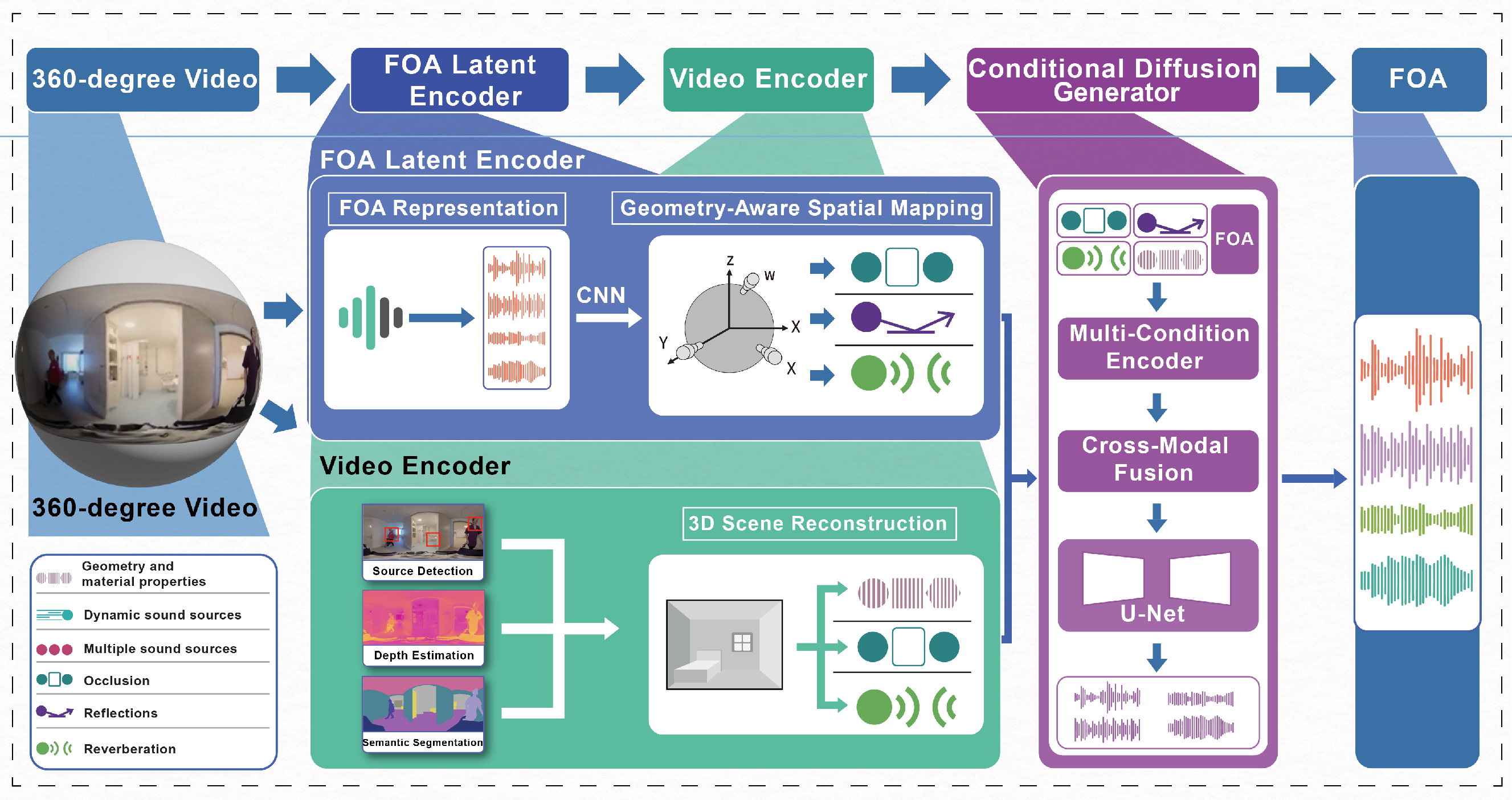
- The paper introduces a conditional diffusion framework that fuses 3D scene reconstruction with FOA synthesis for dynamic, acoustically complex 360° videos.
- It employs multi-modal supervision and physics-informed conditioning—via geometric, depth, and material priors—to significantly reduce DOA errors and spectral artifacts.
- The approach is validated on the new M2G-360 dataset, demonstrating over 33% improvements in spatial and acoustic fidelity compared to prior methods.
DynFOA: Conditional Diffusion-Based FOA Generation Leveraging Dynamic 3D Scene Understanding in 360-Degree Videos
Introduction
First-order ambisonics (FOA) spatial audio is essential for fully immersive 360-degree video and VR experiences, yet the majority of 360-degree content is distributed with purely monaural or stereo soundtracks due to the technical challenges of authentic spatial audio capture. The synthesis of FOA from 360-degree videos represents a long-standing, ambitious challenge, primarily due to the considerable gap between visual context and real-world environmental acoustic phenomena. DynFOA addresses this gap by presenting a generative framework that leverages detailed 3D scene reconstruction and physics-informed conditioning in a diffusion-based generative model for FOA synthesis, establishing new performance benchmarks and redefining robustness under complex acoustic scenarios (2604.02781).
Architecture and Methodology
DynFOA realizes scene-aware FOA generation through a three-stage architecture:
The synthesis process is strictly physics-informed, explicitly constraining the denoising trajectory: material-dependent absorption, geometry-driven occlusion, and variable reverberation times are injected as conditioning signals into the generative process. The approach is designed for dynamic, multi-source, and highly reverberant scenes, with efficient head tracking and HRTF-based binaural rendering for practical VR deployment.
Dataset Contribution: M2G-360
Existing benchmarks such as Sphere360 and YT-360 are either acoustically simplistic or dominated by static source placement, failing to probe the limits of FOA generation under realistic scene complexity. The authors construct M2G-360, a curated dataset of 600 360-degree video clips with matched 4-channel FOA tracks, systematically partitioned into subsets targeting dynamic occlusion ("MoveSources"), overlapping sources ("Multi-Source"), and diverse geometry/material configurations ("Geometry"). M2G-360 enables rigorous, multidimensional evaluation of spatial robustness, frequency-dependent reverberation, and disentangling of colocated sources in FOA synthesis.
Experimental Results
DynFOA is systematically benchmarked against leading approaches, including OmniAudio, ViSAGe, Diff-SAGe, and MMAudio+SP. Evaluations span both conventional and newly proposed datasets, with a broad set of quantitative metrics:
- Spatial Accuracy: Angular Direction-of-Arrival (DOA) estimation.
- Acoustic Fidelity: Signal-to-Noise Ratio (SNR) and Early Decay Time (EDT) for reverberation analysis.
- Distribution Matching: Fréchet Distance (FD), Kullback-Leibler (KL) divergence, Short-Time Fourier Transform (STFT) error, and SI-SDR.
- Human Perception: Mean Opinion Scores (MOS) for spatial quality (MOS-SQ) and audiovisual alignment (MOS-AF), rated in head-tracked VR setups.
On Sphere360, DynFOA achieves a DOA error reduction of 26.3% and an EDT decrease of 33.3% over OmniAudio. KL divergence and STFT error improve by over 32%, indicating sharper alignment with ground-truth distribution and reduced perceptual artifacts. Human MOS scores reach 4.35±0.22 for spatial quality and 4.12±0.25 for alignment, consistently outperforming baselines.
Notably, across M2G-360's most challenging subsets, DynFOA posts:
- 46.7% lower DOA error in MoveSources, maintaining spatial coherence under heavy occlusion and source movement.
- 33.3% reduction in STFT and FD in Multi-Source, demonstrating robust disentangling of overlapping energy fields.
- 40.0% lower EDT in Geometry, validating precise modeling of long-tail reverberation and material effects.
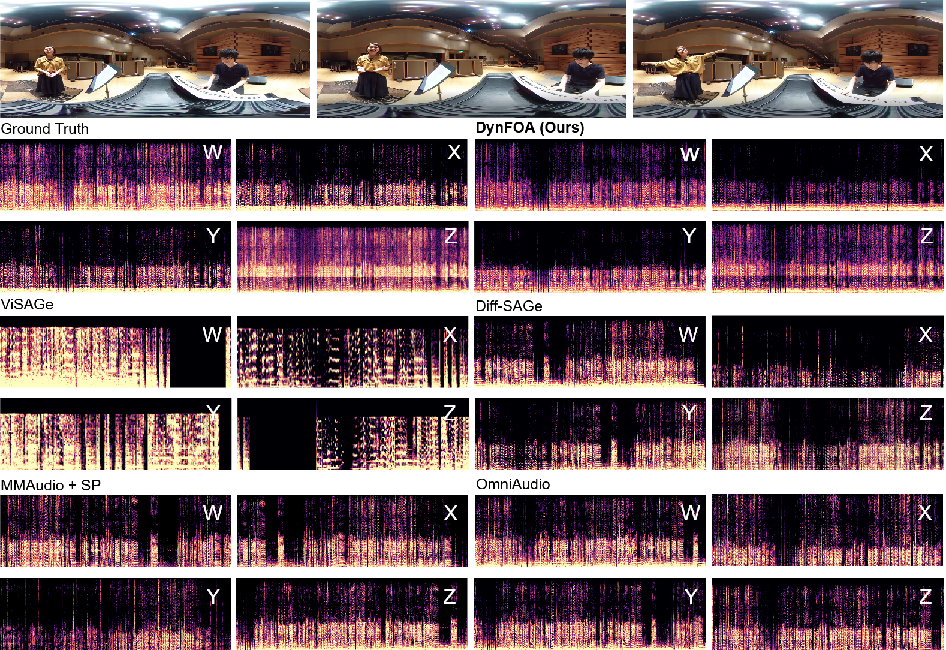
Figure 2: Mel-spectrogram visualizations for FOA channels (W, X, Y, Z) in a highly reverberant piano scene: only DynFOA recovers high-frequency energy and stable spatial correlation, closely tracking ground truth.
The ablation studies unequivocally show that stepwise inclusion of geometric, depth, and material priors drives all core metrics closer to the upper performance bound, whereas audio-only or purely visual baselines plateau at significantly lower accuracy.
Key Claims and Analysis
- Explicit structural and material conditioning enables physically plausible FOA generation in highly dynamic scenes, opposed to prevailing models relying purely on global 2D visual features and static context assumptions.
- Conditional diffusion, grounded on 3D GS reconstructions and frequency-dependent material priors, reduces acoustic hallucination and spurious spatial drift common in unconstrained generative models.
- M2G-360 provides an indispensable, rigorously filtered benchmark exposing FOA models to previously unexplored extremes of real-world acoustic complexity.
The empirical superiority is strongest in scenes with strong occlusion, dynamic source motion, and prominent late reverberation, where simpler models fail to maintain either localization or physical coherence.
Theoretical and Practical Implications
The methodological advances in DynFOA highlight a decisive shift from generic cross-modal alignment towards physics-informed, structure-driven generation of spatial audio. This reorientation directly addresses a longstanding challenge: bridging the multimodal gap between video-centric object localization and variable, multi-path acoustic propagation. Integrating 3D Gaussian Splatting, material lookup tables, explicit path analysis for occlusion/reflection, and conditional latent diffusion sets a new technical precedent for the field.
Practically, the pipeline paves the way for high-fidelity FOA synthesis from consumer-grade 360-degree video. DynFOA's capacity for real-time, head-tracked binaural rendering with accurate handling of reverberation and source movement suits not only VR/AR but also cinematic content creation, robotics, and interactive media requiring spatially coherent soundscapes.
Outlook and Future Directions
Persisting limitations include approximate material property estimation via semantic segmentation, restricting the model's ability to capture nuanced, frequency-dependent acoustic behaviors in complex architectural or outdoor scenes. Direct integration of acoustic sensor data, refinement of 3DGS with hybrid LiDAR/photogrammetry, or self-supervised estimation of material absorption spectra represent promising future enhancements. Additionally, transitioning towards end-to-end differentiable pipelines may unlock more robust generalization over diverse real-world environments and lower the practical complexity of training and deployment.
Conclusion
DynFOA establishes a new paradigm for FOA generation by employing dynamic 3D scene reconstruction and conditional latent diffusion, unifying vision-derived geometric priors with physically realistic audio generation. The strong numerical improvements across both classic and newly constructed benchmarks, particularly in DOA, EDT, and MOS metrics, substantiate the indispensability of explicit acoustic conditioning for robust FOA synthesis. M2G-360 provides a solid foundation for further advances in this domain, and the DynFOA approach offers a robust framework for the next generation of immersive spatial audio rendering systems.