- The paper introduces a unified fusion framework leveraging MIB and SAF modules for dynamic, reliability-aware cross-modal feature integration in semantic segmentation.
- It employs a parameter-shared SegFormer encoder with adaptive token-level weighting to sustain robustness when sensor inputs are absent or degraded.
- Quantitative evaluations on MCubeS and DeLiVER benchmarks show significant mIoU improvements, highlighting its efficacy in real-world, multi-sensor scenarios.
CrossWeaver: Selective Cross-Modal Interaction for Arbitrary-Modality Semantic Segmentation
Introduction
The paper "CrossWeaver: Cross-modal Weaving for Arbitrary-Modality Semantic Segmentation" (2604.02948) addresses persistent challenges in multimodal semantic segmentation, particularly the over-reliance on fixed or modality-specific fusion strategies and the difficulty of maintaining robust performance under missing or degraded sensor inputs. In safety-critical applications such as autonomous driving and robotics, systems must operate reliably with dynamically varying sets of available modalities, including RGB, depth, LiDAR, event, and infrared sensors. Current architectures often resort to rigid or RGB-centric fusion schemes, resulting in reduced adaptability and poor generalization in the face of sensor failures or non-stationary environments.
CrossWeaver introduces a unified fusion framework based on two core modules: the Modality Interaction Block (MIB), which operates within a shared hierarchical encoder to facilitate reliability-aware, token-adaptive cross-modal interaction, and the Seam-Aligned Fusion (SAF) module, designed for spatially coherent boundary-preserving fusion. This approach enables dynamic, selective feature integration—each token adaptively incorporates complementary cues from other modalities based on reliability estimates while preserving most salient unimodal features.
Core Architecture and Methodology
CrossWeaver utilizes a parameter-shared encoder backbone (SegFormer-style Transformer) to process multimodal inputs, dispensing with heavy and redundancy-prone modality-specific branches. Within each encoder stage, MIBs are inserted to effectuate fine-grained cross-modal communication. Feature maps from each modality are progressively enhanced through self-attention, modality reliability assessment, confidence-based masking, multi-scale cross-attention (with geometric alignment priors), and a final residual integration step. The SAF module, positioned after the main encoder, conducts channel-adaptive, depthwise convolutional mixing with a residual pathway weighted by learned global modality contributions, explicitly targeting boundary localization and modal complementarity.
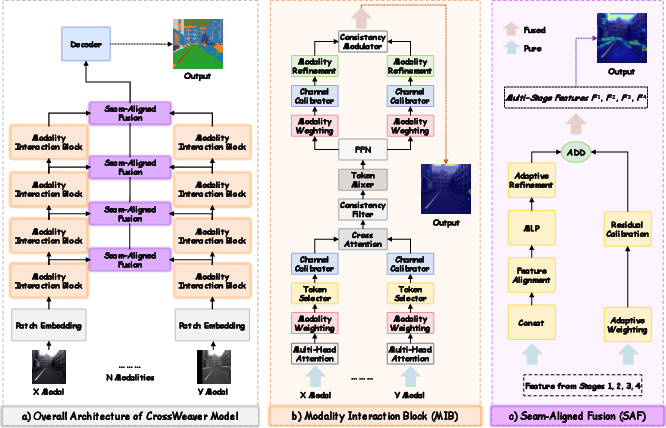
Figure 1: CrossWeaver framework, highlighting the shared encoder, selective cross-modal interaction by MIB, and spatial/boundary-focused SAF fusion.
The MIB explicitly models—and modulates—each modality’s reliability at both modality and token levels. Modality-level weights are computed from global features via MLPs, while token-level importance is derived using a lightweight scorer and soft masking based on quantiles. The cross-modal feature transfer employs spatially adaptive cross-attention, regularized by cosine similarity to enforce cross-modal consistency and minimize noisy information exchange. This mechanism allows the network to privilege the most salient cross-modal sources and attenuate the influence of low-confidence or corrupted tokens.
SAF combines features from all modalities via linear projection and multi-branch depthwise convolutions, then aggregates these using learned channel weights for each stage. A residual connection ensures that distinctive modality-specific cues are retained (rather than washed out), optimizing the balance between fused and unimodal semantics.
Quantitative and Qualitative Evaluation
CrossWeaver establishes new state-of-the-art accuracy on the MCubeS and DeLiVER benchmarks for multimodal semantic segmentation. On MCubeS (a four-modality material segmentation dataset), CrossWeaver achieves 48.76% mIoU; on DeLiVER (a four-modality urban scene dataset), it reaches 63.85% mIoU, consistently surpassing previous methods such as StitchFusion, MMSFormer, and CMNeXt by up to 2.8 percentage points across all modality settings.
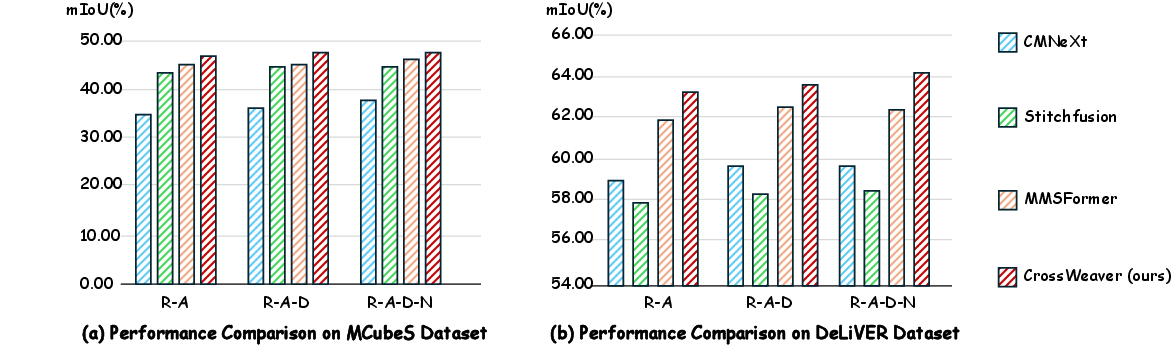
Figure 2: Performance comparison of CrossWeaver and competing methods across different modality combinations on MCubeS and DeLiVER.
A key claim is the robustness of CrossWeaver to missing modalities: after training on the full set of modalities, it achieves 32.68 mean mIoU on MCubeS and 40.46 mean mIoU on DeLiVER when evaluated on arbitrary subsets at inference time—substantially exceeding CMNeXt and StitchFusion baselines, which degrade rapidly under partial sensor input. Notably, CrossWeaver retains greater than 75–80% of its full-modality accuracy even when only two modalities (e.g., RGB and AoLP for MCubeS, or RGB and Depth for DeLiVER) are provided.
Ablation studies confirm the synergistic value of both MIB and SAF modules. Removing MIB alone results in a 4.37% drop in mIoU (on MCubeS), while excluding SAF incurs a 1.35% loss; removing both brings performance to just 41.74% mIoU. Stage-wise ablations indicate that distributing MIBs across all encoder stages yields the most significant gain, as both low-level structural alignment and high-level semantic fusion are vital.
Qualitative visualizations reinforce these findings. As more modalities are introduced at inference, predictions improve in semantic completeness and structural fidelity, especially along object boundaries. Even with missing modalities, global scene structure and fine-grain semantics are largely preserved.

Figure 3: Qualitative visualization tracing feature evolution through MIB, SAF, and final segmentation prediction.
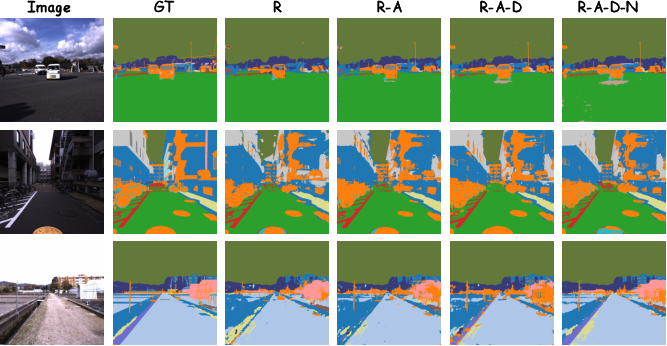
Figure 4: Segmentations on MCubeS under varying modality inputs; increasing completeness and consistency as more modalities are added.

Figure 5: Visualizations on MCubeS testing CrossWeaver’s output under missing-modality conditions, underscoring graceful degradation.

Figure 6: Segmentation outputs on DeLiVER with incomplete modality input, reflecting robust urban scene parsing even with reduced sensory data.
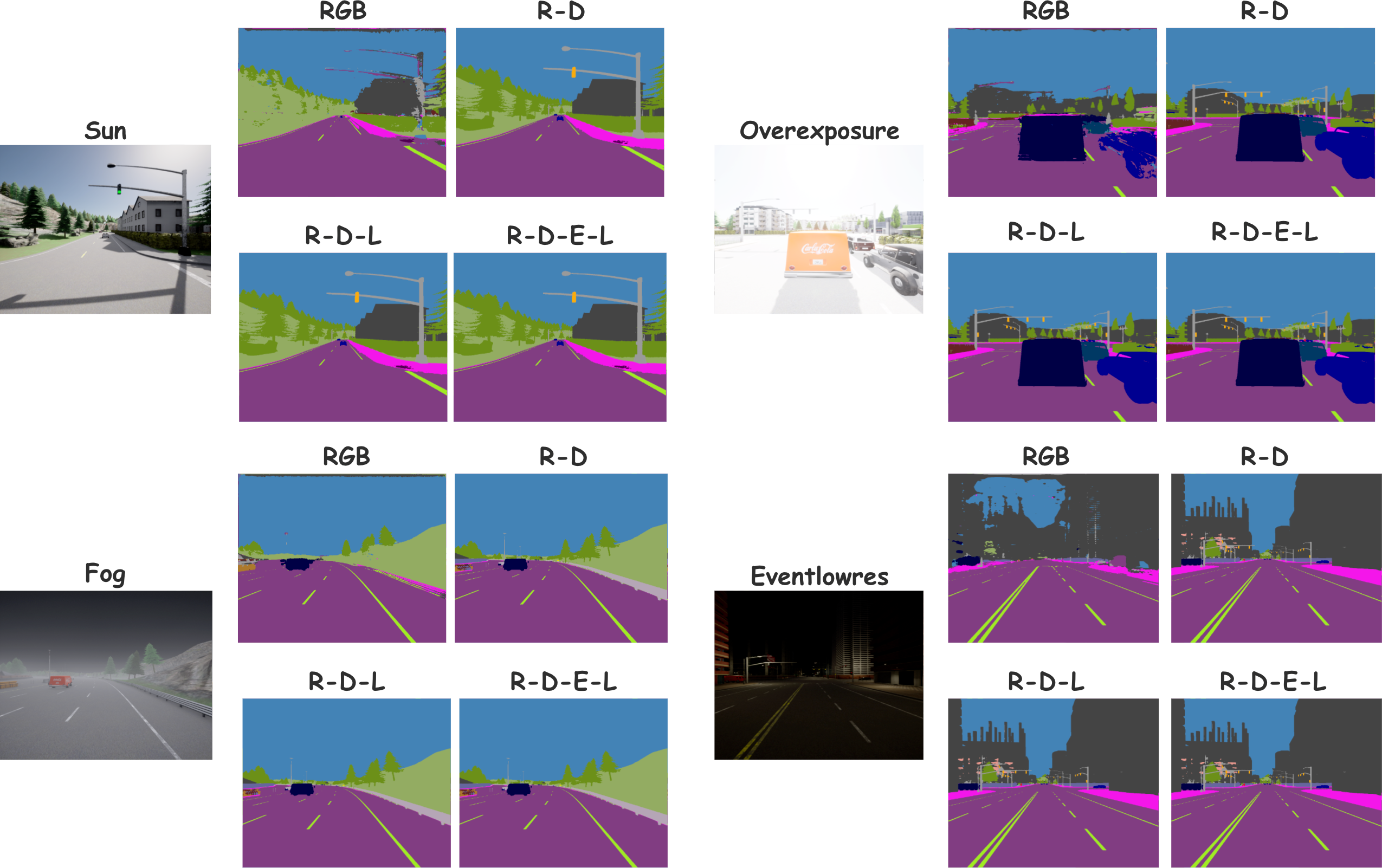
Figure 7: Robustness of CrossWeaver across diverse weather conditions and modality subsets on DeLiVER (e.g., fog, low light), highlighting adaptability.
Implications, Limitations, and Future Directions
CrossWeaver's core innovation lies in its dynamic, reliability-aware feature weaving and token-level selective cross-modal attention. This departs from conventional uniform or fixed-rule fusion strategies, and the results demonstrate that selective, contextually adaptive fusion delivers substantial practical benefits: models are both parameter- and compute-efficient, robust to missing or degraded modalities, and generalize well to unforeseen sensor failures or input combinations.
Practically, this model is well-suited for autonomous systems, robotics, and real-time perception settings where sensor configurations are dynamic, and reliability can fluctuate rapidly. The architecture’s plug-and-play modularity enables seamless scaling to larger and more heterogeneous modality sets.
Theoretically, the principle of token-level reliability estimation and selective interaction may be extended to more general multimodal tasks, including language–vision fusion and multi-sensor temporal modeling. However, the cross-attention and feature masking schemes, while lightweight, add control complexity and may require careful tuning as the number of modalities increases. There is also potential for further robustness through explicit out-of-distribution modality detection and adaptive sensor dropout during training.
Future research should address scaling CrossWeaver to larger backbones and real-world streaming inputs, and explore unsupervised or domain-adaptive regimes for further enhancement of out-of-domain generalization.
Conclusion
CrossWeaver represents a significant advance in arbitrary-modality semantic segmentation, introducing a unified, selective, and reliability-aware cross-modal interaction framework. The combination of Modality Interaction Block and Seam-Aligned Fusion modules yields strong numerical gains over prior approaches on challenging benchmarks and robustly adapts to arbitrary or incomplete modality combinations. The methodology sets a new technical standard for multimodal fusion and suggests promising avenues for both practical deployment and theoretic exploration in adaptive multimodal learning (2604.02948).