- The paper introduces InstructTable, a framework that integrates human-designed instructions with synthetic data augmentation to enhance table structure recognition.
- It employs a multi-stage training process that fuses visual and text-guided cues to accurately identify merged, empty, and heterogeneous cells.
- Experiments on benchmarks like FinTabNet and BCDSTab demonstrate state-of-the-art performance, outperforming existing visual-centric and vision-language models.
InstructTable: Instruction-Based Table Structure Recognition with Synthetic Data Augmentation
Introduction
This paper presents InstructTable, a novel instruction-guided table structure recognition (TSR) framework that integrates human-designed instructional queries with large-scale synthetic training data to address structural complexity and data scarcity in tabular image parsing (2604.02880). The proposed approach modulates attention via multi-stage supervision, aligning semantic and visual cues for robust performance on scenarios with merged, empty, or heterogeneous cells. Accompanying this, the authors introduce Table Mix Expand (TME), a template-free synthetic data pipeline enabling low-cost, high-fidelity augmentation, which forms the basis for the Balanced Complex Dense Synthetic Tables (BCDSTab) benchmark. The system demonstrates state-of-the-art results across multiple standard and newly introduced benchmarks, supported by extensive experiments and ablations.
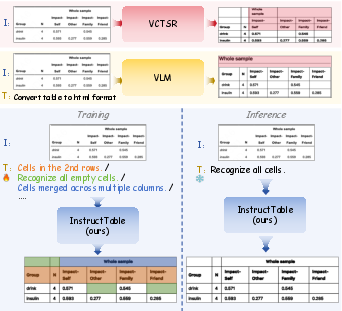
Figure 1: Comparison among VCTSR, VLM, and InstructTable architectures, highlighting InstructTable’s joint modeling of instructions and visual information for enhanced structural comprehension.
Traditional visual-centric TSR approaches (VCTSR) exclusively leverage visual features, which results in failures when faced with complex tables containing merged cells or empty rows due to their inability to harness semantic relationships. Conversely, vision-LLMs (VLMs) pre-trained on general multimodal corpora overly emphasize high-level semantics, leading to imprecise geometric alignment and poor handling of non-trivial spatial layouts. Data quality remains a substantial bottleneck: template-based synthetic datasets often introduce structural errors, such as unintentional implicit rows due to renderer-ground truth annotation mismatches, undermining model supervision.
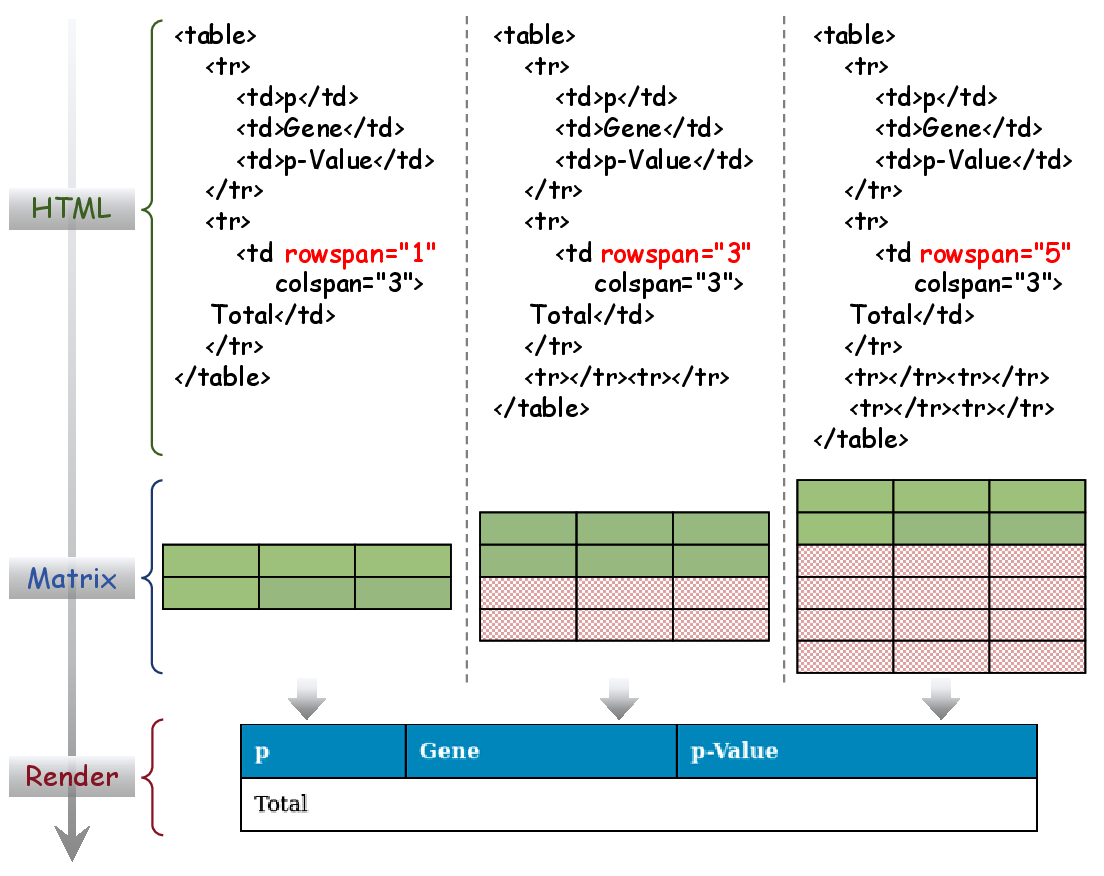
Figure 2: Illustration of the implicit row problem, where identical images may have divergent ground truth, misleading model optimization and creating annotation noise.
Table Mix Expand: Template-Free Synthetic Data Generation
To overcome the semantic-visual imbalance and data annotation bottleneck, TME synthesizes authentic table images by partitioning atomic cell matrices sampled from real tables and splicing these blocks to populate new large-scale, diverse instances. Guided by LLMs such as GPT-4o and Gemini 2.5 Pro, table content is auto-generated and semantically validated. TME's cropping invariance ensures legal table topology and eliminates template-induced artifacts. The process supports arbitrary scale and contextual variety, overcoming domain limitations of existing synthetic corpora.
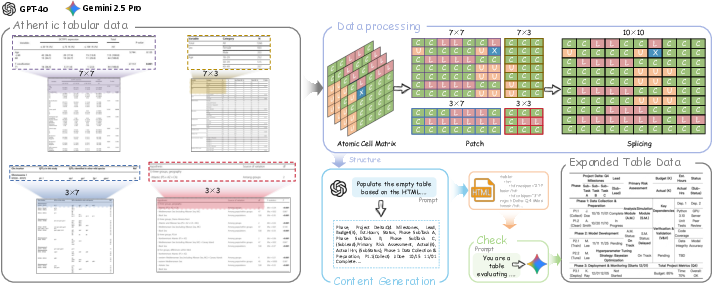
Figure 3: Pipeline of the TME synthesis process, showing atomic cell partitioning, patch splicing, content generation, validity checking, and augmentation for complex scenario coverage.
Instruction-Guided Multi-Stage TSR Framework
InstructTable is an end-to-end model that incorporates task-specific instruction priors at training time. The architecture consists of a TableResNetExtra image encoder and a BERT-based text encoder whose outputs are fused via cross-attention. The decoder generates atomic cell matrices, bounding boxes, and empty cell predictions, with offline OCR post-processing for multilingual robustness.
The three-stage training comprises:
- Initialization: Generic TSR objective ("Recognize all cells") to bootstrap competence.
- Instruction Pre-training: Sampled, fine-grained instructions induce dynamic attention modulation, supporting nuanced recognition of structures such as empty or merged cells.
- TSR Fine-tuning: Domain adaptation on downstream tasks for visual feature refinement.
A key technical aspect is the caching of instruction embeddings for inference efficiency, allowing lightweight deployment without online text encoding.
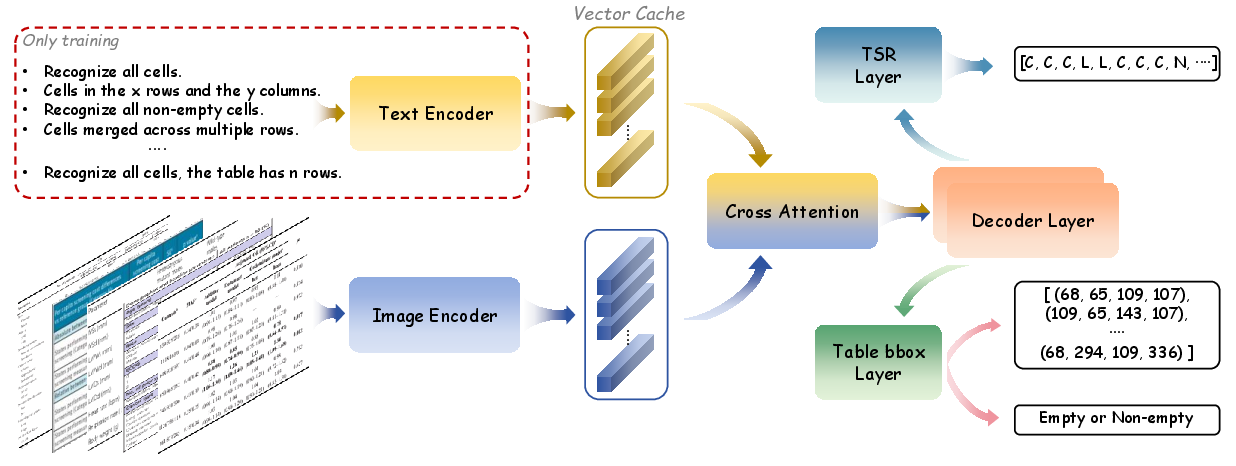
Figure 4: High-level InstructTable training and inference pipeline, visualizing cached instruction embeddings and the parallel heads for structured output.
Four instruction groups are used, targeting global structure, region-specific extraction, empty/non-empty cell detection, and merge recognition. Attention heatmaps empirically validate that the model allocates focus to semantically relevant spatial regions based on the instruction context.
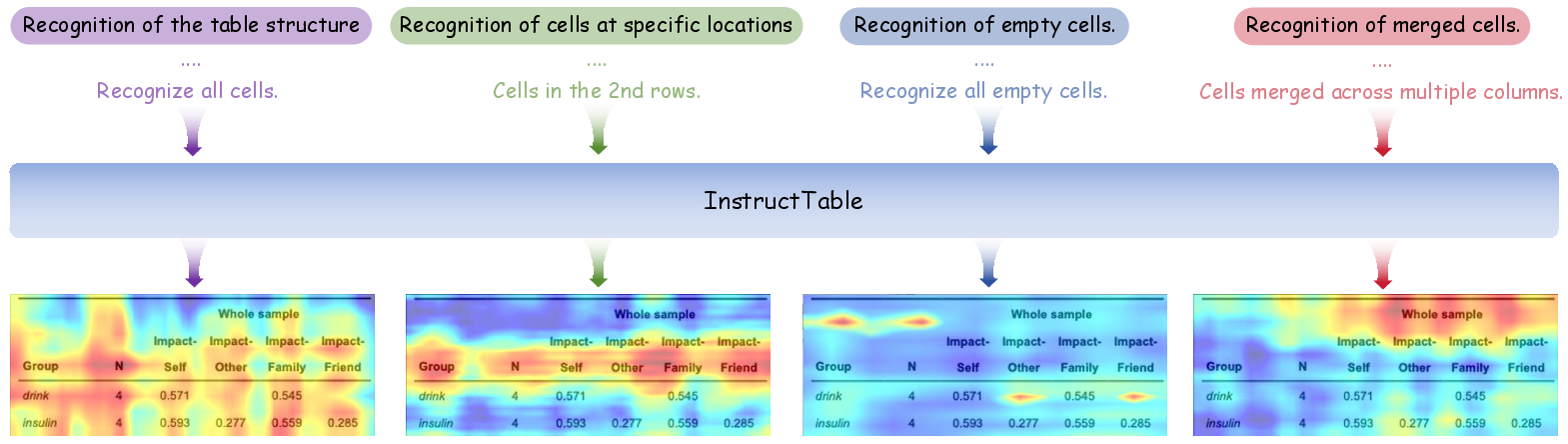
Figure 5: Cross-attention heatmaps reveal the spatial adaptation of model focus according to distinct instruction types, evidencing targeted structural parsing capacities.
BCDSTab Benchmark Construction
BCDSTab, comprising 900 images, is synthesized via TME using PubTabNet and FinTabNet as sources. By explicitly balancing cell count, merge patterns, dimension diversity, and context, BCDSTab covers dense, long-form tables absent in prior benchmarks. It provides HTML, atomic matrix, bounding box, and content annotations, supporting holistic evaluation.
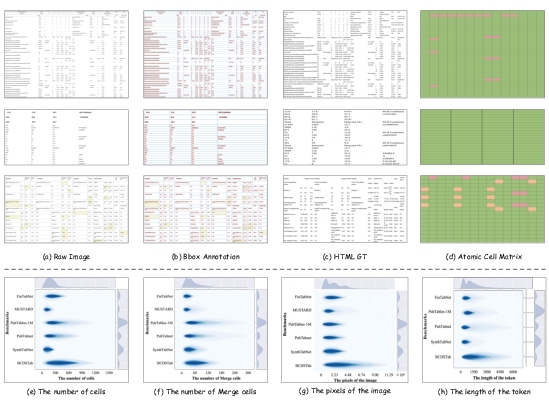
Figure 6: Overview of BCDSTab’s annotation schema and data statistics, demonstrating coverage of complex layouts and diverse merge structures.
Experimental Results
InstructTable achieves SOTA or near-SOTA performance on FinTabNet, PubTabNet, MUSTARD, and BCDSTab (structure-only TEDS up to 99.2% on FinTabNet, surpassing all VCTSR and VLM baselines with fewer parameters in most cases). On MUSTARD, the approach outperforms SPRINT by 10.11% and Gemini 2.5 Pro by 1.65% in TEDS. For long and dense tables in BCDSTab, InstructTable, when augmented with TME-generated data, surpasses models such as MinerU2.5 and DeepSeek-OCR.
Ablation studies on instruction pre-training and TME augmentation show additive and synergistic improvements in S-TEDS and TEDS, confirming the efficacy of both architectural and data-centric innovations. Removing any single instruction group diminishes overall performance, with the generic structure instruction being most critical.
Qualitative analyses show superior prediction fidelity, especially in capturing complex merge patterns and mitigating over-segmentation errors.
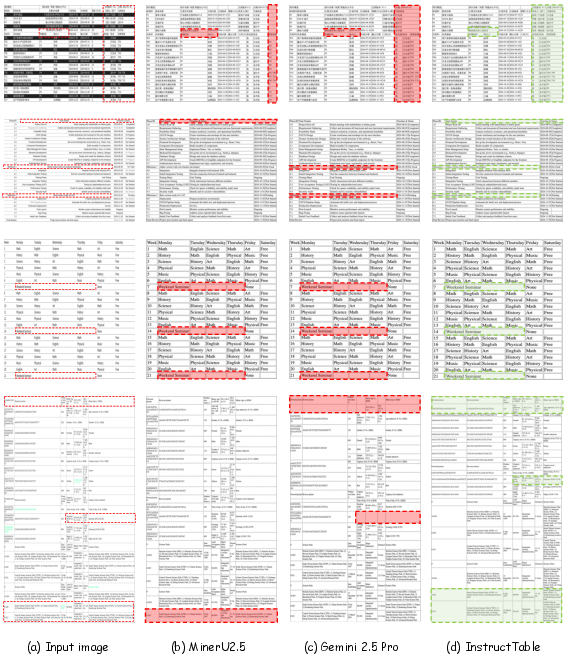
Figure 7: Visual comparison of output predictions from MinerU2.5, Gemini 2.5 Pro, and InstructTable on complex BCDSTab samples. Error regions are highlighted, evidencing InstructTable's superior localization and structure recognition.

Figure 8: Further visual comparison on BCDSTab, reinforcing the error reduction of InstructTable in challenging scenarios.
Theoretical and Practical Implications
This work demonstrates that explicit instruction-guided modulation within multimodal models bridges the observable gap between vision-only and vision-LLMs in fine-grained tabular understanding. The flexibility of TME enables lifelong data expansion, facilitating domain-adaptive training without template-induced bias, and establishes a testbed for extreme table scenarios via BCDSTab. The comprehensive framework—combining architectural innovation, supervision design, and data curation—offers a paradigm adaptable to other complex structured object recognition tasks.
Anticipated future developments include extending instruction-based control to retrieval-augmented or interactive document understanding systems and leveraging instruction-based alignment for better generalization and cross-lingual transfer in low-resource tabular settings.
Conclusion
InstructTable embodies an effective synthesis of instruction-driven joint modeling and scalable, authentic synthetic data augmentation. The model closes the gap between semantic comprehension and visual alignment, addressing limitations of legacy TSR and VLM approaches. Extensive benchmarks and ablations solidify its status as a robust foundation for complex table structure recognition tasks. Both the model and the BCDSTab benchmark catalyze future research in vision-language parsing under resource and scenario diversity constraints.
(2604.02880)