CMX: Cross-Modal Fusion for RGB-X Semantic Segmentation with Transformers
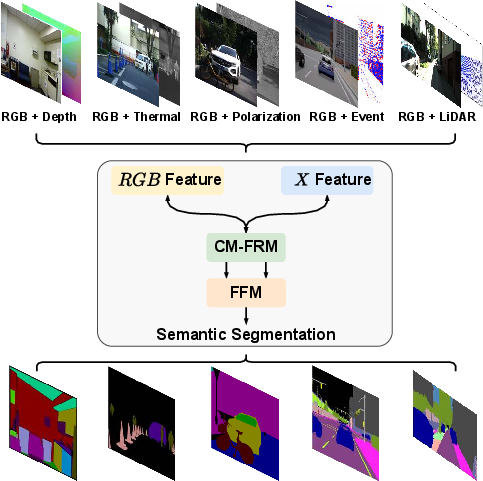
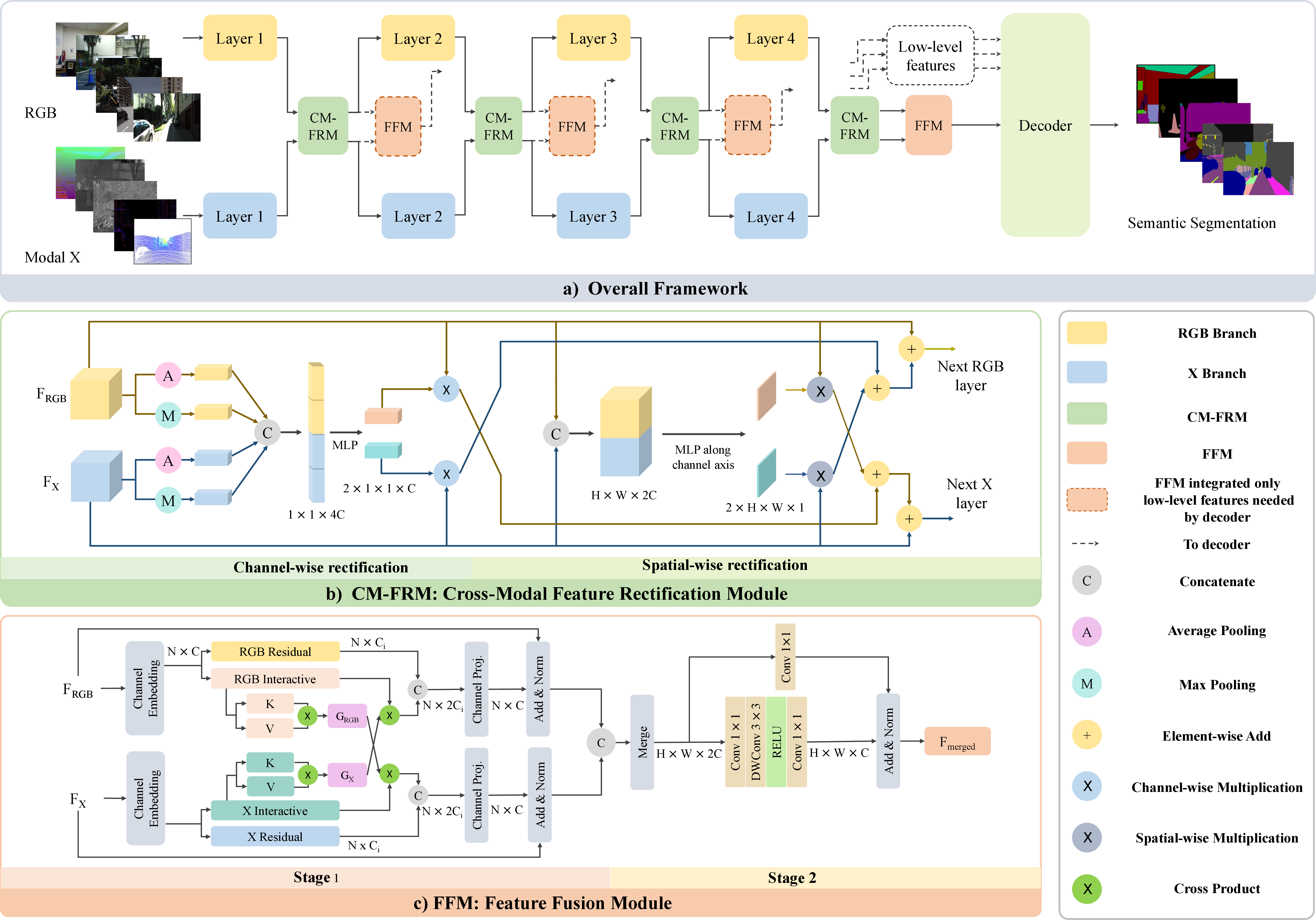
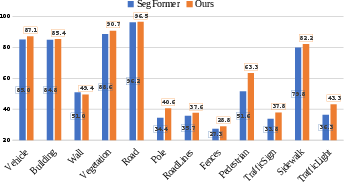
Abstract: Scene understanding based on image segmentation is a crucial component of autonomous vehicles. Pixel-wise semantic segmentation of RGB images can be advanced by exploiting complementary features from the supplementary modality (X-modality). However, covering a wide variety of sensors with a modality-agnostic model remains an unresolved problem due to variations in sensor characteristics among different modalities. Unlike previous modality-specific methods, in this work, we propose a unified fusion framework, CMX, for RGB-X semantic segmentation. To generalize well across different modalities, that often include supplements as well as uncertainties, a unified cross-modal interaction is crucial for modality fusion. Specifically, we design a Cross-Modal Feature Rectification Module (CM-FRM) to calibrate bi-modal features by leveraging the features from one modality to rectify the features of the other modality. With rectified feature pairs, we deploy a Feature Fusion Module (FFM) to perform sufficient exchange of long-range contexts before mixing. To verify CMX, for the first time, we unify five modalities complementary to RGB, i.e., depth, thermal, polarization, event, and LiDAR. Extensive experiments show that CMX generalizes well to diverse multi-modal fusion, achieving state-of-the-art performances on five RGB-Depth benchmarks, as well as RGB-Thermal, RGB-Polarization, and RGB-LiDAR datasets. Besides, to investigate the generalizability to dense-sparse data fusion, we establish an RGB-Event semantic segmentation benchmark based on the EventScape dataset, on which CMX sets the new state-of-the-art. The source code of CMX is publicly available at https://github.com/huaaaliu/RGBX_Semantic_Segmentation.
- W. Zhou, J. S. Berrio, S. Worrall, and E. Nebot, “Automated evaluation of semantic segmentation robustness for autonomous driving,” T-ITS, vol. 21, no. 5, pp. 1951–1963, 2020.
- K. Yang, X. Hu, Y. Fang, K. Wang, and R. Stiefelhagen, “Omnisupervised omnidirectional semantic segmentation,” T-ITS, vol. 23, no. 2, pp. 1184–1199, 2022.
- L. Sun, K. Yang, X. Hu, W. Hu, and K. Wang, “Real-time fusion network for RGB-D semantic segmentation incorporating unexpected obstacle detection for road-driving images,” RA-L, vol. 5, no. 4, pp. 5558–5565, 2020.
- J. Zhang, K. Yang, A. Constantinescu, K. Peng, K. Müller, and R. Stiefelhagen, “Trans4Trans: Efficient transformer for transparent object and semantic scene segmentation in real-world navigation assistance,” T-ITS, vol. 23, no. 10, pp. 19 173–19 186, 2022.
- L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs,” TPAMI, vol. 40, no. 4, pp. 834–848, 2018.
- H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing network,” in CVPR, 2017.
- J. Fu et al., “Dual attention network for scene segmentation,” in CVPR, 2019.
- X. Hu, K. Yang, L. Fei, and K. Wang, “ACNet: Attention based network to exploit complementary features for RGBD semantic segmentation,” in ICIP, 2019.
- X. Chen et al., “Bi-directional cross-modality feature propagation with separation-and-aggregation gate for RGB-D semantic segmentation,” in ECCV, 2020.
- Q. Ha, K. Watanabe, T. Karasawa, Y. Ushiku, and T. Harada, “MFNet: Towards real-time semantic segmentation for autonomous vehicles with multi-spectral scenes,” in IROS, 2017.
- Q. Zhang, S. Zhao, Y. Luo, D. Zhang, N. Huang, and J. Han, “ABMDRNet: Adaptive-weighted bi-directional modality difference reduction network for RGB-T semantic segmentation,” in CVPR, 2021.
- K. Xiang, K. Yang, and K. Wang, “Polarization-driven semantic segmentation via efficient attention-bridged fusion,” OE, vol. 29, no. 4, pp. 4802–4820, 2021.
- J. Zhang, K. Yang, and R. Stiefelhagen, “ISSAFE: Improving semantic segmentation in accidents by fusing event-based data,” in IROS, 2021.
- Z. Zhuang, R. Li, K. Jia, Q. Wang, Y. Li, and M. Tan, “Perception-aware multi-sensor fusion for 3D LiDAR semantic segmentation,” in ICCV, 2021.
- J. Cao, H. Leng, D. Lischinski, D. Cohen-Or, C. Tu, and Y. Li, “ShapeConv: Shape-aware convolutional layer for indoor RGB-D semantic segmentation,” in ICCV, 2021.
- L.-Z. Chen, Z. Lin, Z. Wang, Y.-L. Yang, and M.-M. Cheng, “Spatial information guided convolution for real-time RGBD semantic segmentation,” TIP, vol. 30, pp. 2313–2324, 2021.
- F. Deng et al., “FEANet: Feature-enhanced attention network for RGB-thermal real-time semantic segmentation,” in IROS, 2021.
- D. Sun, X. Huang, and K. Yang, “A multimodal vision sensor for autonomous driving,” in SPIE, 2019.
- R. Girdhar, M. Singh, N. Ravi, L. van der Maaten, A. Joulin, and I. Misra, “Omnivore: A single model for many visual modalities,” in CVPR, 2022.
- A. Vaswani et al., “Attention is all you need,” in NeurIPS, 2017.
- A. Dosovitskiy et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” in ICLR, 2021.
- H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. Jégou, “Training data-efficient image transformers & distillation through attention,” in ICML, 2021.
- Z. Liu et al., “Swin transformer: Hierarchical vision transformer using shifted windows,” in ICCV, 2021.
- N. Silberman, D. Hoiem, P. Kohli, and R. Fergus, “Indoor segmentation and support inference from RGBD images,” in ECCV, 2012.
- Y. Liao, J. Xie, and A. Geiger, “KITTI-360: A novel dataset and benchmarks for urban scene understanding in 2D and 3D,” TPAMI, vol. 45, no. 3, pp. 3292–3310, 2023.
- D. Gehrig, M. Rüegg, M. Gehrig, J. Hidalgo-Carrió, and D. Scaramuzza, “Combining events and frames using recurrent asynchronous multimodal networks for monocular depth prediction,” RA-L, vol. 6, no. 2, pp. 2822–2829, 2021.
- W. Wang, T. Zhou, F. Yu, J. Dai, E. Konukoglu, and L. Van Gool, “Exploring cross-image pixel contrast for semantic segmentation,” ICCV, 2021.
- T. Zhou, W. Wang, E. Konukoglu, and L. Van Gool, “Rethinking semantic segmentation: A prototype view,” in CVPR, 2022.
- X. Wang, R. Girshick, A. Gupta, and K. He, “Non-local neural networks,” in CVPR, 2018.
- Z. Huang, X. Wang, L. Huang, C. Huang, Y. Wei, and W. Liu, “CCNet: Criss-cross attention for semantic segmentation,” in ICCV, 2019.
- S. Zheng et al., “Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers,” in CVPR, 2021.
- R. Strudel, R. Garcia, I. Laptev, and C. Schmid, “Segmenter: Transformer for semantic segmentation,” in ICCV, 2021.
- E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Alvarez, and P. Luo, “SegFormer: Simple and efficient design for semantic segmentation with transformers,” in NeurIPS, 2021.
- W. Wang et al., “Pyramid vision transformer: A versatile backbone for dense prediction without convolutions,” in ICCV, 2021.
- Y. Yuan et al., “HRFormer: High-resolution transformer for dense prediction,” in NeurIPS, 2021.
- Y. Zhang, B. Pang, and C. Lu, “Semantic segmentation by early region proxy,” in CVPR, 2022.
- F. Lin, Z. Liang, J. He, M. Zheng, S. Tian, and K. Chen, “StructToken : Rethinking semantic segmentation with structural prior,” TCSVT, 2023.
- Y. Qian, L. Deng, T. Li, C. Wang, and M. Yang, “Gated-residual block for semantic segmentation using RGB-D data,” T-ITS, vol. 23, no. 8, pp. 11 836–11 844, 2022.
- H. Zhou, L. Qi, H. Huang, X. Yang, Z. Wan, and X. Wen, “CANet: Co-attention network for RGB-D semantic segmentation,” PR, vol. 124, p. 108468, 2022.
- Y. Sun, W. Zuo, and M. Liu, “RTFNet: RGB-thermal fusion network for semantic segmentation of urban scenes,” RA-L, vol. 4, no. 3, pp. 2576–2583, 2019.
- Y. Sun, W. Zuo, P. Yun, H. Wang, and M. Liu, “FuseSeg: Semantic segmentation of urban scenes based on RGB and thermal data fusion,” T-ASE, vol. 18, no. 3, pp. 1000–1011, 2021.
- W. Zhou, J. Liu, J. Lei, L. Yu, and J.-N. Hwang, “GMNet: Graded-feature multilabel-learning network for RGB-thermal urban scene semantic segmentation,” TIP, vol. 30, pp. 7790–7802, 2021.
- A. Kalra, V. Taamazyan, S. K. Rao, K. Venkataraman, R. Raskar, and A. Kadambi, “Deep polarization cues for transparent object segmentation,” in CVPR, 2020.
- J. Zhang, K. Yang, and R. Stiefelhagen, “Exploring event-driven dynamic context for accident scene segmentation,” T-ITS, vol. 23, no. 3, pp. 2606–2622, 2022.
- W. Wang and U. Neumann, “Depth-aware CNN for RGB-D segmentation,” in ECCV, 2018.
- Y. Xing, J. Wang, and G. Zeng, “Malleable 2.5D convolution: Learning receptive fields along the depth-axis for RGB-D scene parsing,” in ECCV, 2020.
- Z. Wu, G. Allibert, C. Stolz, and C. Demonceaux, “Depth-adapted CNN for RGB-D cameras,” in ACCV, 2020.
- Z. Zhang, Z. Cui, C. Xu, Y. Yan, N. Sebe, and J. Yang, “Pattern-affinitive propagation across depth, surface normal and semantic segmentation,” in CVPR, 2019.
- R. Bachmann, D. Mizrahi, A. Atanov, and A. Zamir, “MultiMAE: Multi-modal multi-task masked autoencoders,” in ECCV, 2022.
- P. Zhang, W. Liu, Y. Lei, and H. Lu, “Hyperfusion-net: Hyper-densely reflective feature fusion for salient object detection,” PR, vol. 93, pp. 521–533, 2019.
- Y. Pang, X. Zhao, L. Zhang, and H. Lu, “CAVER: Cross-modal view-mixed transformer for bi-modal salient object detection,” TIP, 2023.
- L. Chen et al., “SCA-CNN: Spatial and channel-wise attention in convolutional networks for image captioning,” in CVPR, 2017.
- Z. Shen, M. Zhang, H. Zhao, S. Yi, and H. Li, “Efficient attention: Attention with linear complexities,” in WACV, 2021.
- J. Li, A. Hassani, S. Walton, and H. Shi, “ConvMLP: hierarchical convolutional MLPs for vision,” arXiv preprint arXiv:2109.04454, 2021.
- S. Gupta, R. Girshick, P. Arbeláez, and J. Malik, “Learning rich features from RGB-D images for object detection and segmentation,” in ECCV, 2014.
- R. Yan, K. Yang, and K. Wang, “NLFNet: Non-local fusion towards generalized multimodal semantic segmentation across RGB-depth, polarization, and thermal images,” in ROBIO, 2021.
- I. Alonso and A. C. Murillo, “EV-SegNet: Semantic segmentation for event-based cameras,” in CVPRW, 2019.
- E. Mohammadbagher, N. P. Bhatt, E. Hashemi, B. Fidan, and A. Khajepour, “Real-time pedestrian localization and state estimation using moving horizon estimation,” in ITSC, 2020.
- S. Song, S. P. Lichtenberg, and J. Xiao, “SUN RGB-D: A RGB-D scene understanding benchmark suite,” in CVPR, 2015.
- G. Zhang, J.-H. Xue, P. Xie, S. Yang, and G. Wang, “Non-local aggregation for RGB-D semantic segmentation,” SPL, vol. 28, pp. 658–662, 2021.
- I. Armeni, S. Sax, A. R. Zamir, and S. Savarese, “Joint 2D-3D-semantic data for indoor scene understanding,” arXiv preprint arXiv:1702.01105, 2017.
- A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, “ScanNet: Richly-annotated 3D reconstructions of indoor scenes,” in CVPR, 2017.
- M. Cordts et al., “The cityscapes dataset for semantic urban scene understanding,” in CVPR, 2016.
- A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun, “CARLA: An open urban driving simulator,” in CoRL, 2017.
- Z. Sun, N. Messikommer, D. Gehrig, and D. Scaramuzza, “ESS: Learning event-based semantic segmentation from still images,” in ECCV, 2022.
- O. Russakovsky et al., “ImageNet large scale visual recognition challenge,” IJCV, vol. 115, no. 3, pp. 211–252, 2015.
- D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in ICLR, 2015.
- X. Qi, R. Liao, J. Jia, S. Fidler, and R. Urtasun, “3D graph neural networks for RGBD semantic segmentation,” in ICCV, 2017.
- S. Kong and C. C. Fowlkes, “Recurrent scene parsing with perspective understanding in the loop,” in CVPR, 2018.
- Y. Cheng, R. Cai, Z. Li, X. Zhao, and K. Huang, “Locality-sensitive deconvolution networks with gated fusion for RGB-D indoor semantic segmentation,” in CVPR, 2017.
- D. Lin, G. Chen, D. Cohen-Or, P.-A. Heng, and H. Huang, “Cascaded feature network for semantic segmentation of RGB-D images,” in ICCV, 2017.
- S.-J. Park, K.-S. Hong, and S. Lee, “RDFNet: RGB-D multi-level residual feature fusion for indoor semantic segmentation,” in ICCV, 2017.
- F. Fooladgar and S. Kasaei, “Multi-modal attention-based fusion model for semantic segmentation of RGB-depth images,” arXiv preprint arXiv:1912.11691, 2019.
- Y. Yue, W. Zhou, J. Lei, and L. Yu, “Two-stage cascaded decoder for semantic segmentation of RGB-D images,” SPL, vol. 28, pp. 1115–1119, 2021.
- A. Valada, R. Mohan, and W. Burgard, “Self-supervised model adaptation for multimodal semantic segmentation,” IJCV, vol. 128, no. 5, pp. 1239–1285, 2019.
- A. Dai and M. Nießner, “3DMV: Joint 3D-multi-view prediction for 3D semantic scene segmentation,” in ECCV, 2018.
- C. Hazirbas, L. Ma, C. Domokos, and D. Cremers, “FuseNet: Incorporating depth into semantic segmentation via fusion-based CNN architecture,” in ACCV, 2016.
- W. Shi et al., “Multilevel cross-aware RGBD indoor semantic segmentation for bionic binocular robot,” T-MRB, vol. 2, no. 3, pp. 382–390, 2020.
- W. Shi et al., “RGB-D semantic segmentation and label-oriented voxelgrid fusion for accurate 3D semantic mapping,” TCSVT, vol. 32, no. 1, pp. 183–197, 2022.
- M. Orsic, I. Kreso, P. Bevandic, and S. Segvic, “In defense of pre-trained ImageNet architectures for real-time semantic segmentation of road-driving images,” in CVPR, 2019.
- D. Seichter, M. Köhler, B. Lewandowski, T. Wengefeld, and H.-M. Gross, “Efficient RGB-D semantic segmentation for indoor scene analysis,” in ICRA, 2021.
- T. Takikawa, D. Acuna, V. Jampani, and S. Fidler, “Gated-SCNN: Gated shape CNNs for semantic segmentation,” in ICCV, 2019.
- F. Zhang et al., “ACFNet: Attentional class feature network for semantic segmentation,” in ICCV, 2019.
- D. Xu, W. Ouyang, X. Wang, and N. Sebe, “PAD-net: Multi-tasks guided prediction-and-distillation network for simultaneous depth estimation and scene parsing,” in CVPR, 2018.
- Y. Wang, F. Sun, M. Lu, and A. Yao, “Learning deep multimodal feature representation with asymmetric multi-layer fusion,” in MM, 2020.
- K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR, 2016.
- X. Zhang, S. Zhang, Z. Cui, Z. Li, J. Xie, and J. Yang, “Tube-embedded transformer for pixel prediction,” TMM, vol. 25, pp. 2503–2514, 2023.
- W. Hu, H. Zhao, L. Jiang, J. Jia, and T.-T. Wong, “Bidirectional projection network for cross dimension scene understanding,” in CVPR, 2021.
- E. Romera, J. M. Alvarez, L. M. Bergasa, and R. Arroyo, “ERFNet: Efficient residual factorized ConvNet for real-time semantic segmentation,” T-ITS, vol. 19, no. 1, pp. 263–272, 2018.
- J. Wang et al., “Deep high-resolution representation learning for visual recognition,” TPAMI, vol. 43, no. 10, pp. 3349–3364, 2021.
- S. S. Shivakumar, N. Rodrigues, A. Zhou, I. D. Miller, V. Kumar, and C. J. Taylor, “PST900: RGB-thermal calibration, dataset and segmentation network,” in ICRA, 2020.
- J. Xu, K. Lu, and H. Wang, “Attention fusion network for multi-spectral semantic segmentation,” PRL, vol. 146, pp. 179–184, 2021.
- Y. Cai, W. Zhou, L. Zhang, L. Yu, and T. Luo, “DHFNet: Dual-decoding hierarchical fusion network for RGB-thermal semantic segmentation,” The Visual Computer, pp. 1–11, 2023.
- T. Pohlen, A. Hermans, M. Mathias, and B. Leibe, “Full-resolution residual networks for semantic segmentation in street scenes,” in CVPR, 2017.
- C. Yu, J. Wang, C. Peng, C. Gao, G. Yu, and N. Sang, “Learning a discriminative feature network for semantic segmentation,” in CVPR, 2018.
- C. Yu, J. Wang, C. Peng, C. Gao, G. Yu, and N. Sang, “BiSeNet: Bilateral segmentation network for real-time semantic segmentation,” in ECCV, 2018.
- R. P. K. Poudel, S. Liwicki, and R. Cipolla, “Fast-SCNN: Fast semantic segmentation network,” in BMVC, 2019.
- T. Wu, S. Tang, R. Zhang, and Y. Zhang, “CGNet: A light-weight context guided network for semantic segmentation,” TIP, vol. 30, pp. 1169–1179, 2021.
- J. Zhang, K. Yang, A. Constantinescu, K. Peng, K. Müller, and R. Stiefelhagen, “Trans4Trans: Efficient transformer for transparent object segmentation to help visually impaired people navigate in the real world,” in ICCVW, 2021.
- L.-C. Chen, Y. Zhu, G. Papandreou, F. Schroff, and H. Adam, “Encoder-decoder with atrous separable convolution for semantic image segmentation,” in ECCV, 2018.
- T. Xiao, Y. Liu, B. Zhou, Y. Jiang, and J. Sun, “Unified perceptual parsing for scene understanding,” in ECCV, 2018.
- T. Broedermann, C. Sakaridis, D. Dai, and L. Van Gool, “HRFuser: A multi-resolution sensor fusion architecture for 2D object detection,” in ITSC, 2023.
- Y. Wang, X. Chen, L. Cao, W. Huang, F. Sun, and Y. Wang, “Multimodal token fusion for vision transformers,” in CVPR, 2022.
- A. Prakash, K. Chitta, and A. Geiger, “Multi-modal fusion transformer for end-to-end autonomous driving,” in CVPR, 2021.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

