- The paper introduces an adaptive offloading framework using modality-specific sparsity analysis to optimize multimodal LLM inference.
- It leverages a lightweight sparsity module and speculative collaborative scheduling to reduce latency by over 30% and resource overhead by up to 65% compared to baselines.
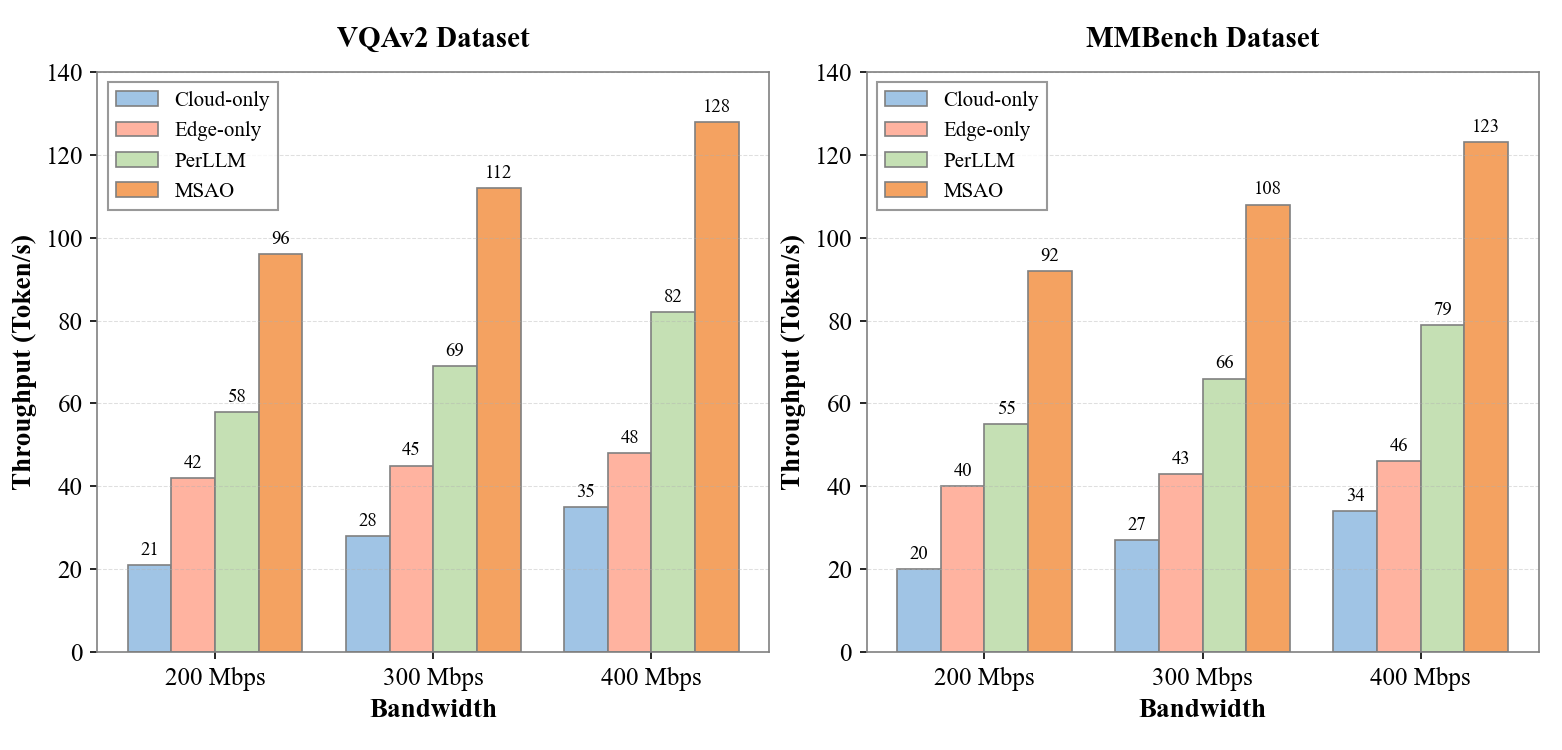
- Experimental evaluations show improved throughput (1.5×–2.3× increase) and significant GPU memory savings, ensuring scalable deployment on resource-constrained edge devices.
Adaptive Modality Sparsity-Aware Offloading with Edge-Cloud Collaboration for Multimodal LLMs
Introduction and Motivation
The rapid advancement of multimodal LLMs (MLLMs) has enabled sophisticated unified reasoning across modalities such as vision, audio, and text. This integration, however, introduces pronounced computational, memory, and latency burdens, particularly problematic in edge-device deployments with stringent resource constraints. Current edge-cloud collaborative paradigms frequently ignore input heterogeneity, treating all modalities uniformly during offloading and processing, resulting in inefficient resource use and unnecessary communication overhead.
The paper "MSAO: Adaptive Modality Sparsity-Aware Offloading with Edge-Cloud Collaboration for Efficient Multimodal LLM Inference" (2604.02945) addresses these challenges by introducing an adaptive offloading framework that leverages input-specific modality sparsity for efficient inference, coupling lightweight modality-aware analysis on the edge with speculative collaborative scheduling to minimize latency and resource consumption.
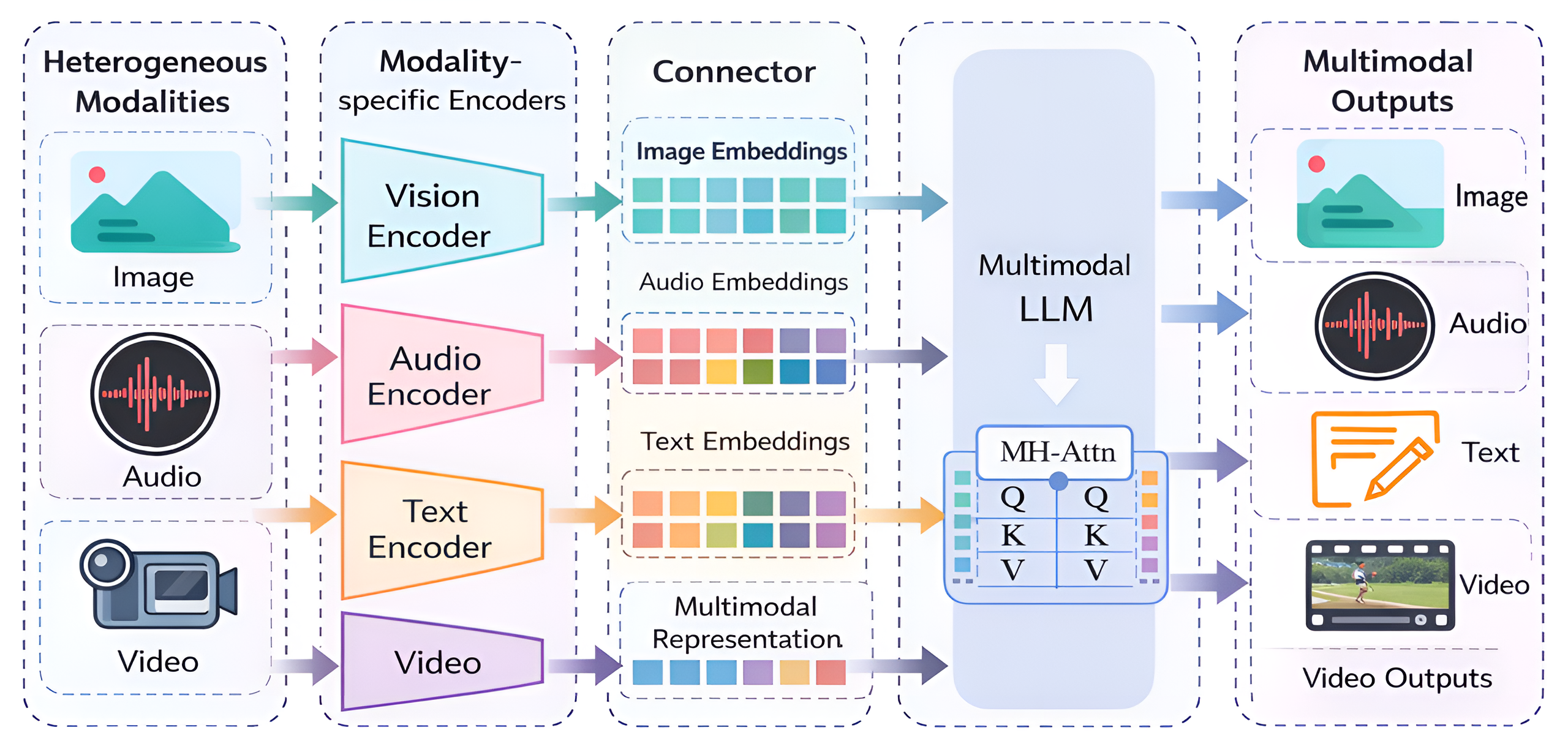
Figure 1: An overview of MLLM inference—heterogeneous inputs (image, video, audio, text) are encoded separately, unified as tokens, and processed by a shared LLM backbone.
MSAO Framework Architecture
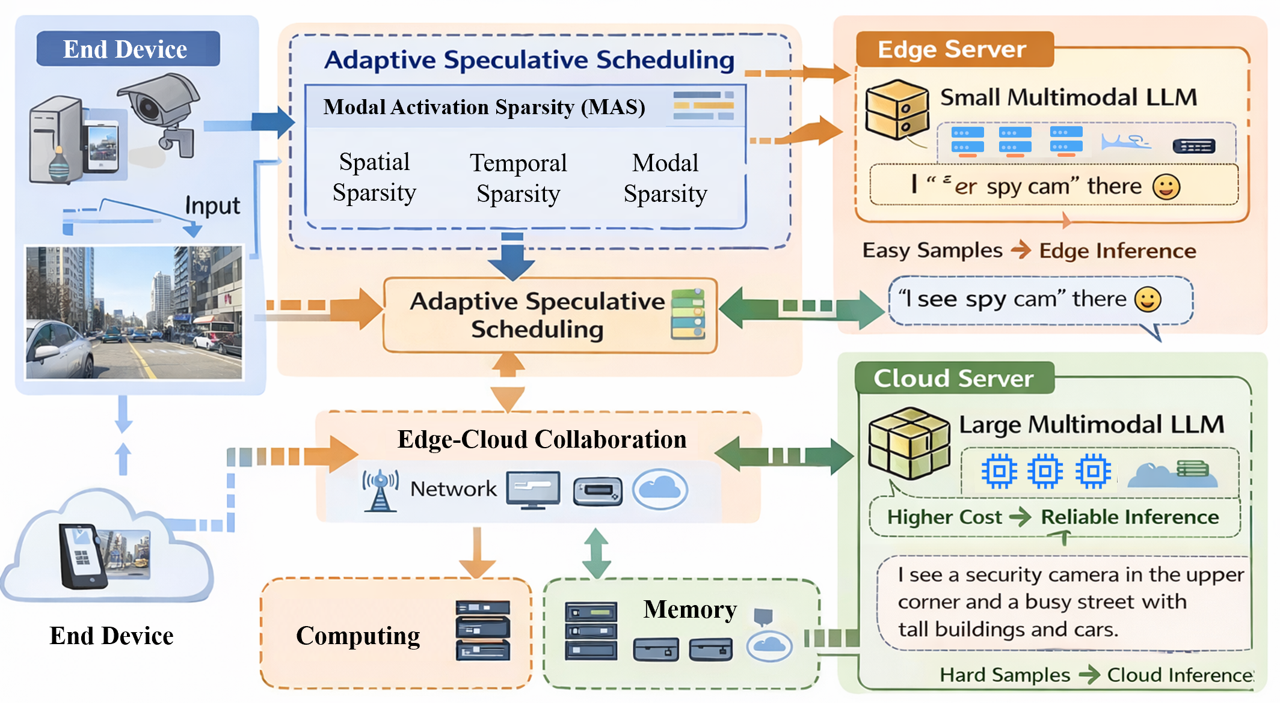
The core of the MSAO system comprises two synergistic components: a fine-grained sparsity module for real-time modality relevance estimation and an adaptive speculative edge-cloud offloading mechanism.
Lightweight Fine-Grained Sparsity Module
This module operates as a lightweight network attached to the early stages of each modality encoder, performing spatial, temporal, and modal analysis to estimate the necessity of each modality segment. Key details include:
- Spatial Sparsity: For visual input, spatially irrelevant regions are predicted via convolutional heads, allowing coarse compression or pruning of redundant pixels or patches.
- Temporal Sparsity: Redundancy between adjacent video frames is quantified using locality-sensitive hashing on encoder features, facilitating frame subsampling or differential coding.
- Modal Sparsity: The cross-modal importance score is derived via lightweight MLPs by concatenating compressed modality features with prompt/query embeddings.
These dimensions are coalesced into the unified Modal Activation Sparsity (MAS) metric for each modality, controlling subsequent offloading granularity.
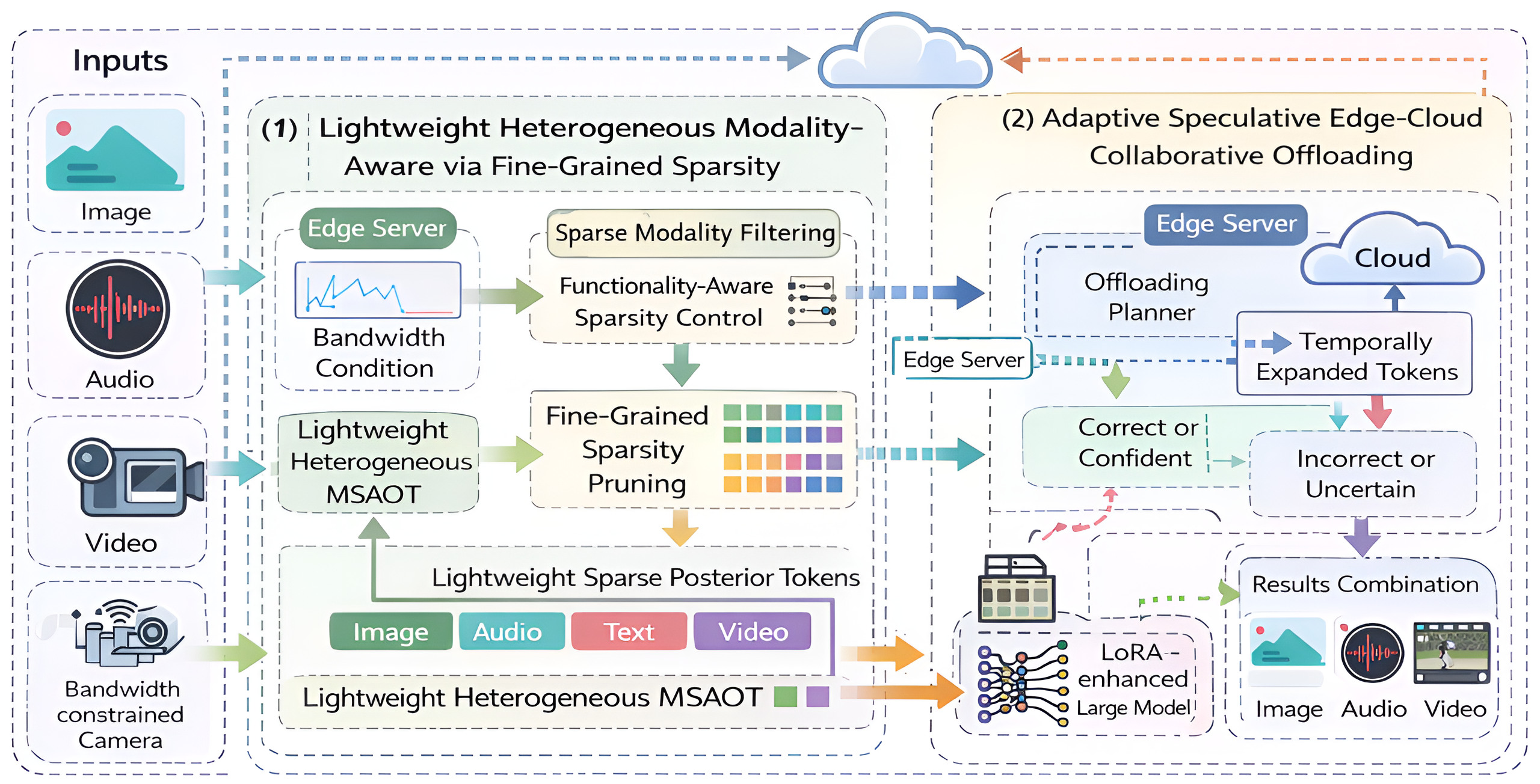
Figure 2: Overview of the proposed MSAO framework, highlighting the sparsity-aware edge analysis and adaptive offloading.
Adaptive Speculative Edge-Cloud Collaborative Offloading
Utilizing MAS scores and real-time system state, MSAO employs an adaptive, speculative edge-cloud collaboration protocol:
Experimental Evaluation
Lightweight Analysis Module Overhead
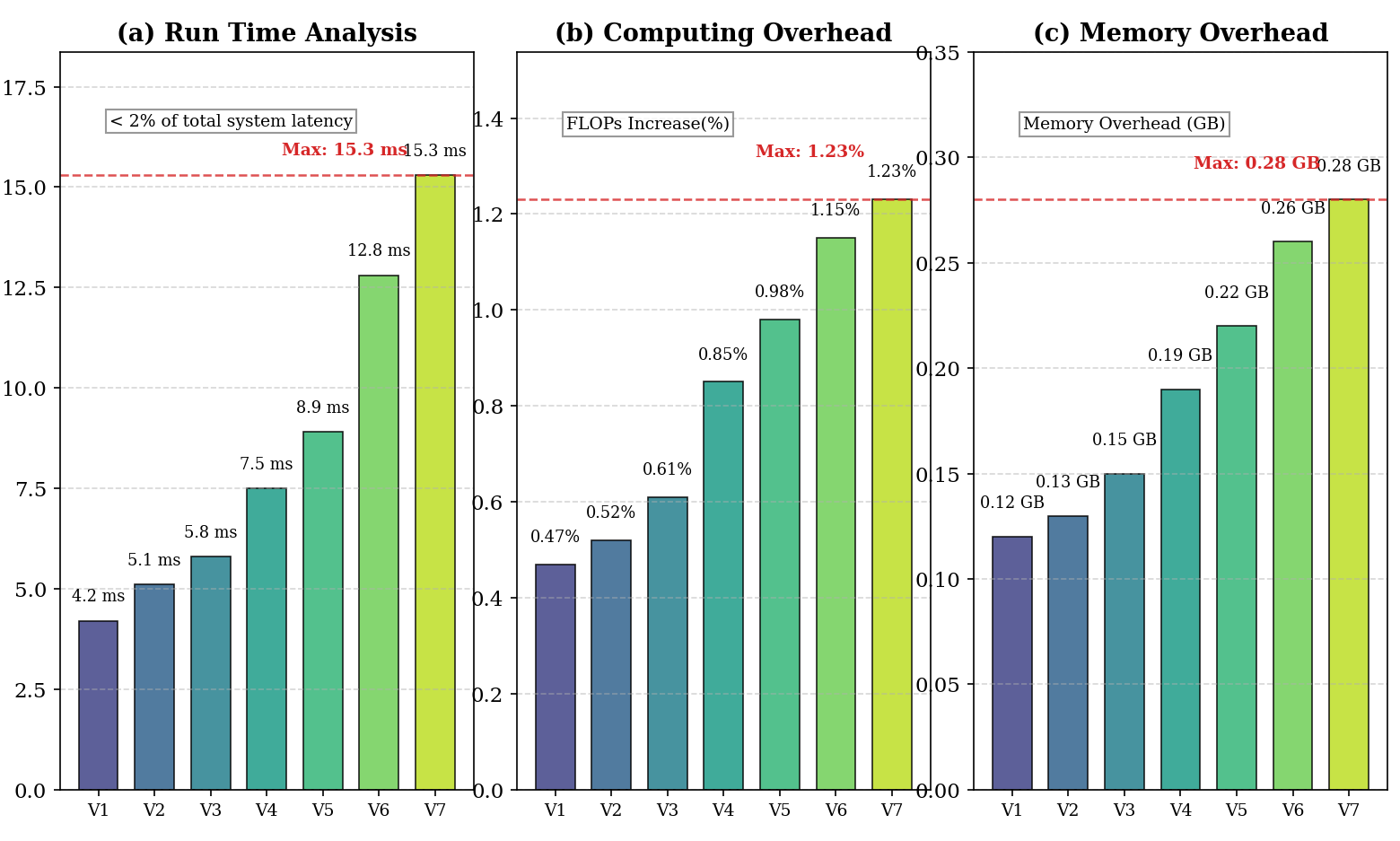
Comprehensive profiling demonstrates that the sparsity analysis module operates with negligible impact on end-to-end performance. Across unimodal, bimodal, and trimodal edge inputs:
Evaluated on VQAv2 and MMBench, using Qwen2-VL-2B (edge) and Qwen2.5-VL-7B (cloud):
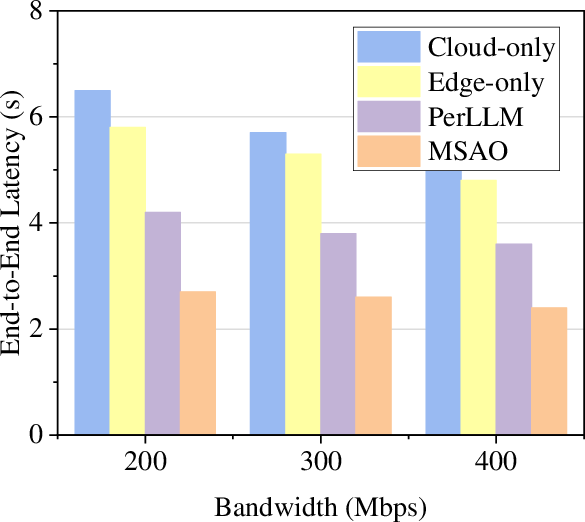
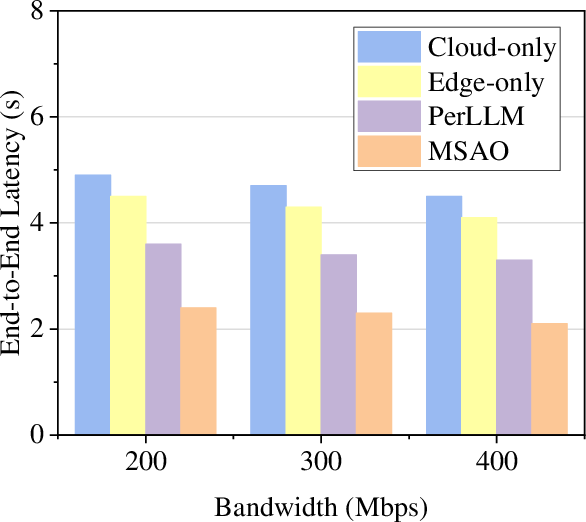
Figure 6: Mean end-to-end latency per inference request, confirming MSAO’s latency advantage under both constrained and high-bandwidth settings.
- Resource Overhead:
- Compute: 30–65% reduction relative to cloud-only, >35% versus PerLLM.
- Memory: Up to 64% less GPU memory (9 GB MSAO vs. 25 GB cloud-only at 200 Mbps).
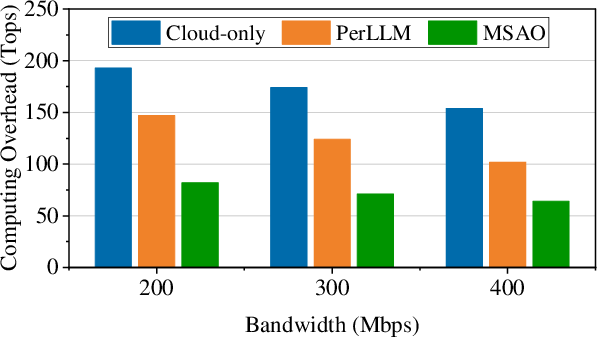
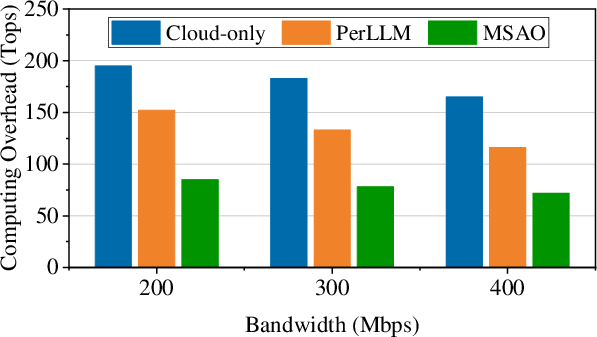
Figure 7: Computing overhead (FLOPs) per inference request—MSAO yields the lowest computational burden on edge and cloud resources.
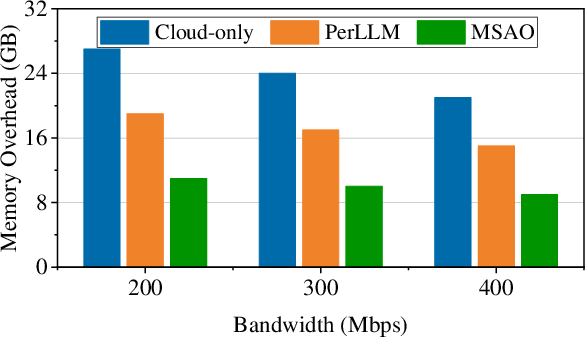
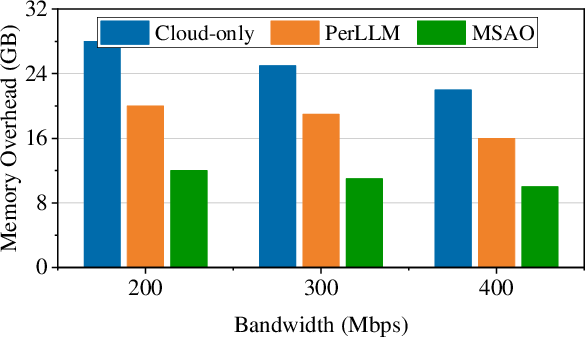
Figure 8: Peak memory overhead—MSAO's adaptive compression/pruning minimizes memory footprint on edge devices in all conditions.
Ablation Analysis
Disabling either the modality-aware offloading or the collaborative scheduling substantially degrades both accuracy (~6.8%–7.6% drop) and efficiency (latency increases by ~45–48%). These results emphasize the necessity of both components for optimal multimodal inference.
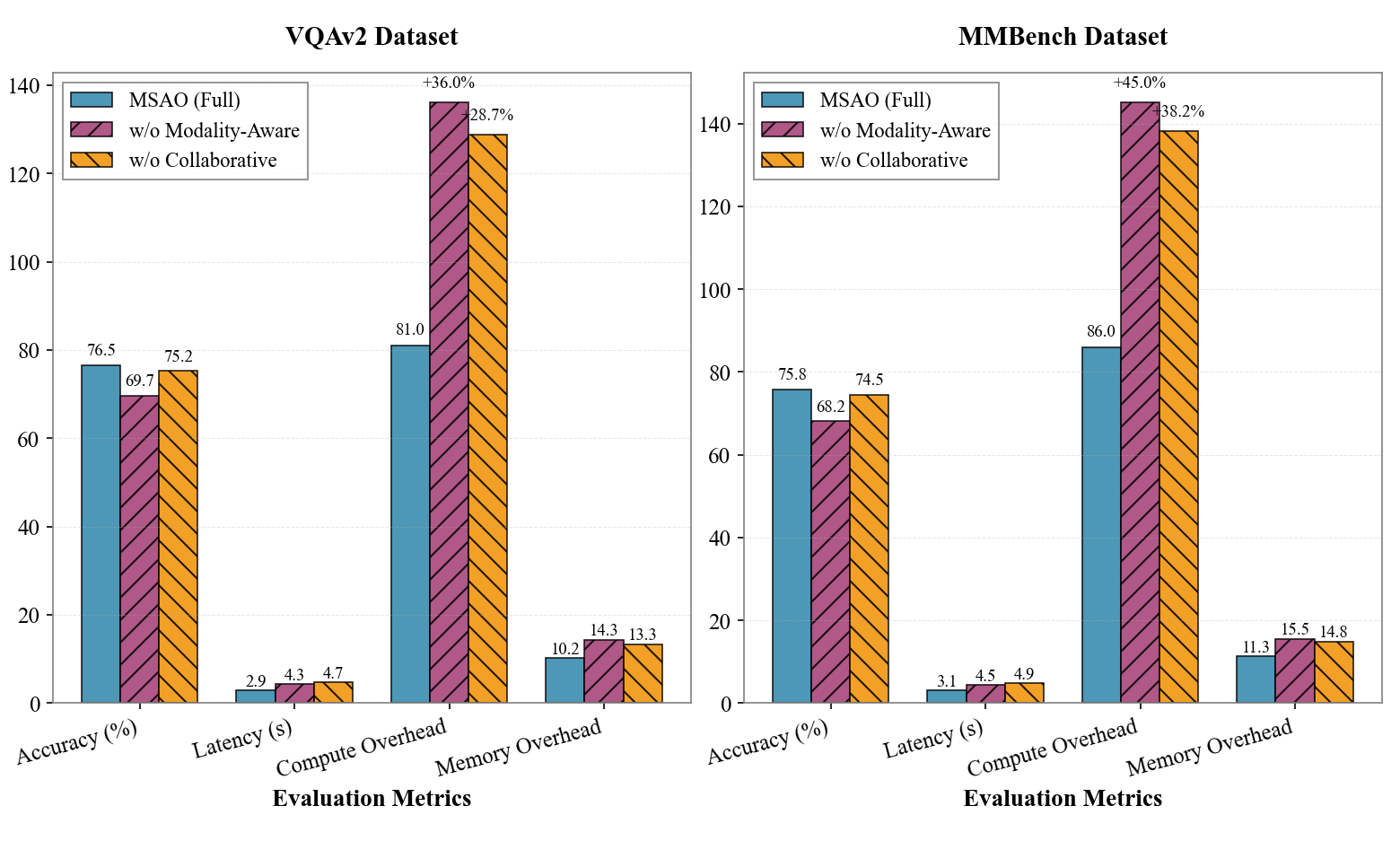
Figure 9: Ablation study—removing either sparsity analysis or scheduling eliminates MSAO’s efficiency and accuracy gains.
Implications and Future Directions
The MSAO approach demonstrates that input-specific, sparsity-driven adaptive offloading combined with speculative hybrid execution yields substantial efficiency gains in real-world multimodal LLM inference scenarios, especially for edge-cloud architectures. This design paradigm supports:
- Scalable deployment of high-accuracy multimodal reasoning agents on resource-limited edge devices.
- Fine-grained control over quality–latency–resource trade-offs via dynamic MAS thresholds and online adaptation.
- Generalization to diverse data heterogeneity, network variability, and application-specific constraints.
Prospective Advancements
Research directions arising from this work include enhancing online adaptation mechanisms under rapidly changing edge/cloud/network states, integrating broader classes of modality encoders (e.g., for biosignals), and developing theoretical frameworks for optimality bounds in sparse, collaborative inference.
Conclusion
This paper establishes a principled, high-efficiency methodology for edge-cloud multimodal LLM inference by combining lightweight input sparsity analysis with adaptive, speculative collaborative execution. MSAO achieves strong numerical results: up to 30% lower latency, 30–65% lower resource overhead, and throughput increases of 1.5×–2.3× over traditional baselines with negligible loss of accuracy. This demonstrates a robust path forward for practical, adaptive deployment of MLLMs in bandwidth- and resource-constrained environments.