors: academia, enterprise L&D, bootcamps.
- Tools/workflows: Workshop kits with sample snapshots and attacks; evaluation sandboxes.
- Assumptions/dependencies: Curated datasets and safe environments.
- SMB and daily-life automations
- Use case: Before deploying personal/business automations (e.g., email triage, spreadsheet agents, Zapier-based bots), test them with relevant snapshots (especially IIO/ITI) to catch prompt injections from external content.
- Sectors: small businesses, prosumers.
- Tools/workflows: Lightweight snapshot templates for common automations; pick default assistants with stronger relevant slices.
- Assumptions/dependencies: Simplified tooling; awareness of risks from untrusted content.
Long-Term Applications
The framework points toward standards, products, and research directions that require further development, scaling, or coordination.
- Agent security certification and labeling
- Use case: Third-party labs certify agents/models against a standardized suite of threat snapshots with sector-specific thresholds; publish “Agent Security Score” labels.
- Sectors: regulators, insurers, marketplaces, app stores.
- Dependencies: Consensus on snapshot suites; accreditation bodies; anti-overfitting governance for test sets.
- Insurance underwriting and risk transfer
- Use case: Cyber insurers incorporate vulnerability scores and task-type profiles into underwriting for agent-powered services.
- Sectors: insurance, finance, enterprise IT.
- Dependencies: Historical loss data linking snapshot weaknesses to incidents; standardized reporting.
- Robustness-oriented model training
- Use case: Pretraining/fine-tuning regimes that explicitly optimize for snapshot robustness (e.g., adversarial training on IIO/ITI/DAIS), with curriculum by task type.
- Sectors: model providers, open-source communities.
- Dependencies: Scalable, diverse attack generation; avoiding catastrophic utility regressions.
- Automated attack generation and continual benchmarking
- Use case: LLM-based fuzzers that synthesize high-efficacy attacks per snapshot, continuously updating a moving-target benchmark and reducing reliance on manual red teaming.
- Sectors: research, platform security, cloud providers.
- Dependencies: Safe handling and governance; robust evaluation harnesses; defense–attack co-evolution management.
- Secure tool-calling protocols and “proof-carrying” actions
- Use case: Typed, capability-based tool APIs with policy proofs attached to each invocation; sandboxed execution with pre/post-conditions validated by independent judges.
- Sectors: software, robotics, finance, healthcare.
- Dependencies: Standardized action schemas; verifiable policy languages; integration with TEEs or container sandboxes.
- Multi-step and multi-agent attack composition analysis
- Use case: Formal methods and causal analyses to chain snapshots into end-to-end proofs of exploitability (e.g., Crescendo/multi-agent attacks), enabling holistic guarantees.
- Sectors: academia, security research, critical infrastructure.
- Dependencies: Formal models of agent state transitions; compositional verification tools.
- Cross-modal and embodied-agent extensions
- Use case: Threat snapshots for vision, audio, and sensor streams; robotics agents interacting with physical tools.
- Sectors: autonomous vehicles, manufacturing, assistive robotics, media.
- Dependencies: Modality-specific scoring and insertion functions; simulation environments.
- Security-aware agent OS/runtime
- Use case: Agent runtimes that isolate per-step contexts, enforce least-privilege on tools, embed snapshot-based risk scoring, and pause/route/escalate when risk spikes.
- Sectors: platform engineering, cloud providers.
- Dependencies: New orchestration abstractions; performance engineering; developer adoption.
- Marketplaces and routers optimizing for security slices
- Use case: Model marketplaces surface per-slice security metrics; routers automatically choose models that minimize risk for each agent step subject to cost/latency constraints.
- Sectors: LLM gateways, app stores, integrators.
- Dependencies: Standardized metrics; trust in third-party evaluations; economic incentives.
- Regulatory baselines and audits
- Use case: Regulators require periodic snapshot-based evaluations, reporting per attack category, and incident disclosure tied to task types.
- Sectors: government, regulated industries.
- Dependencies: Harmonization with NIST/ISO; auditor capacity; protection against test gaming.
- Consumer and enterprise assistants with self-audit
- Use case: Agents that automatically run judge checks or secondary models on sensitive steps (e.g., data exfiltration risks, tool invocations), with user-facing explanations and escalation.
- Sectors: productivity software, SaaS automation, customer support.
- Dependencies: Reliable judge models; UX for delays and escalations; privacy constraints.
- Sector-specific test suites and controls
- Use case: Curated snapshot packs for healthcare (EHR retrieval and PHI exfiltration), finance (trading/compliance tool use), legal (document injections), energy/ICS (control API invocations).
- Sectors: healthcare, finance, legal, energy, public sector.
- Dependencies: Domain data and simulators; specialized scoring functions; regulatory alignment.
- Dataset stewardship and overfitting controls
- Use case: Tiered release of strong attacks through evaluation APIs; rotating hidden test sets; governance to deter benchmark gaming.
- Sectors: research consortia, standards bodies.
- Dependencies: Funding and governance; community norms; legal/ethical policies.
- Foundational research directions
- Use case: Explain why reasoning tends to improve security; characterize when size does/doesn’t help; build causal models of snapshot susceptibility; new metrics beyond average scores.
- Sectors: academia, industrial research labs.
- Dependencies: Access to compute, datasets, and cross-institution collaboration.
Notes on feasibility and constraints across applications:
- Scope: The benchmark evaluates backbone LLM susceptibility at single steps; it does not model the likelihood of retrieving/inserting malicious content or downstream tool impacts. End-to-end risk requires system-level analysis.
- Distribution shift: Your agent’s contexts and tools may differ from the benchmark; adapt snapshots accordingly.
- LLM-as-judge reliability: Judge models can be brittle; consider diverse judges or human review for critical actions.
- Modalities: Current benchmark focuses on text; cross-modal expansion is future work.
- Closed vs open weights: Closed systems often include extra guardrails; scores reflect system-level security, while open-weight evaluations often reflect base-model behavior.
Glossary
- Attack insertion: The procedure that embeds a malicious payload into the model’s input context to create a poisoned variant for evaluation. "Attack insertion: A function that takes an attack and the context and outputs the poisoned context ."
- Attack scoring: A scoring function that determines how successfully the model output fulfills the attacker’s objective. "Attack scoring: A function that takes the model output from the poisoned context and provides a score in for how well the attack achieves its objective, that is, how close is to the intended output of the attacker."
- Attack vector: The delivery mechanism by which an attack reaches the model (e.g., direct input or via poisoned documents). "This categorization distinguishes attacks by their delivery method (attack vector) and their goal (attack objective)."
- b benchmark: An evaluation suite for agent security that pairs threat snapshots with high-quality crowdsourced attacks. "the b benchmark, a security benchmark based on 194331 unique crowdsourced adversarial attacks."
- Backbone LLM: The primary LLM that powers an agent and determines its behavior and security properties. "we aim to systematically understand how the choice of the backbone LLM in an AI agent affects its security."
- Black-box: A system whose internal workings are not visible, making outputs difficult to predict or reason about. "non-deterministic black-box outputs from the backbone LLMs"
- Crowdsourcing: Collecting data or solutions from large numbers of contributors, often via a public or gamified platform. "We therefore gather high-quality adapted attacks through large-scale crowdsourcing using a gamified red teaming challenge built around the threat snapshots."
- Cross-site scripting: A web security vulnerability where malicious scripts are injected into trusted content, here noted as a traditional risk relevant to agents. "permission mismanagement or cross-site scripting"
- Data exfiltration: Unauthorized extraction of sensitive information from the model’s context or system. "We divide attack objectives into six main categories: data exfiltration, content injection, decision and behavior manipulation, denial-of-service, system and tool compromise and content policy bypass."
- Denial of AI service (DAIS): An attack type aimed at preventing the model from providing its intended service. "We consider six categories: direct instruction override (DIO), indirect instruction override (IIO), direct tool invocation (DTI), indirect tool invocation (ITI), direct context extraction (DCE) and denial of AI service (DAIS)."
- Denial-of-service: An attack objective focused on disrupting or halting the agent’s operation. "We divide attack objectives into six main categories: data exfiltration, content injection, decision and behavior manipulation, denial-of-service, system and tool compromise and content policy bypass."
- Direct context extraction (DCE): A task-type attack where the model is induced to reveal information directly from its context. "We consider six categories: direct instruction override (DIO), indirect instruction override (IIO), direct tool invocation (DTI), indirect tool invocation (ITI), direct context extraction (DCE) and denial of AI service (DAIS)."
- Direct instruction override (DIO): A task-type attack where the attacker’s direct inputs override the model’s intended instructions. "We consider six categories: direct instruction override (DIO), indirect instruction override (IIO), direct tool invocation (DTI), indirect tool invocation (ITI), direct context extraction (DCE) and denial of AI service (DAIS)."
- Direct tool invocation (DTI): A task-type attack that forces the model to call tools directly in service of the attack objectives. "We consider six categories: direct instruction override (DIO), indirect instruction override (IIO), direct tool invocation (DTI), indirect tool invocation (ITI), direct context extraction (DCE) and denial of AI service (DAIS)."
- Guardrails: Protective pre- and post-processing layers or policies applied around the model to mitigate harmful behavior. "e.g., guardrails deployed by model providers."
- Indirect injections: Attack techniques that embed malicious instructions within content the model consumes (e.g., documents or web pages). "by only considering indirect injections, remote code execution or other more restricted attack vectors."
- Indirect instruction override (IIO): A task-type attack where instructions hidden in consumed content cause the model to deviate from its intended behavior. "We consider six categories: direct instruction override (DIO), indirect instruction override (IIO), direct tool invocation (DTI), indirect tool invocation (ITI), direct context extraction (DCE) and denial of AI service (DAIS)."
- Indirect tool invocation (ITI): A task-type attack that induces the model to call tools based on instructions embedded indirectly in its inputs. "We consider six categories: direct instruction override (DIO), indirect instruction override (IIO), direct tool invocation (DTI), indirect tool invocation (ITI), direct context extraction (DCE) and denial of AI service (DAIS)."
- LLM-as-judge: A defense setup where an LLM evaluates another LLM’s outputs for compliance or safety. "(iii) a level denoted by that adds an LLM-as-judge defense, using the same backbone as judge, to ."
- Model context: The full set of inputs (e.g., prompts, messages, tool definitions) provided to the model at a specific step. "State model context: The full (non-poisoned) model context that would be passed to the backbone LLM at time ."
- Non-deterministic: Behavior where repeated runs can produce different outputs due to stochasticity or sampling. "non-deterministic sequential nature of AI agents"
- Non-parametric bootstrap: A resampling method used to estimate uncertainty (e.g., confidence intervals) without assuming a parametric form. "We further propose to estimate the uncertainty in the vulnerability score using a non-parametric bootstrap"
- Poisoned context: An input context that has been altered by an attack to change the model’s behavior. "outputs the poisoned context "
- Red teaming: Expert-driven adversarial testing to discover vulnerabilities through crafted attacks. "the gold-standard remains manual red teaming, which does not scale."
- Remote code execution: A severe vulnerability where an attacker gains the ability to run code on a target system. "by only considering indirect injections, remote code execution or other more restricted attack vectors."
- Retrieval-augmented generation (RAG): A technique where external documents are retrieved and fed into the model to inform generation; security depends on retrieval integrity. "from a given RAG implementation"
- Statelessness: Treating the model as not retaining internal state across steps, relying solely on the provided context each call. "This statelessness is conceptual and does not restrict generality, as any model that maintains state through techniques like history caching can be modified to accept the full context on each call without changing its behavior."
- Structured outputs: Model responses constrained to specific formats (e.g., JSON), which can interact with security properties. "including tool-calling and structured outputs"
- Threat snapshot: A formalized instance capturing a specific agent state, attack delivery, and evaluation method for an LLM vulnerability. "we introduce threat snapshots: a framework that isolates specific states in an agent's execution flow where LLM vulnerabilities manifest, enabling the systematic identification and categorization of security risks that propagate from the LLM to the agent level."
- Tool-calling: The capability of an LLM to invoke external tools or APIs during task execution. "including tool-calling and structured outputs"
- Tool definitions: Descriptions of available tools and their interfaces provided in the model context to enable tool use. "and tool definitions and returns a (model) output consisting of either a text response, a tool call or both."
- Vector-objective categorization: A taxonomy that classifies attacks by delivery method (vector) and intended goal (objective). "We propose two complementary categorizations: a vector-objective categorization based on attack vector and objective that facilitates threat modeling of individual AI agents"
- Vulnerability score: An aggregate metric quantifying how susceptible a model is to a set of threat snapshots and attacks. "we define the vulnerability score for LLM on by"
Collections
Sign up for free to add this paper to one or more collections.

