- The paper demonstrates that advanced prompt engineering strategies can improve code generation accuracy but often increase carbon emissions.
- It employs a systematic benchmarking of 11 SLMs using six different prompting strategies across varied hardware and regional energy profiles.
- The study highlights that simpler approaches like Chain-of-Thought achieve near-optimal accuracy with significantly lower environmental impact.
Evaluating the Environmental Impact of Prompt Engineering with Small LLMs for Code Generation
Introduction
The proliferation of open-source Small LLMs (SLMs) has augmented accessibility and privacy in AI-driven code generation, shifting the environmental burden from centralized cloud infrastructures to a decentralized, user-centric ecosystem. While prompt engineering—particularly through strategies such as Chain-of-Thought (CoT) and ReAct—has become crucial for enhancing code generation performance, its sustainability implications remain underexplored. This paper conducts a systematic, empirical study quantifying the trade-offs between prompt engineering strategies, code generation accuracy, and environmental impact (energy, carbon emissions, inference latency) across a diverse collection of SLMs, benchmarking the decoupling of performance and sustainability. The work establishes a quantitative framework for sustainable prompt engineering practices, aligning technical objectives with emergent ecological responsibilities (2604.02776).
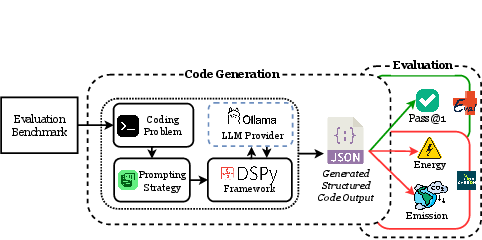
Figure 1: Evaluation framework to benchmark LLMs.
Methodological Design and Evaluation Framework
The study rigorously benchmarks 11 open-source SLMs spanning 1B–34B parameters (including both general-purpose and code-specialized variants) using two widely-adopted code generation datasets (HumanEval+ and MBPP+). A canonical prompting abstraction (DSPy) is employed to ensure output structure conformity and minimize spurious variability due to formatting, mirroring production-like constraints for plug-and-play generative coding systems. Six representative prompt engineering strategies—Direct, Chain-of-Thought, Program-of-Thought, Self-Consistency, Least-to-Most, and ReAct—are implemented uniformly across models.
Distinct hardware environments (NVIDIA A100/Alberta vs. L40S/Ontario) are leveraged to underpin the analysis of both hardware-related and region-specific grid carbon intensity (GCI) factors. Energy usage and emissions are estimated via CodeCarbon, with emissions calculated as the product of measured energy and region-specific GCI. Evaluation metrics include Pass@1 accuracy, average CO₂ emission, inference time, token usage, and energy consumption, allowing for multidimensional trade-off analysis.
Scaling and Accuracy–Emissions Trade-off in SLMs
Empirical results reveal that code generation accuracy does not scale monotonically with model parameter count. Notably, GPT-OSS:20B outperforms the larger Qwen3-Coder:30B by 3.4% (HumanEval+) and 1.5% (MBPP+), while Qwen2.5-Coder:7B achieves superior metrics compared to larger general-purpose models. Very small models (e.g., StarCoder2:3B) experience high parsing error rates and poor output conformity, undermining their practical utility, while Qwen3:1.7B, despite high accuracy, demonstrates anomalously high token usage.
Crucially, per-query CO₂ emissions are weakly dependent on parameter size; emission profiles (on the order of 10−5–10−4 kg CO₂) primarily hinge on inference efficiency and runtime configuration rather than model scale alone. Model specialization confers no systematic advantage in emissions or accuracy, reaffirming the primacy of training quality and architectural reasoning enhancements over domain focus.
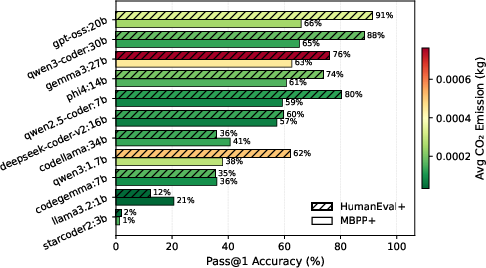
Figure 2: Comparison of Pass@1 accuracy and CO₂ emissions on MBPP+ and HumanEval+ across models.
Comparative Analysis of Prompting Strategies
Evaluation of prompting strategies uncovers stark disparities in accuracy–sustainability trade-offs. Self-Consistency achieves the maximal mean Pass@1 (65.75%), but with a 4.9x increase in average emissions and energy relative to CoT, due to the high overhead of aggregating multiple reasoning paths. While Direct prompting offers lowest emissions, Chain-of-Thought emerges as the most efficient compromise—delivering near-optimal accuracy with ~80% lower emissions than Self-Consistency.
Complex reasoning frameworks such as Least-to-Most, ReAct, and Program-of-Thought incur inflated token usage and computational cost without proportional gains in Pass@1. This establishes strong evidence of diminishing returns for advanced prompt engineering techniques on small- to mid-scale SLMs in conventional code generation tasks.
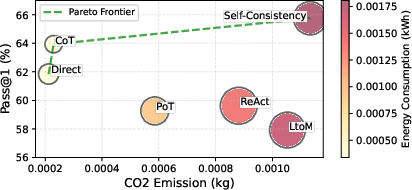
Figure 3: Bubble chart of mean Pass@1 accuracy versus energy consumption for different prompting strategies. Bubble size represents average token count and color represents average CO₂ emissions.
Hardware and Regional Effects on Sustainability
The hardware and regional emission analysis demonstrates that grid carbon intensity (GCI) is the single strongest determinant of carbon emissions. For example, although Machine 2 (Ontario) consumes 113.54% more energy than Machine 1 (Alberta) per inference, its CO₂ emissions are 78% lower owing to Ontario’s low-carbon electrical grid. Absolute energy consumption, token usage, and inference time become secondary contributors in regions with decarbonized energy profiles.
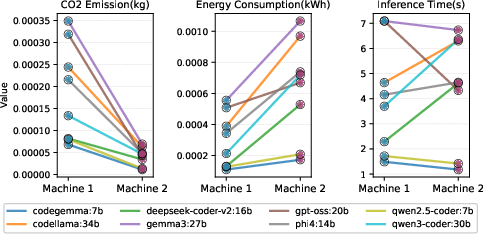
Figure 4: Comparison of CO₂ emission, energy consumption, and inference time of different models in Machine 1 and Machine 2 when Chain-of-Thought is used.
Correlational Findings for Sustainability Metrics
Correlation analysis underscores that inference time is the primary predictor of both energy use and CO₂ emissions across all datasets and prompt strategies (R² ≈ 0.90). Token count exhibits only moderate correlation with environmental impact, indicating that token-based proxy metrics are insufficient in isolation. Critically, Pass@1 accuracy displays negligible correlation with any sustainability metric, highlighting the independence of performance and environmental cost with appropriate prompt optimization.
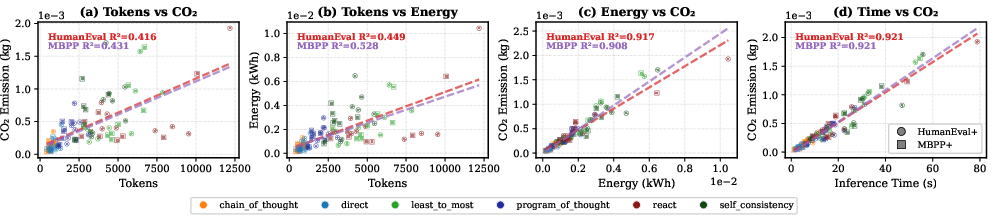
Figure 5: Relationship between different sustainability factors across different prompting strategies.
Prompt structure, particularly when interfacing with DSPy, modulates token usage and sustainability indirectly. Reasoning-oriented models, when subjected to Direct prompting without explicit reasoning constraints, tend to produce verbose outputs that increase token usage and environmental footprint. In contrast, CoT’s structural prompts encourage concise reasoning–answer boundaries, sometimes reducing overall token usage even in complex models.
Output format correctness analysis reveals that most small and medium SLMs sustain low parsing error rates, but very small models (e.g., StarCoder2:3B, LLama3.2:1B) are unreliable for structured code generation, necessitating costly retries or error handling, which can further inflate actual emissions.
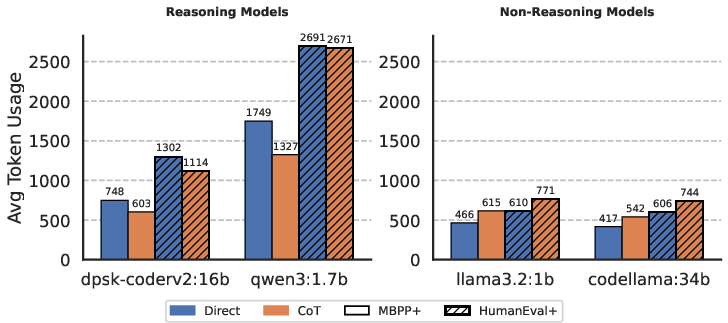
Figure 6: Comparison of average token usage of different reasoning and non-reasoning models.
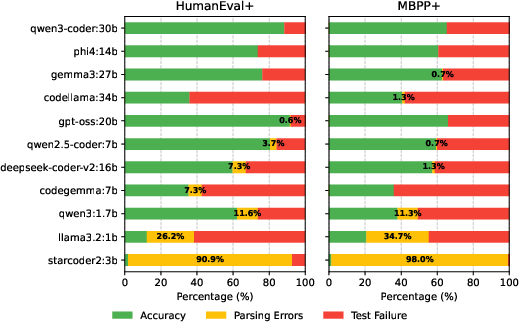
Figure 7: Comparison of parsing errors in different models.
Carbon per Correct Answer (CpCA) as an Integrated Sustainability Metric
To consolidate sustainability and task efficacy, the Carbon per Correct Answer (CpCA) metric is introduced, tracking emissions required for each correct benchmark solution. Strategies with higher explicit reasoning steps exhibit disproportionate increases in CpCA, even when accuracy gains are modest. The ranking of prompt strategies by CpCA remains robust across hardware and regional configurations, reinforcing the utility of prompt-level intervention over hardware-focused optimization, especially given the inertia of energy infrastructure transitions.
Implications, Limitations, and Future Work
This analysis provides strong empirical justification for adopting simpler, structured prompting schemes (e.g., CoT) when deploying SLMs for conventional code generation workloads, as they can minimize carbon emissions without sacrificing accuracy. The results indicate that practitioners should optimize model and prompt selection for the "accuracy per watt" regime rather than absolute performance.
Limitations include static grid carbon estimations and constraints to specific hardware/model sets. There is also underrepresented coverage of long-running workflows and cloud deployments, as well as only using historical GCI data, which may not capture recent rapid decarbonization trends in electricity grids.
Future directions should prioritize the development of metrics and benchmarks for comparative sustainability assessment, real-time carbon-aware prompt orchestration, prompting frameworks that surface per-inference emissions, and incentive structures favoring efficient code-specialized SLMs over indiscriminate scaling.
Conclusion
Prompt engineering strategies substantially influence the environmental footprint of code generation with SLMs, independent of marginal differences in accuracy. Chain-of-Thought prompting achieves favorable trade-offs, providing near-optimal performance with minimal emissions. Hardware and, more decisively, regional grid carbon intensity dominate carbon outcomes, suggesting that software-level optimizations and deployment location must be considered integrally for genuinely sustainable AI-assisted coding ecosystems. Environmental metrics such as CpCA offer a rigorous, application-level basis for sustainability-aware decision-making in prompt design, model selection, and system architecture.