- The paper presents an end-to-end training approach using a Sentence-Conditioned Adapter (SCADA) to integrate language signals directly into video backbones.
- It employs a lightweight detection head and video-centric batch processing to achieve significant performance gains on benchmarks like Charades-STA and ActivityNet.
- Empirical results demonstrate state-of-the-art accuracy and scalability, highlighting effective cross-modal fusion and computational efficiency.
Fully End-to-End Training for Temporal Sentence Grounding in Videos
Motivation and Background
Temporal Sentence Grounding in Videos (TSGV) tasks the model with localizing temporal segments of untrimmed videos corresponding to natural language queries. Classical approaches utilize pre-trained, query-agnostic frozen video encoders for offline feature extraction prior to task-specific localization, leading to notable discrepancies between backbone training objectives (e.g., action classification) and TSGV requirements. This paradigm neglects intricate semantic alignment and dynamic cross-modal modulation, limiting representational capacity and ultimately, temporal localization precision.
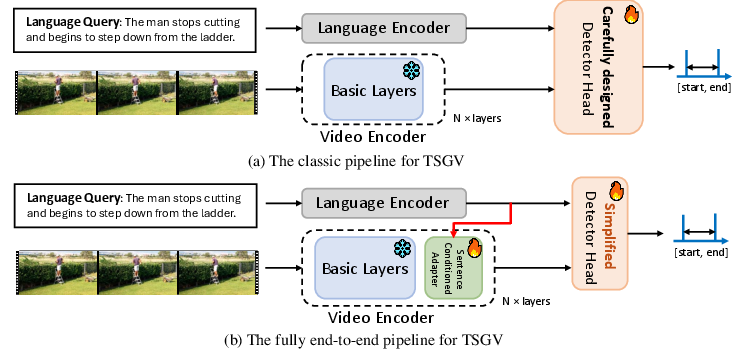
Figure 1: An overview of the classic pipeline for TSGV (top) vs. the proposed fully end-to-end pipeline (bottom), highlighting deep language-vision integration.
The proposed work addresses these limitations by moving towards a paradigm where the video backbone and localization head are trained fully end-to-end, integrating textual information throughout the pipeline.
Framework Overview
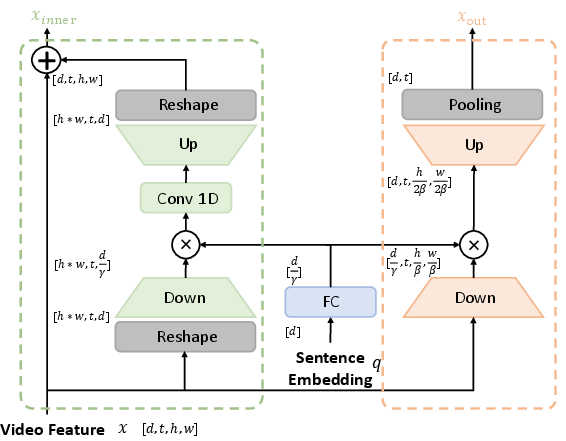
The introduced architecture leverages a Sentence Conditioned Adapter (SCADA) to inject language signals into the video backbone, enabling dynamic visual feature adaptation. The pipeline consists of a lightweight DistilBERT sentence encoder, a choice of video backbone (C3D, I3D, or self-supervised Vision Transformers), and a simplified detector head. Key innovations are:
- Sentence-Conditioned Modulation: SCADA integrates linguistic cues into the visual stream at multiple depths.
- Simplified Detector Head: E2E optimization enables usage of a computationally efficient head without sacrificing performance.
- Video-Centric Batch Construction: Multiple queries per video are processed simultaneously, improving both computational efficiency and visual feature optimization.
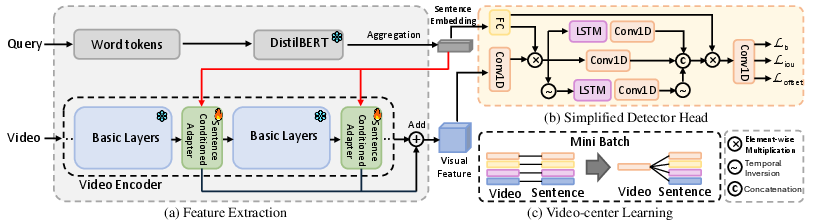
Figure 2: The overall framework for fully end-to-end training in TSGV featuring (a) SCADA, (b) a simplified detection head, and (c) video-centric batch learning.
Detailed Architecture
Feature Extraction and Modulation
Sentence representations are extracted from DistilBERT and video features from a backbone (3D-convolutional or transformer-based). The SCADA module (Figure 3) is interleaved within the video backbone, consisting of:
Detector Head and Losses
The detection head is a lightweight bidirectional LSTM with residuals, further fused with sentence embeddings at multiple points. The loss function is a multi-task combination of boundary, IoU, and offset regression losses, balancing positive/negative frames and explicitly optimizing for IoU overlap.
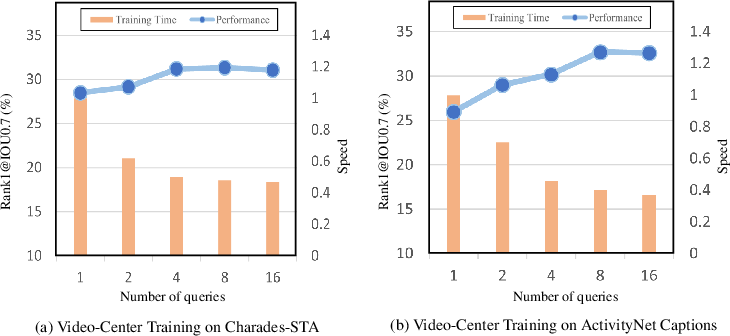
Video-Centric Learning
Traditional random pairing of queries and videos incurs excessive redundant computation. The proposed video-centric batch assembles all available queries for a sampled video, sharing visual features across queries, accelerating training, and enforcing multi-context alignment.
Experimental Results and Claims
Empirical evaluation on Charades-STA and ActivityNet Captions demonstrates the system’s effectiveness:
- Significant Performance Gains: The fully end-to-end framework with SCADA yields improvements of 16.91% (C3D), 16.08% (I3D), and 14.43% (ViT-S) in average metrics (mIoU, [email protected], [email protected]) over “head-only” (frozen backbone) baselines on Charades-STA.
- State-of-the-Art Results: On ActivityNet Captions, the method achieves 52.69% [email protected] (C3D) and 64.59% [email protected] (I3D), outperforming contemporary models including LLM-based and strong traditional pipelines.
- Model Scalability: With ViT-g (774.6M params), SCADA enables effective adaptation where full fine-tuning is computationally infeasible, matching or exceeding full fine-tuning’s effectiveness for smaller models at a fraction of updated parameters.
Notably, the approach reports that SCADA without language signals loses several points in accuracy, indicating the necessity of deep, early-stage semantic integration.
Analysis of Design Choices
Backbone Choice and Resolution
Experiments confirm that larger and more advanced video backbones (e.g., Vision Transformers with self-supervised pretraining) consistently outperform purely convolutional networks. End-to-end optimization allows maintaining performance at much lower input resolutions than frozen models (e.g., C3D@64, I3D@96, ViT-S@64), facilitating significant computational savings.
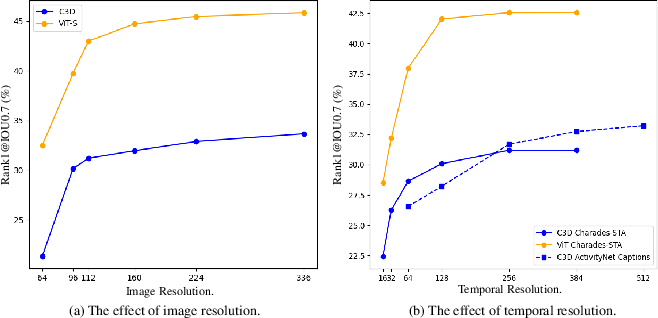
Figure 4: Empirical curves showing the effect of image and temporal resolution; E2E models maintain accuracy at reduced resolutions and frames.
Training Optimizations
Implications and Future Directions
This work formalizes the empirical necessity and advantages of full end-to-end optimization in TSGV. By facilitating parameter-efficient, scalable language-conditional adaptation of the visual backbone, it provides a reproducible path toward consistently outperforming both detection-centric and LLM-centric architectures.
Practically, the results suggest both immediate and latent value for related tasks (e.g., VideoQA, video captioning, multimodal retrieval). Theoretically, the demonstrated superiority of early and deep cross-modal fusion motivates a reevaluation of modular, late-fusion-centric architectures prevalent in video-language understanding.
SCADA-like modules may generalize effectively to other dense video-language tasks and hybrid transformer architectures. As training hardware, data, and parallelism scale, selective adapter-based fine-tuning with jointly optimized multi-modal backbones is likely to become the standard for high-precision video-language grounding.
Conclusion
Fully end-to-end optimization for TSGV, with language-conditioned visual adaptation via SCADA, provides consistent and substantial improvements over both frozen-backbone and LLM-centric paradigms. The framework demonstrates parameter efficiency, practical scalability, and new record state-of-the-art accuracy. The empirical findings support broad adoption of SCADA-style modules and motivate future research in extending this architecture to more general video-language tasks and further integration with large video-language foundation models.
(2604.02860)