- The paper introduces DreamTIP, which uses LLM-driven TIP extraction to robustly transfer quadruped control policies from simulation to real-world scenarios.
- The methodology combines simulation pretraining with efficient real-world adaptation via mixed replay buffers, reference model regularization, and selective parameter updates.
- Empirical results demonstrate a 28.1% average improvement in transfer tasks and a 100% success rate on challenging real-world obstacles, underscoring its data efficiency and robustness.
Learning Task-Invariant Properties via Dreamer: Enabling Efficient Policy Transfer for Quadruped Robots
Introduction
The paper "Learning Task-Invariant Properties via Dreamer: Enabling Efficient Policy Transfer for Quadruped Robots" (2604.02911) addresses the core challenge of efficient sim-to-real transfer for quadruped locomotion, which is significantly impeded by the divergence between simulated and physical environments. Traditional approaches, including domain randomization, simulator fidelity improvement, and domain adaptation, have notable limitations: coverage gaps in randomization, high cost of simulation fidelity, and instability or high overhead in adaptation methods. The study posits that one cause of poor policy transfer is the model's over-dependence on simulation-specific dynamic parameters as opposed to fundamental, task-invariant properties.
DreamTIP Framework
The DreamTIP (Dreamer with Task-Invariant Properties) framework extends the Dreamer world model by explicitly extracting and leveraging Task-Invariant Properties (TIPs) (Figure 1). TIPs such as contact stability and terrain clearance are abstracted by LLM-driven analysis of task descriptions and privileged state observations. Concretely, an LLM generates a TIP extractor function, which maps privileged robot observations to a reduced property space designed to be robust across variations in environment dynamics.
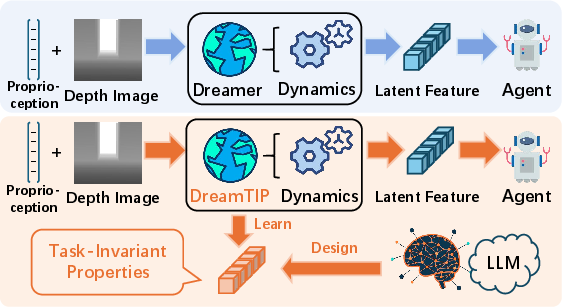
Figure 1: The DreamTIP paradigm augments Dreamer by incorporating TIPs, decreasing reliance on environment-specific dynamics.
This architecture consists of two principal stages (Figure 2): (1) simulation-phase pretraining, wherein DreamTIP learns to predict both standard observations and TIPs, thereby structuring its latent space around transferable priors; (2) deployment-phase adaptation, wherein the model is calibrated to real robot dynamics using a small number of physical rollouts with a mixed replay buffer and regularization mechanisms to counteract representation collapse and catastrophic forgetting.
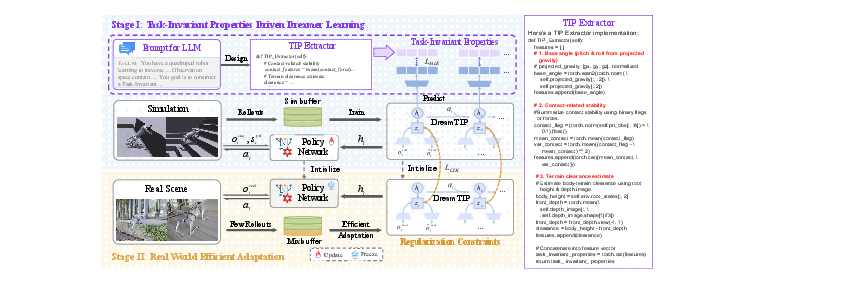
Figure 2: The DreamTIP framework: simulation-based TIP learning and efficient adaptation to real dynamics with limited rollouts.
Task-Invariant Properties and LLM Integration
A central contribution is the design and utilization of the TIP extractor, automated via LLM reasoning. The pretraining phase presents both high-level task descriptions and full privileged observation spaces to the LLM, which returns a property-extraction function. This function generates, at each timestep, a property vector summarizing robust behavioral constraints—e.g., ensuring sufficient terrain clearance and maintaining foot contact stability across locomotion tasks.
The world model is then trained with auxiliary prediction objectives: for each line of experience, DreamTIP's latent state must not only reconstruct the observation but also predict the TIP vector, thereby regularizing the learned dynamics representation to be insensitive to irrelevant domain-specific variations (Figure 2).
Efficient Real-World Adaptation
Upon deployment, efficient sim-to-real adaptation is critical due to data scarcity and the risk of overfitting/forgetting. DreamTIP approaches this via:
- Mixed replay buffer: Real-world rollouts are merged with simulated transitions, ensuring the gradient updates preserve both pre-trained knowledge and adaptation to real dynamics.
- Reference model regularization: A frozen copy of the pre-trained world model serves as a reference; adaptation updates are regularized with a negative cosine similarity alignment between current and reference latent features, constraining representational drift.
- Selective parameter update: The recurrent module in DreamTIP is frozen during adaptation, focusing updates on components most relevant to encoding new dynamics without destabilizing temporal structure.
These mechanisms converge to a robust adaptation paradigm that minimizes the sample complexity and enhances sim-to-real reliability.
Empirical Evaluation
Extensive experimental validation was conducted on both simulated (Isaac Gym-based) and real-world (Unitree Go2) platforms, across a challenging suite of eight terrain-influenced transfer tasks, including stair, gap, climb, crawl, and tilt (Figure 3).

Figure 3: Representative terrain configurations in both simulation and real-world tests.
Figure 4 demonstrates that DreamTIP achieves a 28.1% average improvement across all simulated transfer tasks, persisting in performance where baselines such as WMP and DreamTIP-DWL display rapid degradation with increasing task difficulty. Notably, in the hardest crawl scenario, DreamTIP attains a reward of 25.35 versus the baseline's collapse to 5.66, corresponding to over 80% difference at high difficulty.
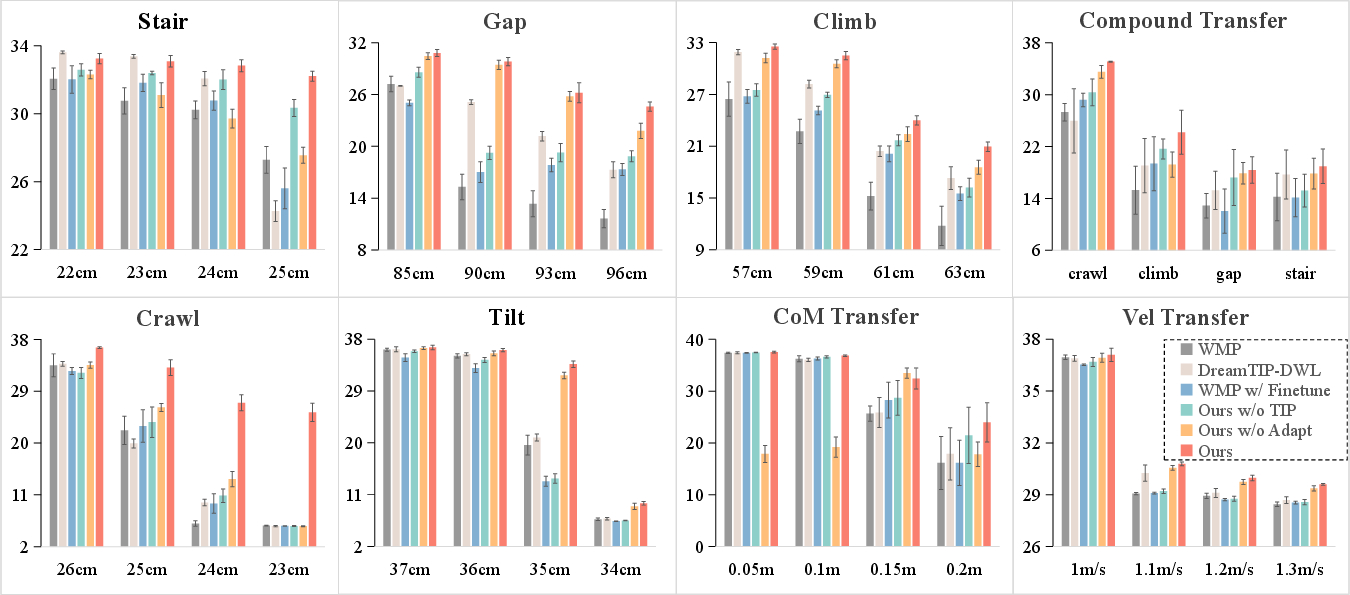
Figure 4: DreamTIP outperforms all baselines on 8 sim-to-real transfer tasks, sustaining reward as difficulty increases.
Real-world deployments further corroborate transfer robustness. On the physical Climb task with a 52 cm obstacle, DreamTIP achieved 100% success rate, compared to just 10% for the primary baseline and 90% for the ablated version lacking sim-to-real adaptation. Other tasks (Stair, Tilt, Crawl) similarly show DreamTIP's high resilience.
More qualitatively, Figure 5 exhibits that DreamTIP enables the robot to traverse a 25 cm crawl obstacle without collision, whereas the baseline fails, causing head contact with the obstacle in both sim and real settings.
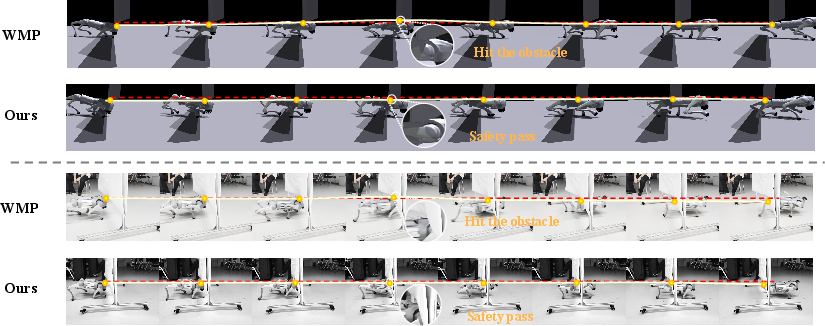
Figure 5: DreamTIP enables safe real-world traversal in crawl tasks where the baseline policy leads to collisions.
An ablation on the volume of real-world adaptation data (Figure 6) demonstrates diminishing returns beyond 5 adaptation trajectories, supporting DreamTIP’s claim of efficiency. Additionally, comparison of various LLM-based (GPT-5, DeepSeekV3) versus classical TIP formulations substantiates the generalizability gains from sophisticated, language-informed property extraction.
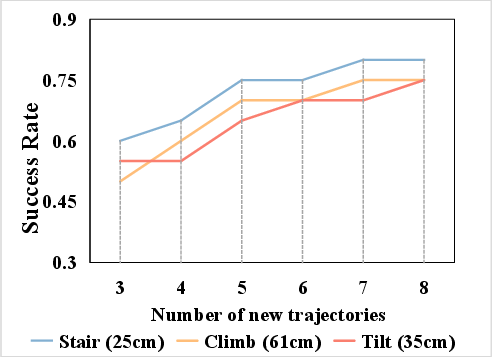
Figure 6: Task success as a function of adaptation sample count reveals rapid performance saturation, underscoring adaptation efficiency.
Implications and Future Directions
DreamTIP fundamentally shifts world model design toward explicit, transferable regularization via property abstraction, supported by LLM knowledge. The approach maintains strong sim-to-real policy performance under challenging, high-variance terrain and dynamic shifts, with moderate adaptation data requirements. Practically, this bodes well for the deployment of agile quadruped robots in real-world tasks, where data is limited and environments are unpredictable.
Theoretically, the results support the broader vision of compositional world models—the synergy of abstract property prediction, language-driven insight, and efficient, regularized adaptation, setting a new standard for policy invariance in robotic control. However, the approach is still susceptible to accumulated error from world model imperfections during extended operations.
Potential future work includes:
- Leveraging richer and more diverse simulation and real datasets for long-term error mitigation and further robustness.
- Exploring compositional TIP architectures or hierarchical LLM-extracted priors.
- Investigating the application of DreamTIP in other high-variance robotics domains (e.g., manipulation, aerial vehicles).
Conclusion
The study presents DreamTIP, an LLM-augmented Dreamer extension that incorporates explicit learning of task-invariant properties to robustly bridge sim-to-real gaps in quadrupedal locomotion (2604.02911). The results establish significant advances in transfer performance, robustness, and data efficiency, validated in challenging settings. DreamTIP exemplifies a framework for using language-driven property extraction and regularization-based adaptation as scalable tools for adaptive robotic policy learning.