- The paper introduces an ensemble-based framework that aggregates logistic regression detectors over diverse internal representations to effectively identify VLM hallucinations.
- It utilizes attention head outputs and PCA-reduced hidden states to capture robust signals, outperforming single-detector and concatenation baselines on key benchmarks.
- Experimental results on CRAG-MM and MMMU-Pro demonstrate significant AUC improvements, validating the approach’s efficiency and potential for production deployment.
EnsemHalDet: Ensemble-Based Hallucination Detection Leveraging Internal State Diversity in VLMs
Introduction
Vision-LLMs (VLMs) have attained state-of-the-art performance on multimodal tasks such as visual question answering and image captioning, but their susceptibility to hallucination—confidently generating outputs ungrounded in the visual input or inconsistent with factual knowledge—remains a substantial reliability challenge. Existing approaches to hallucination detection have exploited model outputs, external knowledge sources, or internal representations. Recent evidence indicates that internal model states capture robust indicators for hallucination, potentially outperforming output- or knowledge-based techniques with better efficiency and accuracy.
However, most prior internal-representation-based methods utilize a single feature or detector, failing to capitalize on the inherent diversity of hallucination-related signals present throughout the model's layers and components. "EnsemHalDet: Robust VLM Hallucination Detection via Ensemble of Internal State Detectors" (2604.02784) proposes a novel, ensemble-based framework that aggregates detectors trained on multiple internal representations—specifically attention head outputs and hidden states—utilizing ensemble learning mechanisms to increase robustness and detection performance.
Characterizing VLM Hallucinations and the Detection Challenge
VLM hallucinations manifest both in linguistic discrepancies (e.g., LLM–style factual errors) and inconsistencies between generated outputs and visual inputs, including object hallucinations, attribute errors, and violations of visual commonsense. Research has shown such errors are difficult to eradicate through optimization alone, highlighting the critical role of detection and abstention mechanisms for system safety.
Despite the high computational cost or limited coverage associated with output- and knowledge-based detectors, internal representations contain rich signals reflecting the model’s underlying uncertainty and faithfulness at runtime. Prior works like SAPLMA and MIND have leveraged features from specific layers or concatenated multiple internal signals, but do not systematically explore the potential for detector-level ensembling across distinct states.
Figure 1: VLMs can produce hallucinated responses that are inconsistent with factual knowledge or image content; such hallucinations leave detectable signals in the model’s internal representations.
EnsemHalDet: Methodology
EnsemHalDet extracts two primary types of internal features:
- Attention Head Outputs (AH): Per-head attention output vectors from all transformer layers, aggregated over generated tokens.
- Hidden States (HS): Layerwise hidden representations, with dimensionality reduced via PCA to mitigate overfitting and stabilize learning.
For each decoding step, the representation for the latest generated token is extracted and subsequently averaged across all output tokens to provide sequence-level summaries.
Detector Training and Ensemble Construction
Individual detectors—logistic regression classifiers—are independently trained for each attention head and each hidden-state layer using the respective averaged vector as input. For a model with L layers and H attention heads, this yields L×H AH-based and L HS-based detectors.
The ensemble selection process proceeds as follows:
- Validation-Based Ranking: All trained detectors are evaluated on one validation split; the most discriminative (by AUC) are selected.
- Forward Greedy Selection: Top-ranked detectors are further refined via greedy forward selection on a second validation split, emphasizing diverse and complementary detectors.
- Stacking Ensemble: The most effective detectors are aggregated via a stacking meta-classifier (logistic regression), optimizing the combination in an end-to-end fashion.
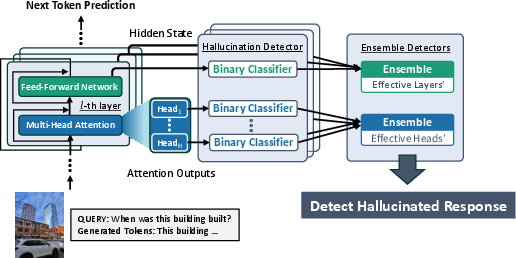
Figure 2: Overview of EnsemHalDet: binary classifiers are trained on both attention head and hidden-state features from multiple layers, then ensembled for robust hallucination detection.
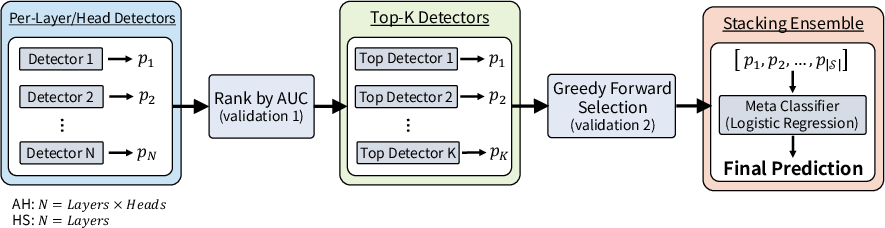
Figure 3: Detector-level ensemble process: optimal detectors are selected and combined using stacking meta-classification for maximal detection performance.
Experimental Evaluation
Datasets and VLMs
EnsemHalDet is evaluated using CRAG-MM and MMMU-Pro—comprehensive, multi-modal visual question answering datasets—and with three open-source VLMs: Llama-3.2-11B-Vision-Instruct, Qwen2.5-VL-7B-Instruct, and Pixtral-12B-2409. Hallucination labels for model outputs are determined by an LLM-as-a-judge (GPT-4o-mini) protocol, assessing consistency of generated answers with human-annotated ground truth (see Figure 4).

Figure 4: LLM-as-a-Judge prompt protocol used for hallucination evaluation via CRAG-MM.
Performance is reported as ROC AUC averaged over five randomized splits.
Main Results
EnsemHalDet consistently outperforms established baselines—SAPLMA, MIND, and MHAD—across all models and benchmarks on CRAG-MM. With attention (AH), hidden state (HS), and mixed (MIX) variants, the ensemble approach achieves strongest or near-best AUC scores, particularly when meta-stacking is used for aggregation.
- For Qwen2.5-VL-7B and Pixtral-12B, the combined (MIX) variant achieves best detection AUC.
- For Llama-3.2-11B, the HS-only variant yields highest performance.
- On MMMU-Pro, while EnsemHalDet dominates on Qwen2.5-VL-7B and Pixtral-12B, MHAD slightly outperforms it on Llama-3.2-11B.
Notably, ablation studies show ensemble-based approaches consistently outperform single-detector or concatenation schemes, with stacking providing the largest improvement. PCA-based dimensionality reduction for HS features significantly stabilizes and enhances detection accuracy.
Computational Efficiency Analysis
Although feature extraction—particularly aggregating all token representations—increases computational overhead compared to using only first and last tokens (as in SAPLMA and MHAD), the classification component of EnsemHalDet is extremely efficient due to the simplicity of logistic regression over MLPs. Feature extraction is thus the primary bottleneck, but the gap is modest (e.g., total runtime is 123–208% of baseline generation, depending on configuration).
Implications and Future Directions
This work provides strong evidence that ensemble methods exploiting diverse internal representations can enhance VLM hallucination detection beyond single-representation and naive concatenation strategies. The clear AUC improvements across multiple architectures and datasets validate the hypothesis that complementary internal signals can be effectively leveraged using principled ensembling and meta-learning.
Practically, EnsemHalDet is model-agnostic for open-source VLMs and can be adapted to new architectures as long as internal activations are accessible. The framework's efficiency and modularity make it attractive for production deployment where runtime is constrained. Theoretically, these results motivate further examination of the distinct signals provided by various internal features, and further exploitation of ensemble learning theory in model-internal diagnostic tools.
For future work, the authors highlight multiple avenues:
- Efficiency-Performance Trade-Off: Optimizing feature extraction strategies to reduce computational cost without sacrificing accuracy.
- Applicability to LLMs: Adapting ensemble detection to LLMs in addition to vision-language counterparts.
- Characterizing Ensemble Success: Investigating in detail why detector-level stacking outperforms concatenation, and disentangling the roles of AH and HS features in different model families.
- Fine-Grained Hallucination Typology: Understanding detection performance across hallucination subtypes, potentially improving abstention and uncertainty signaling mechanisms in safety-critical contexts.
Conclusion
EnsemHalDet introduces a robust, ensemble-based hallucination detection framework that combines independent classifiers over multiple internal VLM representations. Experimental results affirm the superiority of ensemble strategies—especially stacking—over single-detector or concatenative baselines, with substantial AUC gains shown across diverse benchmarks and models. While the approach introduces moderate computational overhead for feature extraction, it offers significant detection performance improvements and practical classifier efficiency. Future work should explore scalable feature selection, transfer to additional model families, and expand theoretical analyses of ensemble effects within model-internal detectors.

