- The paper introduces MRCKG, a framework that employs a multimodal-structural curriculum, cross-modal preservation, and contrastive replay to address catastrophic forgetting in evolving MMKGs.
- The framework ranks new triplets by integrating structural connectivity, multimodal compatibility, and modality richness, enabling progressive and effective learning.
- Experimental results on nine benchmarks show that MRCKG achieves up to 30.6% improvement in MRR, demonstrating its superior balance between plasticity and stability.
Continual Learning for Multimodal Knowledge Graphs: The MRCKG Framework
Introduction and Motivation
Multimodal Knowledge Graphs (MMKGs) extend traditional KGs by incorporating visual and textual modalities alongside relational triples, which enhances entity representations for reasoning tasks spanning multiple modalities. However, real-world MMKGs are inherently dynamic, with continuous additions of entities, relations, and new multimodal information. Existing approaches in MMKG reasoning mostly assume static graphs, making them inadequate for settings where knowledge and modalities evolve over time. Continual Knowledge Graph Reasoning (CKGR), while advancing in approach, has primarily targeted unimodal, structural data and does not address the multimodal catastrophic forgetting and cross-modal semantic drift intrinsic to MMKG evolution.
To systematically address continual multimodal KG reasoning (CMMKGR), the paper introduces the MRCKG framework, which incorporates a scalable multimodal encoding backbone, a collaborative curriculum for progressive learning, cross-modality preservation to counteract forgetting, and contrastive replay for robust memory retention. Nine benchmark datasets spanning three MMKGs and multiple evolutionary strategies are proposed to facilitate systematic evaluation. The core insight is that stable, pretrained multimodal features provide persistent semantic anchors, mitigating catastrophic forgetting and supporting inductive learning for novel entities lacking structural links.
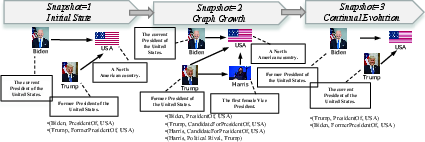
Figure 1: CMMKG stores knowledge as evolving multimodal triplets, with modalities and structure co-evolving over time.
The authors define an evolving MMKG as a snapshot sequence of graphs, each snapshot containing incrementally expanding sets of entities, relations, and modality-rich triplets. At each step, only new knowledge and a bounded replay memory are leveraged for model updates, without full retraining. The principal challenges are:
- Cold-Start Problem: Novel entities often lack sufficient structural context, making multimodal data (images, text) essential for accurate representation.
- Catastrophic Forgetting across Modalities: Parameter updates can disrupt not only structural embeddings but also visual/textual projections and cross-modal alignments, leading to loss of previously learned multimodal semantics.
- Sample Curriculum Complexity: The order of incorporating new knowledge directly affects continual learning outcomes, as structurally or semantically proximate entities are easier to assimilate.
The MRCKG Framework
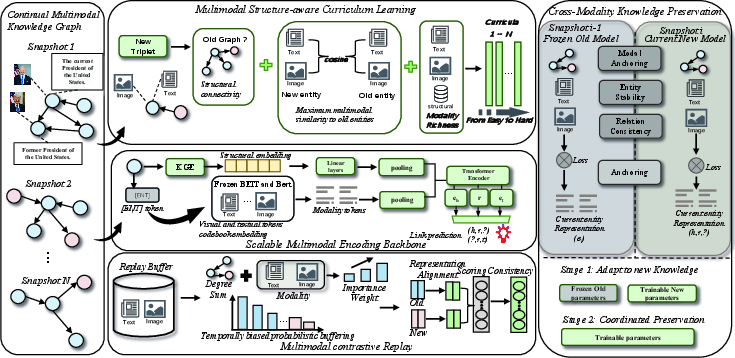
Figure 2: Overall MRCKG framework: continual learning via multimodal-structural curriculum, cross-modal knowledge preservation, and multimodal contrastive replay.
MRCKG is composed of three synergistic components:
Multimodal Structure-aware Curriculum Learning (MSCL)
MSCL constructs a curriculum by ranking new triplets based on a composite score integrating:
- Structural Connectivity: Measures graph-theoretic proximity to previously known entities.
- Multimodal Compatibility: Assesses semantic similarity in pretrained visual/textual feature space between new entities and old ones.
- Modality Richness: Quantifies the diversity and abundance of an entity’s visual and textual information.
Triplets are ordered from easy (well-connected, semantically similar, modality-rich) to hard (isolated, semantically distant), and are introduced progressively, recalibrating the curriculum as training unfolds.
Cross-Modality Knowledge Preservation (CMKP)
To constrain forgetting, MRCKG unifies preservation objectives across:
- Entity Stability: Penalizes drift in entity embeddings using Smooth L1 loss, weighted by graph centrality and modality richness.
- Modal Consistency: Explicitly stabilizes the projected visual and textual representations and their mutual alignment.
- Relation Pattern Consistency: Enforces both numerical stability and semantic consistency of relation embeddings and their associated triplet scoring patterns across snapshots.
- Anchoring via Pretrained Modalities: Employs the frozen outputs from previous snapshots to serve as consistent anchors within the entity embedding space.
Multimodal Contrastive Replay (MMCR)
A multimodal importance sampling constructs the replay buffer, emphasizing structurally pivotal and modality-rich historical samples, with temporal closeness biasing buffer allocation toward recent snapshots. The MMCR module then:
- Aligns old and new entity representations via InfoNCE contrastive losses on the replayed instances.
- Preserves link prediction consistency, enforcing stable scores between the old and updated models on all replayed triples.
Training proceeds in two stages: first adapting parameters exclusive to new entities, then globally updating all parameters with full cross-modal preservation losses activated, thus stabilizing joint learning across modalities and structure.
Experimental Evaluation
MRCKG is extensively evaluated on nine benchmarks derived from DB15K, MKG-W, and MKG-Y, each evaluated across three different evolutionary splits—entity, higher increment, and equal increment regimes. The framework is compared against 18 baselines spanning unimodal/continual/multimodal KG models and sophisticated continual learning (CL) methods, such as EWC, experience replay, IncDE, and FastKGE.
Strong numerical results: MRCKG consistently achieves the highest MRR on all nine benchmarks. For example, on DB15K-Entity, it surpasses IncDE, the strongest continual baseline, by 13.4% in MRR. On the most challenging MKG-W-Higher split, the improvement reaches 30.6%. Simple multimodal fusion without dedicated continual learning mechanisms is ineffective, and general CL methods (e.g., EWC) display high model dependency, sometimes dramatically reducing performance, as in the case of TuckER.
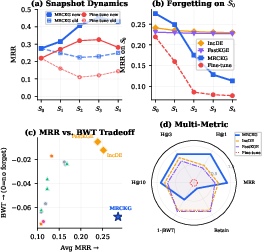
Figure 3: Per-snapshot MRR for new versus old triples in DB15K-Entity, BWT (Backward Transfer), and multi-metric radar plot highlighting MRCKG’s superior plasticity-stability balance.
Ablation and Analysis
Ablation studies indicate that:
- CMKP is most critical: Removing it leads to significant drops in MRR and BWT, confirming its central role in preventing forgetting.
- MMCR and progressive curriculum (MSCL) also confer substantial benefits, particularly for balancing accuracy and memory retention.
- The visual modality is slightly more important than the textual modality for precise ranking, but both contribute to long-term retention.
The error analysis reveals that forgetting old knowledge remains the dominant failure mode, followed by misclassification due to cross-modal ambiguity and cold-start limitations for newly introduced entities. This underlines a fundamental trade-off between plasticity and stability in large multimodal continual learning models.
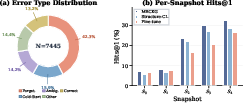
Figure 4: (a) Error type breakdown in MRCKG on DB15K-Entity, emphasizing the predominance of forgetting errors; (b) Hits@1 evolution across snapshots for MRCKG, structure-only CL, and fine-tuning baselines.
Practical and Theoretical Implications
The MRCKG framework demonstrates that pretrained, stable multimodal features can serve as consistent semantic anchors in continual learning, significantly mitigating catastrophic forgetting and supporting more effective induction for entities introduced with limited structural context. The unified curriculum/preservation/replay strategy is essential for robust continual MMKG reasoning—single-modal CL methods or naïve fusion are markedly inferior.
Practically, this approach enables scalable updates of MMKG reasoning models without full retraining, crucial for dynamic knowledge environments (e.g., news, biomedical KGs). Theoretically, MRCKG highlights that cross-modal memory retention must be co-optimized with structural embedding preservation, and that continually evolving multimodal semantic spaces require curriculum-informed and contrastively regularized learning.
Future research may explore even finer granularity in modality-specific anchor construction, dynamic memory allocation tailored to multimodal input distributions, or integrating large language or vision models as plug-in semantic anchors within the continual MMKG pipeline.
Conclusion
This work introduces the first systematic framework for continual multimodal knowledge graph reasoning, MRCKG, leveraging a multimodal-structural curriculum, cross-modal preservation, and multimodal contrastive replay. Its empirical superiority across all benchmarks underscores both the inadequacy of unimodal continual methods for MMKGs and the necessity of explicitly leveraging the stable nature of pretrained modality representations as semantic anchors. MRCKG represents a substantial step toward lifelong, adaptive reasoning over dynamically evolving, modality-rich knowledge graphs (2604.02778).

