- The paper introduces novel composite sustainability metrics (SVI and GFβ) to evaluate test script generation performance and eco-efficiency.
- It employs a rigorous five-phase methodology combining adaptive prompt engineering and quantization regimes with regional carbon intensity analysis.
- Empirical results demonstrate that model performance and environmental impact depend on the interplay between quantization depth, prompt design, and regional energy profiles.
Introduction
The empirical study "An Empirical Study of Sustainability in Prompt-driven Test Script Generation Using Small LLMs" (2604.02754) advances the understanding of eco-efficiency in AI-driven software engineering by foregrounding sustainability metrics in prompt-driven automated test script generation with small LLMs (SLMs; 2B–8B parameters). Most prior research in this area has concentrated on LLMs and neglected nuanced exploration of the performance–environmental cost trade-offs for SLMs operating in real production environments—especially in the context of varying prompt designs, quantization regimes, and regional carbon intensities.
Experimental Pipeline and Methodological Rigor
The analytical pipeline (Figure 1) operationalizes a five-phase workflow: dataset preprocessing (leveraging the HumanEval benchmark); development of adaptive prompt templates (APV0–APV3, based on Anthropic prompt engineering principles); parameterized inference with state-of-the-art SLMs (Phi-3.5-mini, Qwen2.5-1.5B, deepseek-coder-7b, Mistral-7B, Llama-3-8B) across quantization schemes; granular trace-based sustainability metric logging (with CodeCarbon, regional grid intensity tracking, and functional code coverage via Coverage.py); and systematic multidimensional trade-off analysis.

Figure 1: Core empirical pipeline capturing preprocessing, prompt engineering, test script generation under varying SLM/prompt/quantization, and sustainability trade-off computation.
Evaluation Metrics and Novel Sustainability Indices
The study introduces and operationalizes two composite sustainability metrics, both targeted at the inferential phase of SLM-driven code generation under zero-shot prompting:
- Sustainability Velocity Index (SVI): A normalized, multiplicative metric integrating code coverage, software carbon intensity (SCI), execution duration, and run-to-run stability. SVI's construction enforces that weaknesses in any axis (e.g., high emissions, slow inference, low coverage, or instability) are not masked by strengths elsewhere.
- Green Fβ Score (GFβ): A tunable composite of eco-efficiency (ECO) and accuracy (coverage), with the trade-off parameter β determining the emphasis on ecological versus functional priorities.
These indices depart from established single-dimensional efficiency benchmarks and enable explicit ranking and prioritization, supporting both technical and policy-driven model selection.
Empirical Results: Model, Prompt, and Region Sensitivities
Software Carbon Intensity (SCI) and Regional Effects
SCI results (Figure 2) expose the dominant impact of regional grid carbon intensity, with lower SCI for inferences performed in regions with cleaner grids (e.g., Netherlands, USA–Oregon) and elevated SCI in higher intensity grids (e.g., Singapore, USA–Nevada). When controlling for region, prompt structure and model architecture are the primary determinants of energy and emissions overhead per generated script.
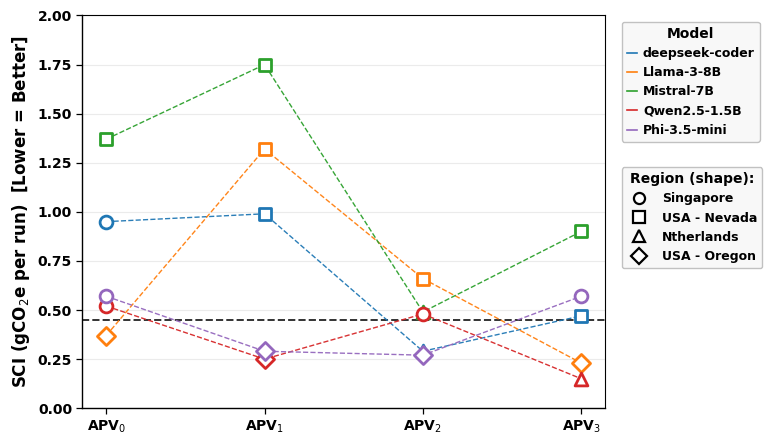
Figure 2: SCI evaluation across SLMs, prompts, and regions, highlighting the interaction between workload migration and grid carbon intensity.
Holistic Sustainability Ranking: SVI
SVI analysis (Figure 3) demonstrates that region and prompt engineering interact to determine composite eco-performance. While models targeting low-carbon regions trend above-median SVI, prompt and model configurations can counteract or exacerbate regional differences. The results validate SVI as a multidimensional, discriminative scoring function for test-automation scenario selection.
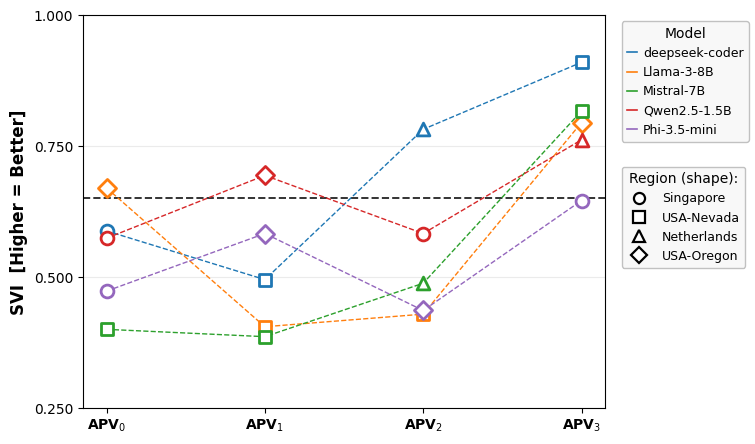
Figure 3: SVI as a holistic index, showing performance and sustainability trade-offs across prompts, models, and regional infrastructure.
Quantization Trade-Offs
Figure 4 presents the sensitivity of SVI to quantization depth for Phi-3.5-mini and Qwen2.5-1.5B under APV3. Higher-precision variants (unquantized, 8-bit) achieve superior SVI in fixed regions (e.g., Singapore for Phi-3.5-mini), implying that in these settings, coverage and stability gains from precision outweigh energy savings from aggressive quantization. However, SVI is critically modulated by region; for Qwen2.5-1.5B, 8-bit deployment in the lowest-carbon grid achieves the highest SVI, even compared to unquantized runs in higher-intensity grids.
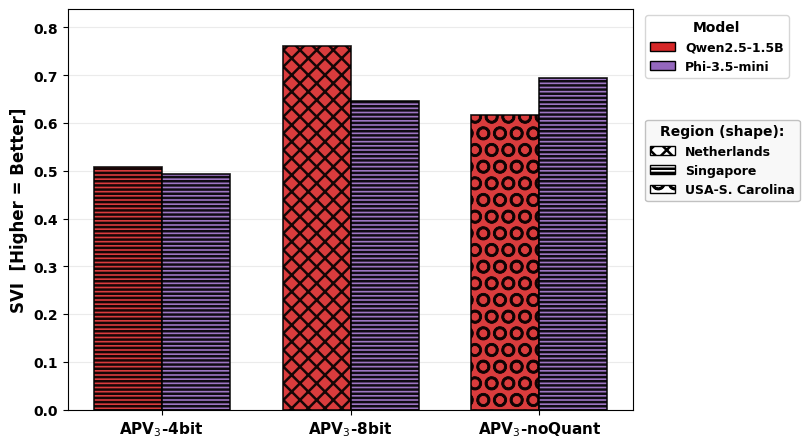
Figure 4: Quantization effects on SVI, illustrating model- and region-dependent sustainability–performance dynamics.
Coverage vs. Eco-Efficiency Prioritization
GFβ-based rankings show that model ordering is non-monotonic with respect to β and deployment context. SLMs optimized for maximal code coverage do not necessarily yield best-in-class sustainability; conversely, the most eco-efficient models may underperform on strict code coverage if not calibrated. This property enables explicit architectural negotiation for software architects: deployment pipelines can be tuned to reflect deployment priorities (coverage vs. ecological footprint) simply by adjusting β and controlling for anticipated regional workload placement.
Implications and Future Prospects
This study rigorously demonstrates that sustainable SLM inference for automated test generation is driven not by model size alone but chiefly by the triadic interplay of model quantization, prompt design, and carbon intensity of the execution environment. Strong empirical evidence is provided for a multidimensional ranking and selection approach, rather than simplistic parameter- or metric-based model filtering. For practitioners, the SVI and GFV30 indices support rational, priority-aware choice of SLM deployments in resource-constrained, sustainability-sensitive settings (including edge, privacy domains, or private cloud).
Theoretically, the results challenge the assumption that energy/resource trade-offs are linear in model parameterization or quantization; future work could extend these findings to alternate hardware (e.g., TPUs, ARM), cloud substrate, software regression testing, and compositional prompt workflows.
Conclusion
The empirical evaluation of prompt-driven SLM-based test script generation in (2604.02754) substantiates that neither model size nor emission metrics alone suffice for credible sustainability evaluation in automated software testing workflows. Only by analyzing the dynamic interactions among model, prompt, quantization, and regional deployment scenarios can software engineers, sustainability officers, and cloud architects meaningfully balance functional Quality-of-Service guarantees and sustainable operational footprints. The composite metrics developed in the study set a new methodological baseline for further sustainable AI engineering research.